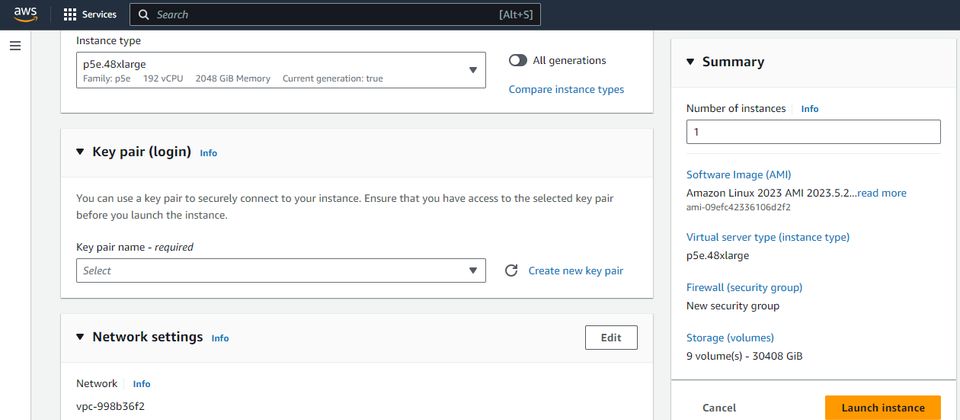
生成式AI、大語言模型這兩年暴紅,許多企業與組織均投入相關的應用開發,導致Nvidia Hopper架構資料中心GPU產品H100供不應求,企業除了自行採購、建置搭配這款GPU的伺服器,透過公有雲業者提供的GPU加速運算執行個體服務,也是一種管道,不過,直到去年下半、甚至到今年上半,三大公有雲的用戶才能在網頁管理主控臺,直接選取與建立搭配Nvidia H100 GPU的執行個體服務。
以AWS為例,他們營運的這類雲端運算服務Amazon EC2 P5,是在去年6月推出,提供一種執行個體組態p5.48xlarge,搭配8個Nvidia H100,每個GPU內建80 GB容量的HBM3記憶體;11月底他們預告將推出新的GPU加速運算執行個體服務,稱為Amazon EC2 P5e,搭配8個H200,每個GPU內建141 GB容量的HBM3e記憶體,單就GPU記憶體而言,容量增加80%,存取速度提升40%。


時隔9個多月之後,AWS宣布Amazon EC2 P5e上線,是第一家正式供應Nvidia H200 GPU配置的公有雲業者,目前僅開放美國東部(俄亥俄)的區域使用,可經由Amazon EC2用於機器學習的容量區塊定價模式進行訂購,即可使用名為p5e.48xlarge的執行個體組態。
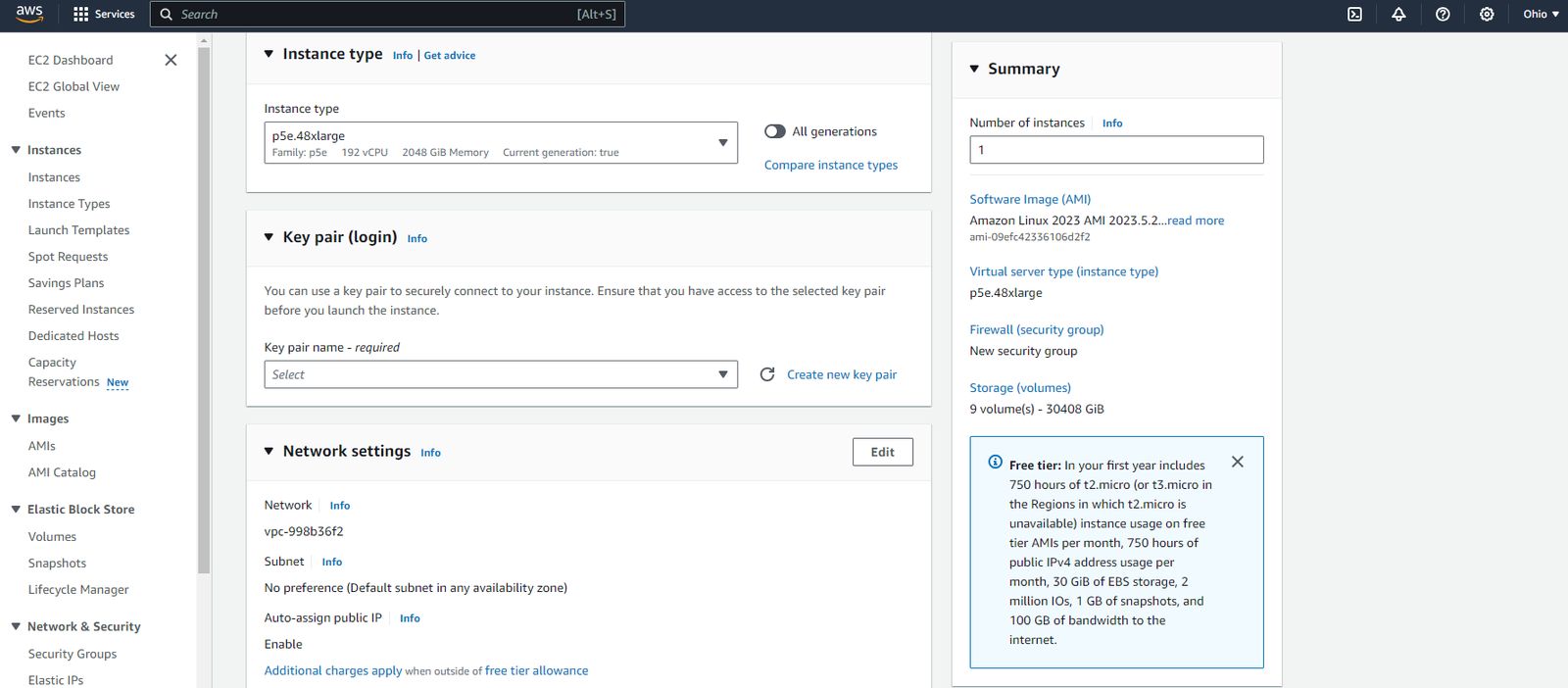
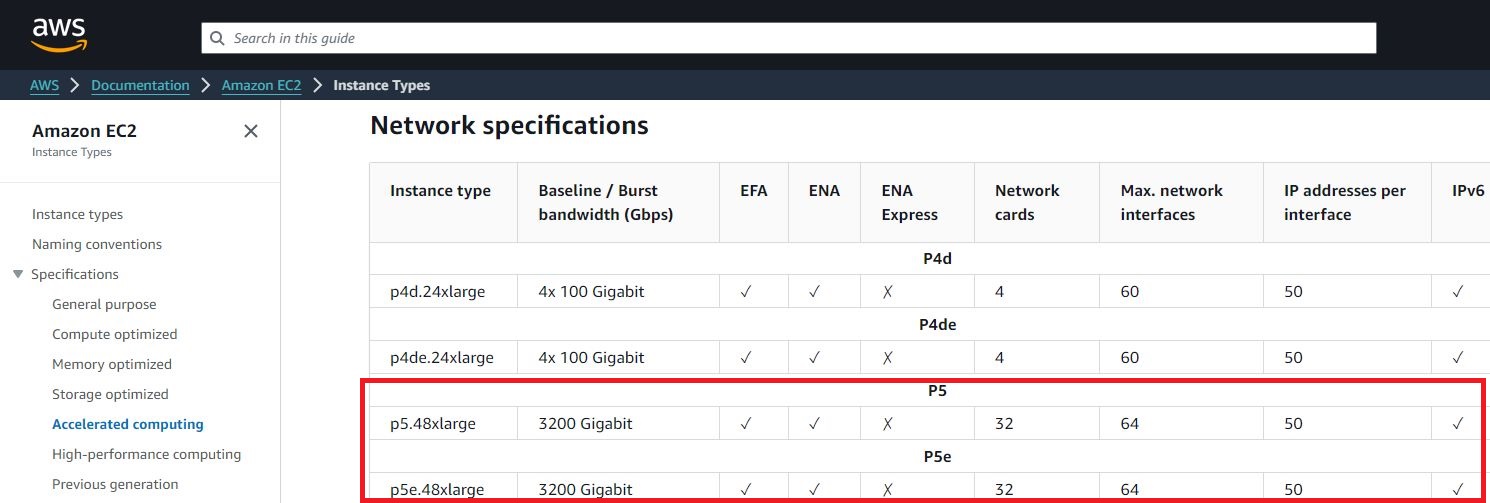
P5e採用8個Nvidia H200 GPU,總共能提供1128 GB的高頻寬記憶體,其他組態沿襲P5,仍是搭配AMD第三代EPYC處理器、2 TiB記憶體、30 TB NVMe儲存空間,以及匯聚頻寬為3200 Gbps的第二代EFA網路介面。
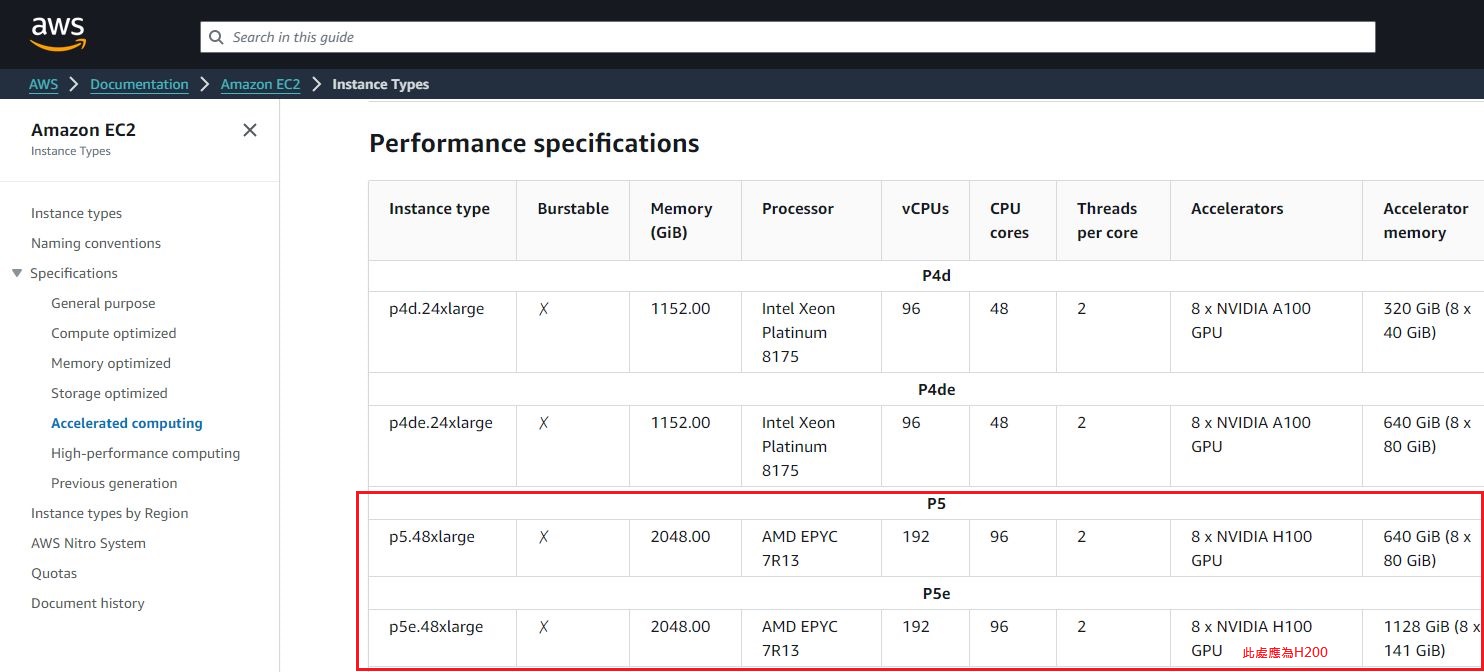
值得注意的是,網路存取頻寬的突破並非一蹴可幾,AWS在2020年11月推出的Nvidia A100 GPU執行個體服務P4d,當中搭配的EFA網卡,頻寬為400 Gbps,開始支援Nvidia GPUDirect RDMA技術,實現GPU之間的直接溝通,進而獲得較低的存取延遲、運算效能規模可橫向擴充的效益;到了2023年下半,AWS推出的Nvidia H100 GPU執行個體服務P5,開始搭配第二代EFA網路卡,頻寬可達到3200 Gbps,一口氣提升至8倍。
AWS也揭露P5e用於大語言模型推論的效能測試成果。若執行Llama 3.1-70B模型,相較於P5,P5e的吞吐量領先幅度為87.1%,成本節省40%;若執行Llama 3.1-405B模型,相較於設置兩個P5,使用單個P5e時,吞吐量領先幅度可望達到70%,成本節省69%。
在此同時,AWS也預告很快將推出p5e的網路最佳化配置變體,稱為P5en,在同樣都是搭配Nvidia H200 GPU之餘,主要差異會是採用訂製型英特爾第四代Xeon Scalable處理器,屆時將能提供PCIe 5.0介面,將CPU與GPU之間的I/O頻寬增加至4倍,並且進一步降低網路延遲,從而改善工作負載的執行效能。
產品資訊
AWS Amazon EC2 P5e
●原廠:AWS
●建議售價:用於機器學習的容量區塊定價為每小時43.26美元
●基礎運算規格:AMD第三代EPYC處理器(7R13)
●提供服務規模選擇與最大組態:p5e.48xlarge,192顆虛擬處理器、2048 GiB記憶體、8臺3.84 TB本機儲存、8張Nvidia H200 GPU、網路頻寬為3,200 Gbps,網路儲存:使用AWS區塊儲存服務EBS,存取頻寬為80 Gbps
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
熱門新聞

2026-02-02

2026-02-03

2026-02-04

2026-02-02

2026-02-04


2026-02-03

2026-02-05