iThome
在AI應用熱潮之下,作為運算能力源頭的GPU,成為最關鍵的基礎元件。因而GPU規格及運算能力的進展,也成為當前IT基礎設施發展的焦點。
但隨著AI規模擴展,GPU應用涉及的I/O資料傳輸架構,已成為影響AI效能的另一項關鍵要素,影響力不下於GPU本身運算能力的發展。
首先,GPU只是運算單元,在執行運算工作之前,必須先從儲存與網路單元載入資料,因而載入資料所經由的I/O傳輸通道效率,將直接影響GPU系統的整體效率。無論GPU運算能力如何強大,如果資料傳輸的I/O延遲過大或頻寬不足,顯然會極大地妨礙GPU運算能力的發揮。也就是說,GPU必須搭配高效能的I/O傳輸架構,才能充分發揮運算能力。
其次,儘管GPU的運算能力不斷進步,但面對AI應用所需的龐大運算能力需求,個別GPU很快就會難以負荷,往往必須以多GPU配置的運算節點或多臺GPU伺服器組成運算叢集,才能聚集出足夠的運算能力,這也連帶產生GPU之間的高速通信需求,必須透過高效率的傳輸架構連結多個GPU、成為一個巨大的GPU資源池,這同樣也帶來高效能I/O架構的需求。
而隨著AI應用的持續深入與擴大發展,也增強搭配GPU的高效能I/O架構的要求。以往AI應用涉及的資料集規模相對有限,給I/O架構帶來的傳輸壓力也有限,一般標準的伺服器I/O架構大致還能應付。但到了今日,生成式AI技術運用的資料集規模動輒數十TB起跳,下一代大語言模型的資料量還遠高於此,這已遠遠超過一般伺服器I/O架構的承載能力,必須為GPU發展新的高效能I/O架構,才能滿足新一代AI應用的處理能力要求。
作為GPU領域領導者的Nvidia(輝達),除了GPU本身的發展,過去十多年來,他們也陸續推出一系列專屬高速I/O技術,包括GPUDirect、NVLink、NVSwitch等,搭配自身GPU。
而這一系列高效能I/O技術,也成為Nvidia在GPU之外的另一項「隱形優勢」——Nvidia不僅在GPU本身的效能規格領先群倫,同時還有完整的高效能I/O技術與其配套,兩者相輔相成。相較下,其他GPU競爭廠商,便缺乏這樣完整的配套I/O技術,也制約GPU效能的發揮。
GPUDirect的基本框架
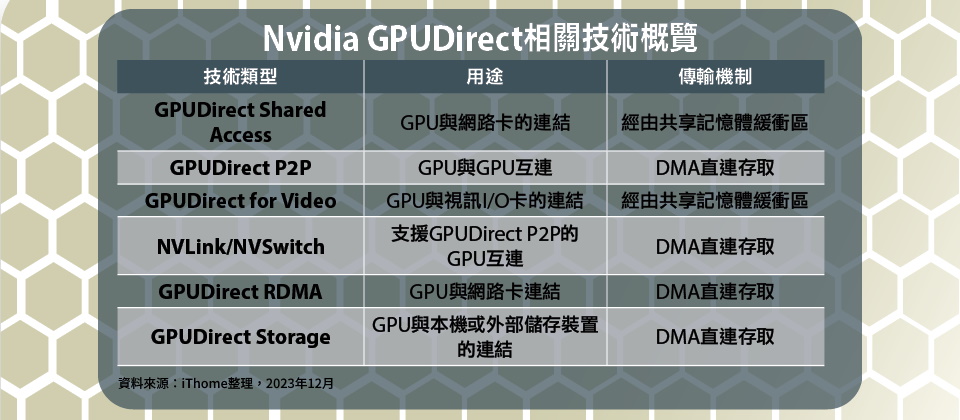
現在Nvidia將他們長期發展的多種GPUDirect技術,整合至Magnum IO軟體技術套件,包含GPUDirect Storage、GPUDirect Peer to Peer(P2P)、GPUDirect RDMA,以及GPUDirect for Video等4種應用架構,簡而言之,可分為下列兩大類型:
● GPU與GPU直連:讓GPU與GPU之間透過PCIe或專屬傳輸介面直連通信,適用於多GPU應用環境,GPUDirect P2P屬於這種應用類型。
● GPU與非GPU直連:讓非GPU的周邊裝置,如網路卡、多媒體視訊處理卡或儲存裝置,透過Nvidia的API與GPU直連通訊,包括:GPUDirect Storage,GPUDirect RDMA、GPUDirect for Video,都屬於這種應用類型。
無論哪一種類型,目的都是減少傳輸延遲、提高GPU相關應用的I/O效能。
而這一系列GPUDirect技術,其實,是經過十多年的逐步演化、發展而來。最早可追溯到2010年推出的GPUDirect Shared Access,最晚近的則是2019年推出的GPUDirect Storage,應用環境從單一主機的內部通信,擴展到多主機之間,以及與外部裝置間的連接通信,還衍生出NVLink與NVSwitch等2項GPU互連傳輸技術。
接下來我們便以發表時間的先後順序,簡要介紹GPUDirect相關技術的發展與演進。
GPUDirect Shared Access
在2010年,隨CUDA 3.1運算架構一同導入的GPUDirect Shared Access,有時也被大家稱為GPUDirect 1.0,或是GPUDirect Shared Memory,存在目的在於,讓Nvidia GPU驅動程式與第3方PCIe裝置(主要是網路卡)驅動程式,共享主機系統記憶體中固定的一塊資料緩衝區,減少兩者間不必要的資料緩衝複製作業。
在沒有GPUDirect幫忙的情況下,GPU與網路卡在主機記憶體區域中各自有獨立的資料緩衝區,當GPU要將資料傳送給網路卡時,必須先將資料複製到自身的緩衝區暫存,再複製到網路卡的緩衝區,才能交由網路卡存取。而在有了GPUDirect之後,GPU與網路卡可共用同個資料緩衝區,只需1次複製就能完成資料傳輸,因而也大幅降低了資料傳輸的延遲。
GPUDirect技術的起點:GPUDirect Shared Access
.png)
被稱為GPUDirect 1.0的GPUDirect Shared Access,目的是改善GPU與網路卡之間的傳輸效率。在傳統架構下,GPU與網路卡在主機系統記憶體中,各自有一塊獨立的緩衝區,所以必須經由兩次複製作業,才能完成GPU與網路卡之間的資料傳輸。而透過GPUDirect則能讓兩者共用同一塊固定的緩衝區,因而將資料傳輸所需的複製作業減少一半。圖片來源/Nvidia
GPUDirect P2P
Nvidia在2010年推出的GPUDirect Shared Access,是用於單一主機內部GPU與非GPU裝置之間的資料傳輸。接著在2011年,他們推出單一主機內部GPU與GPU直連資料傳輸的GPUDirect P2P,搭配同時推出的CUDA 4.0架構。
在傳統的傳輸架構下,GPU與GPU之間的資料傳輸,必須要透過主機端系統記憶體緩衝區的中介,來源端GPU先將資料複製到主機系統記憶體,放在固定的共享緩衝區暫存,之後再將資料複製到目標端GPU的記憶體。
透過GPUDirect P2P,可以讓單一主機內的GPU與GPU之間,利用非統一記憶體存取架構(NUMA)的方式,將另一GPU的記憶體映射為當前GPU的虛擬記憶體空間,藉此讓多個GPU之間透過PCIe介面直接存取彼此的顯示記憶體,因而在GPU之間傳輸資料時,省略將資料複製到主機系統記憶體緩衝區的中介,也無須與主機CPU互動,能加速多GPU運算環境的資料傳輸作業,顯著減少存取延遲。
為GPU之間提供直連的GPUDirect P2P
.png)
在傳統架構下,GPU與GPU之間的資料傳輸,須經由主機CPU與系統記憶體的中介。而透過GPUDirect P2P技術,則能讓GPU與GPU之間,以直接記憶體存取技術(DMA),繞開CPU與系統記憶體,直接存取彼此的記憶體,提供直連傳輸應用。圖片來源/VMware
GPUDirect for Video
Nvidia在2011年除了推出GPUDirect P2P,也發表GPUDirect for Video,可讓視訊I/O介面卡與GPU直連傳輸,基本上,我們可視為將GPUDirect Shared Access技術,應用到視訊I/O介面卡(如視訊捕捉卡等)的衍生版本。
過去沒有GPUDirect for Video技術時,視訊I/O介面卡的視訊資料須經過2次記憶體複製,才能傳送給GPU處理,首先將視訊資料複製到主機系統記憶體的視訊I/O介面卡緩衝區,再複製到主機系統記憶體的GPU緩衝區,所以,視訊I/O介面卡與GPU資料傳輸不同步,整個作業約有10個畫面(frame)延遲。
而利用GPUDirect for Video,則能讓視訊I/O介面卡與GPU共用固定的系統記憶體緩衝區,只需一次複製就能完成視訊傳輸,讓視訊I/O介面卡與GPU同步地進行資料傳輸作業,不僅能減少延遲,也降低了主機CPU的負荷。
GPUDirect RDMA
2013年配合CUDA 5.0登場,Nvidia推出GPUDirect RDMA(簡稱GDR),是GPUDirect技術發展歷程的一大關鍵,因為他們首次將直接記憶體存取技術(Direct Memory Access,DMA)導入GPU的I/O架構中,從而為GPU與非GPU之間的資料傳輸效率,帶來根本性的提升。
先前推出的幾種用於GPU與非GPU之間的GPUDirect技術,無論GPUDirect Shared Access或是GPUDirect for Video,基本上,都只是傳統基於主機記憶體緩衝區複製架構的改進,資料傳輸路徑仍須經過主機CPU與系統記憶體中介,只是減少了複製次數而已。而GPUDirect RDMA則能透過直接記憶體存取,完全繞開CPU與系統記憶體,讓GPU與網路卡直接傳輸資料。
關於GPUDirect RDMA,顧名思義,屬於「遠端」直接記憶體存取(Remote Direct Memory Access)。一般而言,RDMA可讓遠端網路卡直接將資料寫入接收端網路卡位於系統記憶體緩衝區,無須經由主機作業系統與CPU的中介,因而能極大減少延遲與主機CPU負荷,並提高資料吞吐率,以目前來看,InfiniBand與RoCE乙太網路卡是最常見的RDMA網路應用。
Nvidia的GPUDirect RDMA架構,則是RDMA技術應用到GPU I/O上的版本,透過Nvidia提供的GDR API,將GPU裝置的記憶體,映射到PCIe匯流排上,從而讓PCIe的其他裝置如網路卡,可繞過主機CPU與系統記憶體,以點對點方式直接存取GPU裝置的記憶體。
GPUDirect RDMA與GPUDirect Shared Access,同樣都是用於改善GPU與非GPU裝置間的傳輸效率,但是,GPUDirect Shared Access仍然需要經由主機系統記憶體的中介,需要執行一次資料複製的動作;而GPUDirect RDMA則能繞開主機系統記憶體,透過RDMA架構直接存取GPU記憶體,提供「零複製(Zero Copy)」的能力,效能有了根本性的提高,所以,有了GPUDirect RDMA,也就不再需要GPUDirect Shared Access。
但在GPUDirect RDMA,CPU仍參與其中作業,雖然資料傳輸是在GPU記憶體與網路卡之間直接進行,不經CPU,但仍需由CPU負責傳輸路徑控制、傳輸佇列管理,以及傳輸前後的控制。
為了將這些傳輸控制作業從CPU卸載出來,Nvidia在2017年推出搭配CUDA 8.0的GPUDirect RDMA Async技術,可讓GPU執行傳輸路徑控制,以及傳輸流程控制,CPU只需負責傳輸佇列與傳輸前後的控制,進一步減輕了CPU的負載,提高了整體效率。
比起傳統的I/O傳輸架構,GPUDirect RDMA可將存取的延遲減少將近一半,而GPUDirect RDMA Async又能進一步改善,再將延遲減少近40%。
高效率的GPU與網路卡直連架構GPUDirect RDMA
.png)
在傳統架構下,GPU與網路卡等非GPU裝置之間的資料傳輸作業,都須經由主機CPU與系統記憶體的中介,既增加了延遲,傳輸頻寬也受限。而透過GPUDirect RDMA,則能讓GPU與網路卡直連存取,無須經由主機CPU與系統記憶體。圖片來源/VMware
NVLink與NVSwitch
GPUDirect技術一開始是利用PCIe作為傳輸通道,但很快就面臨PCIe傳輸通道頻寬不足的窘境,成為應用上的效能瓶頸。
特別是對於多個GPU相互直連應用的GPUDirect P2P來說,2010年代初期當時主流的PCIe 3.0早已不敷所需,即便是新一代的PCIe 4.0,I/O頻寬也略嫌不足,促使Nvidia決定打造自身專屬的GPU直連傳輸通道技術,而其成果便是2016年發表的NVLink技術。
NVLink是Nvidia專屬的GPU點對點直連匯流排技術,可突破PCIe傳輸瓶頸,單是第1代的NVLink,就能提供最大160 GB/s總頻寬,相當於PCIe 3.0 x16(32 GB/s)的5倍以上,為GPUDirect P2P提供更充足的傳輸頻寬。
到2022年為止,NVLink已經發展4個世代,總傳輸頻寬從160 GB/s逐步提高,達到900 GB/s,每個GPU允許的最大連結鏈路數量也從4個,提高到18個。
NVLink相當程度解決GPU相互直連的傳輸頻寬需求,可以將最多8個GPU連結組成一個GPU運算陣列,Nvidia在2016年推出的DGX-1整合應用設備,核心便是透過NVLink互連的8個SXM外形Tesla P100 GPU。
然而,如果用戶有更高的運算能力需求,需要連結超過8個以上的GPU,那麼NVLink便難以滿足需求。儘管NVLink能提供相當充裕的傳輸頻寬,但若要在GPU晶片整合更多傳輸鏈路,將大幅增加晶片的面積與複雜性。
為此Nvidia所提出的變通方式,是透過額外的NVSwitch交換器晶片,來連結2組NVLink,從而構成最大規模達到16個GPU的運算陣列,
Nvidia在2018年推出的DGX-2整合應用設備率先應用NVSwitch的連接技術,透過12顆NVSwitch晶片整合16個SXM外形的Tesla V100 GPU。
目前NVSwitch已發展到第3代,支援的GPU直連規模維持在16個,但GPU直連傳輸頻寬已從300 GB/s,提高到900 GB/s,匯聚的總頻寬也提高3倍。
擺脫PCIe的制肘,Nvidia發展能提供高效率GPU互連通道的NVLink
.png)
最初的GPUDirect P2P使用PCIe作為GPU互連的傳輸通道,但也受到PCIe效能的制肘。而NVLink則為GPU提供了專屬的高速互連通道,傳輸頻寬是PCIe數倍以上。上圖為Dell A100 GPU伺服器的架構圖解,可見到每個A100 GPU雖仍透過PCIe介面與CPU連結,但GPU與GPU另外透過NVLink互連,因而GPU之間的資料傳輸,可免去PCIe帶來的頻寬限制。圖片來源/Dell
GPUDirect Storage
隨著AI應用持續的深入與擴大,AI的資料集的規模也不斷擴大,從儲存裝置將資料載入GPU的所需時間越來越長。在許多情況下,AI資料集的規模已超過GPU伺服器本身能容納的範圍,而須搭配外部儲存設備才能容納。如此一來,也使得從本地端儲存裝置到GPU之間的資料傳輸,以及從外部儲存設備到GPU伺服器之間的資料傳輸,成為另一個制約GPU應用的效能瓶頸所在。
顯然的,無論GPU本身的效能如何提高,若從儲存設備載入資料的速度過慢,將會大大拖累系統整體的運算處理速度。這也促使Nvidia在2019年推出GPUDirect Storage(簡稱GDS)架構,用於加快從儲存設備載入資料、傳送到GPU伺服器的速度。
在傳統傳輸架構下,要從GPU伺服器的本地端儲存裝置,將資料傳送給GPU處理,資料會先經由GPU伺服器的PCIe交換器,複製到伺服器主機CPU記憶體的回彈緩衝區(Bounce Buffer),再複製到GPU記憶體中;而要從外部的儲存設備將資料傳送到GPU,則會經由GPU伺服器上面的網路卡,以及PCIe交換器,先將資料複製到伺服器主機CPU記憶體的回彈緩衝區,再複製到GPU記憶體。整個傳輸過程需要經過多次複製,不僅增加延遲,資料傳輸率也受到GPU與CPU之間的傳輸通道頻寬限制。
而GPUDirect Storage則能在儲存設備與GPU之間建立直連傳輸通道,繞開GPU伺服器主機CPU,讓儲存設備利用直接記憶體存取(DMA)技術,直接透過PCIe匯流排將資料寫入GPU記憶體。
由於GPUDirect Storage省略將資料複製到主機記憶體(回彈緩衝區)過程,因而能顯著減少延遲,減輕主機CPU的負荷,同時,傳輸效能也不會受到系統記憶體與GPU記憶體的通道頻寬限制,而能大幅提高傳輸速率。
有了GPUDirect Storage之後,外部儲存設備可透過網路卡、以RDMA方式,直接將資料傳到GPU記憶體,傳輸速率只受到網路卡與PCIe介面頻寬的限制,因而可以透過匯聚多個高容量網路埠與PCIe通道,提供較傳統傳輸架構高出數倍的傳輸頻寬。
而內部儲存裝置(NVMe SSD)也能透過GPUDirect Storage架構,以DMA方式經由主機的PCIe交換器將資料直接寫入GPU記憶體,可利用RAID匯聚多臺儲存裝置進行資料傳輸作業,大幅提高傳輸率。
為GPU與儲存裝置之間的存取提供直連傳輸的GPUDirect Storage
.png)
在傳統架構下,GPU無論是要從本機的NVMe SSD載入資料,還是要透過網路從外部儲存設備載入資料,都須經由主機CPU與系統記憶體中的回彈緩衝區中介,因而存在著延遲較大,且傳輸頻寬受限的問題。而透過GPUDirect Storage,則能讓本機SSD與外部儲存裝置繞過主機CPU與系統記憶體,與GPU直連傳輸資料,從而大幅減少了延遲,並提供更高的傳輸頻寬。圖片來源/Nvidia
GPUDirect的部署
GPUDirect架構的部署,實際上,必須透過軟硬體兩方面的配合。在軟體方面,要安裝Nvidia的一系列GPUDirect相關驅動程式,現在這些驅動程式都被整合在Magnum IO軟體套件。
在硬體方面,首先,要啟用特定的GPUDirect功能,GPU必須支援對應的CUDA架構版本,例如,GPUDirect RDMA只需CUDA 5.0以上即可使用,而效率更高的GPUDirect RDMA Async則需CUDA 8.0以上才能支援,所以,較老舊的GPU卡將無法使用這項功能。
而在周邊裝置方面,也須搭配硬體廠商提供的GPUDirect支援元件。
以GPUDirect RDMA為例,要啟用這套跨遠端的直連傳輸架構,除了必須透過Nvidia的GDR API進行,還需要網路卡廠商的軟體支援。
舉例來說,源於Mellanox的InfiniBand網路卡,便透過3項元件支援GPUDirect RDMA:首先,是Nvidia在GDR API所提供的「nvidia」驅動程式;其次,是Mellanox的「mlx*」驅動程式,用於管理InfiniBand網路卡,並提供直接讀寫點對點PCIe裝置的介面,稱作Mellanox PeerDirect;第3,則是Mellanox的「nv_peer_mem」核心模組,作為Nvidia GDR驅動程式與Mellanox PeerDirect的連接介面,以便讓GPU與InfiniBand網路卡直接傳輸記憶體資料。
GPUDirect Storage也是類似的情況,如果我們要啟用這項I/O直連傳輸架構,需要在GPU伺服器主機的作業系統安裝Nvidia的GDS軟體,同時,SSD與外部儲存設備的控制器,也必須支援GDS架構,才能構成GDS直連傳輸。
GPUDirect成為GPU I/O加速架構的共通標準
經過十多年來的研發與應用之後,Nvidia如今的GPUDirect直連傳輸架構,已經發展得相當全面,能夠涵蓋從單機內部直連到多機互連環境,以及GPU對非GPU的直連、GPU對GPU的直連、伺服器與儲存設備的直連,應用形式相當豐富,大致對應了當前GPU應用涉及的主要I/O連結型態。
挾著在GPU市佔幾近壟斷性的優勢,Nvidia的GPUDirect形同GPU I/O架構的標準,影響力也逐漸擴大。
在GPUDirect這一系列的技術中,最早的GPUDirect Shared Access已經由GPUDirect RDMA取代,而且,基本上,此技術已成為高效能應用取向的高階網路卡必備功能,藉此提供搭配GPU的直連存取能力,包括Mellanox(已屬於Nvidia旗下)、Chelsio、Broadcom與Intel的高階乙太網路卡產品,以及Mellanox的InfiniBand HCA卡,都支援GPUDirect RDMA。就連AWS也加入行列,他們的EC2雲端執行個體的網路卡EFA(Elastic Fabric Adapter),也在2020年開始支援GPUDirect RDMA。
而用於高效能GPUDirect P2P互連應用的NVLink,以及NVSwitch介面,也已經是Dell、HPE、Lenovo、Supermicro等各大伺服器廠商支援、旗下高階GPU伺服器產品的標準配備。
針對視訊處理應用的GPUDirect for Video,目前有Active Silion、AJA、BitFlow等十多家解決方案廠商支援。
而用於搭配儲存設備的GPUDirect Storage,相關支援應用這兩年也有爆發性增長,幾乎所有一線儲存大廠如Dell、HPE、IBM、Hitachi、NetApp,以及重要新創儲存廠商如VAST、Weka等,都先後支援了這套直連傳輸架構。
總結這些發展歷程與市場熱烈支持的風潮,我們可以說:當前涉及資料中心GPU的各種軟硬體應用,都已經離不開GPUDirect。
-JPG.jpg)
熱門新聞
")
2026-02-09
")

2026-02-06

2026-02-06

2026-02-06


2026-02-06

2026-02-06