圖片來源/SMART Modular Technologies
當前的伺服器運算平臺技術的發展,正陷入因記憶體架構而帶來的2大瓶頸中。
第一個瓶頸,是發生在伺服器的元件層次,由於DRAM記憶體傳輸通道頻寬的增長,已經趕不上CPU核心數的成長,導致隨著CPU核心數的不斷增加,每單位運算核心可用的記憶體頻寬反而日趨減少,使得記憶體存取效率不彰。
第二個瓶頸,則發生在資料中心的伺服器平臺應用層次,出現DRAM記憶體利用率難以提升,導致大量記憶體資源面臨低利用率的閒置窘境。
為了能夠克服這些瓶頸,促成以CXL(Compute Express Link)為代表的處理器記憶體互連技術,藉此實現跨處理器、跨裝置的共享記憶體池,不僅突破既有記憶體傳輸通道的制約,提高CPU可用的記憶體容量與頻寬,也能在CPU與周邊裝置之間,動態調整記憶體資源配置,提高伺服器的記憶體利用率。
伺服器的記憶體架構瓶頸
如同一開始提到的,發展CXL這類新一代共享記憶體池技術的目的,是為了解決兩大瓶頸,讓我們詳細看看為何會出現這些狀況。
記憶體頻寬瓶頸
過去10年以來,x86處理器的核心數提高了8到12倍,在2012年,單處理器最多不過8核心,到了2022年已增至96核心。但相對地,記憶體通道數量只從4個增加到8個與12個,僅僅提高2到3倍,遠遠跟不上處理器核心數的增長。
於是,這便出現了一個弔詭的情況:越新款、越多核心的處理器,平均每個核心所能獲得的記憶體頻寬,反而越來越低,形成了運算能力的瓶頸。
而處理器直連的記憶體通道數量,主要是由處理器的接腳(Pin)數量決定,過去10年以來,x86伺服器處理器的接腳數量固然也持續增加,從LGA2011、LGA3467、LGA4094/4189,到最新的LGA4677,雖然只增加2倍多,但已經接近實體極限,主機板已經沒有更多空間,可以布置更多的處理器接腳,以及更多的記憶體直連通道了。
這也意味著,在當前的伺服器組成架構下,已經沒有增加處理器記憶體直連通道的餘裕了。
記憶體利用率瓶頸
DRAM記憶體已成為大型資料中心的關鍵成本支出項目,舉例來說,微軟便曾表示,DRAM的成本,占了Azure資料中心的50%伺服器成本。
但尷尬的是,當前大型資料中心卻又存在伺服器記憶體利用率低的問題。例如,今年5月Carnegie Mellon大學與微軟發表學術論文《First-generation Memory Disaggregation for Cloud Platforms》,引述Google報告指出,該公司資料中心的DRAM利用率只有40%,而微軟Azure也表示,他們的資料中心內,當所有的處理器核心都配置給VM之後,仍有25%的DRAM資源未被配置,處於閒置狀態。但由於處理器核心已經耗盡,這些閒置DRAM也無法被使用,形同成本浪費。
因此,規模越大的資料中心,記憶體容量閒置所導致的成本浪費也越嚴重,對於Azure、Google這樣的雲端服務業者來說,數十%的記憶體容量閒置,幾乎等同於數億甚至十數億美元的損失。
然而,在現有的伺服器組成架構下,DRAM是與CPU直連,記憶體資源也被伺服器與CPU給綁定,每一臺伺服器形同於一座記憶體孤島,即便某臺伺服器有大量記憶體閒置,也無法配置給另一臺伺服器或其他周邊裝置使用。
這也就是說,當前伺服器的記憶體是靜態配置的,無法跨伺服器或跨裝置進行動態調配,因而在既有的伺服器記憶體架構下,不可能解決記憶體資源利用率過低的問題。
另一個大家面臨雪上加霜的狀況則是,隨著GPU、SmartNIC、DPU等運算加速裝置,在伺服器上的普遍應用,這些運算加速裝置各自都含有容量可觀的DRAM,因而伺服器整體記憶體資源無法充分利用的狀況,也日益嚴重。
共享記憶體池克服記憶體架構瓶頸
不管是元件層級的處理器記憶體頻寬受限,或平臺層級的記憶體容量利用率過低,想克服這些問題,答案都指向同樣的解決方案:基於處理器記憶體互連技術的共享記憶體池。
對於處理器記憶體頻寬受限問題,由於在當前的伺服器架構下,已經沒有增加處理器直連記憶體通道的空間,因此,解決辦法就是轉為透過PCIe或其他傳輸通道,來介接額外的記憶體裝置,從而為處理器提供額外的記憶體頻寬。
對於伺服器平臺記憶體利用率低的問題,解決辦法便是將記憶體從處理器「解構」出來,組成一個跨裝置、跨伺服器的「共享記憶體池」,從而動態地按需配置記憶體資源,減少浪費。
無論是要引進額外的記憶體傳輸通道與記憶體裝置,來擴展處理器記憶體頻寬,還是要將不同裝置、伺服器的記憶體互連組成共享記憶體池,需要的技術都是相同的,都需要透過低延遲、高頻寬的傳輸通道,讓不同裝置的處理器與記憶體互連,以快取一致性(cache coherent)方式存取共同的記憶體定址空間,因此這兩個需求也就合而為一,形成了當前的處理器記憶體互連技術。
%EF%BC%BB%E7%B6%B2%E9%A0%81%E5%85%A7%E6%96%87%E5%9C%961%EF%BC%BD.png)
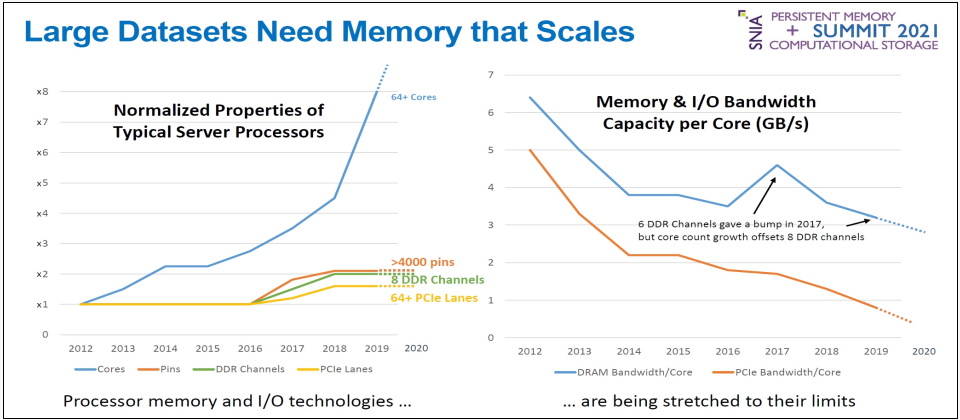
處理器面臨記憶體頻寬瓶頸的狀況日益嚴重
從上圖可以看出,自2012到2019年之間,處理器核心數提高了8倍,但記憶體頻寬只增加2倍,因此平均每個處理器核心所能分配到的記憶體頻寬,實際上是大幅下降。但處理器直連的記憶體通道數量已達物理上限,難以進一步增加,必須透過外部傳輸通道來介接記憶體,才能克服記憶體頻寬的瓶頸。圖片來源/SMART Modular Technologies
共享記憶體池技術的興起
過去7、8年來,已有一系列處理器記憶體互連技術先後問世,我們可追溯到IBM於2014年開始發展的CAPI,讓Power處理器與外部加速裝置互連、共享記憶體空間。而為了進一步發展與推廣CAPI,IBM又在2016年主導成立OpenCAPI聯盟。
同樣在2016這一年,業界也組成另外2個處理器記憶體互連技術聯盟:CCIX與Gen-Z,不過,這些技術聯盟都缺少了一家關鍵廠商的參與,那就是Intel。到了2019年,Intel終於投入這個領域,主導成立了CXL聯盟。
而能夠跨多個裝置、多臺伺服器的共享記憶體池存取,運作方式類似於多處理器間的NUMA記憶體存取架構,都是讓多個處理器共同存取位置分散、但定址統一的記憶體空間,且規模更大,也更分散,還涉及異質處理器間的互連(如CPU與GPU、FPGA等),因此,不適用於QPI、HyperTransport這類晶片間的互連技術。
為了避免開發全新傳輸介面帶來的成本與相容性問題,多數處理器記憶體互連技術,都選擇現成的PCIe傳輸技術為基礎,再結合一些增強功能。
以CXL、Gen-Z與CCIX等技術為例,它們都選擇PCIe 4.0或PCIe 5.0的實體層與電氣元件介面,來作為傳輸通道的基礎,進而提供快取一致性機制,以及增強的存取管理功能。
IBM早期推行的CAPI其實也是採用PCIe 4.0作為傳輸通道底層,但是,到了OpenCAPI之後,則改用NVLink 2.0的Bluelink 25G I/O通道,可提供較PCIe 4.0更高的效能。比較特別的是Gen-Z,還導入了50Gb乙太網路,用於跨機箱與機架的遠端記憶體互連。
透過處理器記憶體互連技術,將不同裝置的記憶體組成共享記憶體池,可以讓伺服器的記體體配置容量,超過主機板記憶體插槽的限制,因此,組成數十TB、數百TB容量的記憶體池,如今已經是可行的,建立PB等級的記憶體池也不是夢想,而且,還可以按需動態地配置這些記憶體給應用程式使用。
更進一步,單是共享記憶體池本身,也能構成了「階層式」的記憶體架構。由於共享記憶體池是由分散在不同裝置上的記憶體所構成,個別處理器存取這些記憶體的距離各有不同,因而存取延遲表現差異也很大。與CPU直連的DIMM記憶體,存取延遲不到100ns,最低甚至只有20ns。而透過PCIe串接的記憶體裝置,延遲便會達到350ns之譜。至於藉由乙太網路等外部網路通道連接的記憶體裝置,延遲則在800ns左右。
而這種階層式的記憶體環境,也將帶來嶄新的記憶體應用形態,用戶可視工作負載的性質(hot、warm、cold等),分配使用這些具備不同延遲性能的記憶體資源。
%EF%BC%BB%E7%B6%B2%E9%A0%81%E5%85%A7%E6%96%87%E5%9C%962%EF%BC%BD.png)
興起中的各種處理器記憶體互連技術
縱觀幾種主要的處理器記憶體互連技術,CXL、CCIX都是嫁接在PCIe上,讓外部的記憶體控制器,或是ASIC、FPGA等異質晶片與CPU直連,並藉此共享記憶體。Gen-Z除了同樣可透過PCIe讓CPU與周邊裝置互連記憶體以外,也能利用乙太網路遠端存取記憶體。圖片來源/SMART Modular Technologies
邁向全面資源池化的資料中心
透過處理器記憶體互連技術,可擺脫當前伺服器架構CPU記憶體頻寬限制,還能進一步解放記憶體資源為CPU綁定的束縛,實現能夠橫跨不同裝置的共享記憶體池。
而當伺服器的記憶體也「池」化了以後,也讓資料中心的基礎架構,朝向「全面資源池」化的發展,向前邁進了一大步。
過往透過伺服器虛擬化技術的幫忙,我們可以將資料中心的伺服器處理器運算資源轉化為「運算力池」;而藉由儲存虛擬化技術,也能把儲存裝置的儲存空間化為「儲存池」。到了現在,我們可用CXL等處理器記憶體直連技術,則能進一步將所有伺服器與周邊裝置的DRAM記憶體,也轉化為「記憶體池」,讓基礎架構資源實現全面動態配置的境界,無論在效能、成本,還是管理靈活性,都能得到莫大的助益。
%EF%BC%BB%E7%B6%B2%E9%A0%81%E5%85%A7%E6%96%87%E5%9C%963%EF%BC%BD%E5%85%B1%E4%BA%AB%E8%A8%98%E6%86%B6%E9%AB%94%E6%B1%A0%E7%9A%84%E9%9A%8E%E5%B1%A4%E5%BC%8F%E6%A7%8B%E9%80%A0.png)
共享記憶體池的階層式構造
處理器記憶體互連技術提供的共享記憶體池,是由不同裝置上的DRAM所組成,隨著傳輸距離與傳輸通道的差異,而有著不同的存取延遲表現,也形成了階層式的記憶體構造,其中,CPU直連的DIMM記憶體延遲最短,次之是透過PCIe介接的記憶體裝置,然後是透過外部網路介接的記憶體裝置。資料來源:iThome整理,2022年9月

熱門新聞

2026-02-02

2026-02-03

2026-02-04

2026-02-02

2026-02-04


2026-02-03

2026-02-05