無論AI或其他類型的高效能運算應用,所使用的資料集規模都在持續暴漲,也給GPU的I/O傳輸架構帶來更大的壓力,連帶也促使Nvidia專門用於搭配GPU的高效率儲存I/O架構——GPUDirect Storage(GDS),相關應用在這2年迅速增長,幾乎成為儲存廠商支援GPU應用的標準架構。
AI資料暴漲催生GPU高速I/O需求
隨著生成式AI技術開始廣泛應用,不僅給GPU的運算能力帶來更大的挑戰,也形成更龐大的I/O傳輸需求。
以當前最熱門的大型語言模型為例,GPT-1的訓練資料量不過5GB, GPT-2便增加到40GB,GPT-3更大幅攀升到45TB,而在訓練過程中,光是儲存1次訓練狀態的檢查點,就需要2.45 TB。
這樣龐大的資料集,已遠遠超過GPU伺服器的系統記憶體與GPU記憶體容量,必須多次從儲存裝置中讀取資料載入記憶體,才能讓GPU完成訓練工作。更進一步,多數GPU伺服器本身的儲存裝置,也無法容納這樣龐大的資料集,因而必須搭配外部儲存設備,來存放AI訓練資料集。
這也意味著,在AI訓練過程中,將會在本地端/外部儲存裝置與GPU之間,產生龐大的資料傳輸流量,也讓從儲存裝置到GPU之間的I/O傳輸效率,成為影響整個AI應用效率的關鍵環節。
顯然的,無論GPU的運算能力再強大,如果I/O傳輸效率低落,在運算過程中,將會耗費大量時間在等待儲存裝置的載入資料,而無法充分發揮運算能力。
因而GPU必須搭配一套高效率的儲存I/O架構,才能因應AI應用日益龐大的資料集傳輸處理需求,這也促使Nvidia推出GPUDirect Storage架構。
GPU系統的I/O瓶頸(以DGX-2為例)
.png)
在傳統存取架構下,CPU與GPU之間的PCIe傳輸頻寬,是GPU I/O路徑的瓶頸所在。以Nvidia的DGX-2為例,從上圖可以看出,在傳統傳輸路徑下,CPU到PCIe交換器的頻寬,是其中最小的。DGX-2的GPU連接PCIe交換器的頻寬可達到100GB/s,內接的NVMe SSD則能匯聚出53 GB/s頻寬,對外也能透過8組網路埠匯聚出超過90 GB/s的頻寬,但CPU到PCIe交換器之間的頻寬只有50GB/s,因而成為效能瓶頸。圖片來源/Nvidia
GPUDirect Storage的價值
GPUDirect Storage架構的目的,是讓儲存裝置與GPU之間透過直接記憶體存取(DMA)方式傳輸資料,免去繞經主機CPU與系統記憶體帶來的種種問題。
如同多數周邊裝置,GPU與儲存裝置之間的資料傳輸,傳統上都必須透過主機CPU與系統記憶體的中介,儲存裝置的資料經由RAID卡(內部儲存裝置)或網路卡(外部儲存設備)送到主機的PCIe匯流排,經由主機CPU複製到系統記憶體的回彈緩衝區(Bounce Buffer)暫存,再傳送到GPU的記憶體。但這樣的資料傳輸程序,也帶來下列3個問題:
首先,是造成較大的延遲,資料路經必須經過多個環節的處理,才能載入GPU的記憶體。
其次,是傳輸頻寬受限,無論儲存裝置擁有多高的傳輸效能,將資料載入GPU時,都會受到從CPU到GPU之間的PCIe連接頻寬制約。以Nvidia的DGX-2平臺為例,本身的NVMe SSD可透過RAID 0匯聚出53GB/s的傳輸頻寬,也能透過匯聚8個InfiniBand/100GbE網路埠,獲得80到100 GB/s以上的外部傳輸頻寬,但是將資料從本機NVMe SSD或外部儲存設備傳送到GPU時,都會被CPU到GPU之間的PCIe頻寬給綁住,最多只有48到50 GB/s,無法充分發揮儲存設備的傳輸能力。
第3,主機CPU必須參與管理整個資料傳輸作業,導致CPU相當大的負荷。
而有了GPUDirect Storage,則能讓儲存裝置與GPU之間以DMA或RDMA方式直連存取,一舉解決前述3個問題。
首先,儲存裝置的資料只需經由PCIe交換器,就能載入GPU記憶體,大幅減少了延遲。
其二,資料傳輸無須經由CPU,因而也不會受到CPU與GPU之間的頻寬所限制,可大幅提高資料傳輸頻寬。
其三,由於CPU不參與資料傳輸作業,大幅減輕CPU負荷。
Nvidia宣稱,透過GPUDirect Storage可獲得2到8倍的資料傳輸頻寬提升,並降低3.8倍的存取延遲,而多家儲存廠商實測,也證實了這樣的效能提升表現。
當GPUDirect Storage應用於內接儲存裝置時,美光以其9400 NVMe SSD的實測顯示,比起傳統I/O路徑,啟用GPUDirect Storage可提升6.4倍的傳輸率,以及7.3倍的回應速度。
而GPUDirect Storage應用於外部儲存設備時,VAST Data提出的實測數據也顯示,VAST Data儲存平臺透過8個InfiniBand埠將資料載入DGX-2時,採用傳統傳輸路徑只能達到33GB/s頻寬,CPU利用率則高達99%;而改用GPUDirect Storage傳輸資料,將能獲得超過94 GB/s的持續傳輸頻寬,CPU利用率則只有15%,效益極為顯著。
GPUDirect Storage的基本概念
.png)
在運作方式上,GPUDirect Storage便是繞過CPU與記憶體的中介,讓儲存裝置與GPU透過直接記憶體存取(DMA)互連,從而減少延遲,並提高傳輸頻寬。
在左邊的傳統傳輸架構中,從NVMe SSD傳給GPU的資料,需要經過PCIe交換器、CPU與系統記憶體的中介,一共需要4個步驟才能完成。而在GPUDirect Storage架構下,NVMe SSD只須經由PCIe交換器就能直接將資料傳給GPU,只需2個步驟就能完成,大幅減少了延遲。圖片來源/Micron
GPUDirect Storage的部署運作
要啟用GPUDirect Storage,必須同時有軟硬體的配合。
在軟體方面,GPU伺服器必須安裝Nvidia的GDS軟體套件,目前這是屬於CUDA SDK套件一部分。在安裝GDS軟體套件之前,還須安裝Nvidia的MLNX_OFED與nvidia-fs.ko這2個軟體元件。前述軟體元件目前都只支援Ubuntu、RHEL、Rocky Linux等Linux系統,所以,GPUDirect Storage目前只能在這些作業系統平臺運作。
在硬體方面,要啟用GPUDirect Storage,則需要GPU與儲存裝置等兩方面的相容與支援。
在GPU方面,只有較新款的資料中心等級與Quadro桌上型等級GPU平臺,可以運行GPUDirect Storage(詳見Nvidia網站公布的清單)。
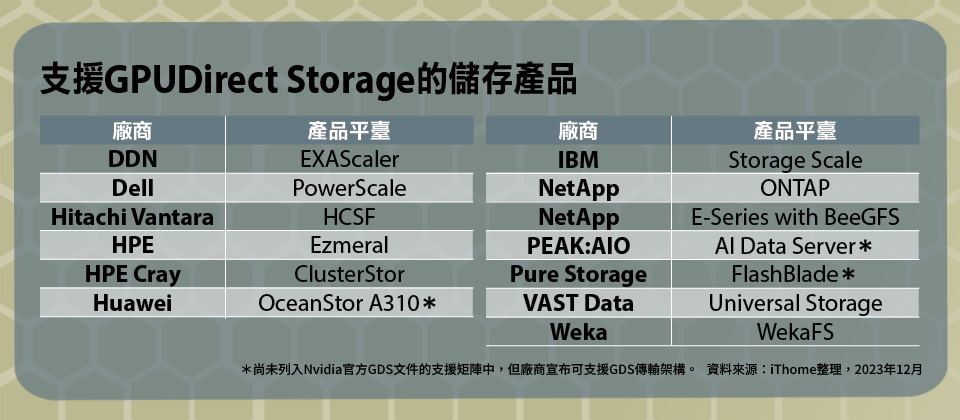
而在儲存裝置方面,目前已有超過15家儲存廠商,宣布支援GPUDirect Storage架構,產品包含外部儲存設備與內接SSD裝置,外部儲存裝置是以特定的分散式檔案系統或修改的NFS來與GPU平臺連接,內接SSD則是透過修改的EXT4檔案系統。我們接下來便將介紹這些儲存廠商與產品。
支援GPUDirect Storage的儲存產品
一方面,高效能運算所面對的資料量持續增加,確實日益需要高效率儲存I/O架構才能因應;另一方面,GPUDirect Storage提升I/O傳輸效能的表現,的確十分突出;最後,Nvidia在整個GPU應用領域當中,具有市場壟斷地位,也促使GPUDirect Storage幾乎成為當前儲存設備搭配GPU的傳輸架構標準,受到主流儲存廠商支援。
在Nvidia的GPUDirect Storage網頁相關公告,目前特別列出14家支援GPUDirect Storage開發測試的儲存廠商,包括DDN、Dell、HPE、Hitachi、IBM、Kioxia、Liqid、Micron、NetApp、Samsung.ScaleFlux、Supermicro、VAST Data、Weka。其中,有DDN、Dell、HPE、Hitachi Vantara、IBM與NetApp,都是傳統一線儲存設備大廠,同時,還有VAST Data、Weka等新興分散式儲存平臺廠商,以及Kioxia、Samsung與ScaleFlux等NVMe SSD儲存裝置供應商。
而在Nvidia的GPUDirect Storage操作文件的系統支援矩陣列表,也列出支援GPUDirect Storage的儲存平臺,包括:HPE Ezmeral、HPE Cray ClusterStor、NetApp ONTAP與搭配BeeGFS的EF平臺、IBM Spectrum Scale(已更名為Storage Scale)、DDN EXAScaler、VAST Data的Universal Storage、Weka的WekaFS,Dell的PowerScale,Hitachi Vantara的HCSF等。大致涵蓋當前市場上常見的分散式儲存平臺與NAS平臺。
除了前述列入Nvidia支援清單中的平臺外,還有其他廠商發布支援GPUDirect Storage的消息,包括Pure Storage的FlashBlade,華為的OceanStor A310,以及PEAK:AIO的軟體定義NAS平臺等。
其中DDN、Dell、IBM、華為、VAST Data、Weka、PEAK:AIO等廠商,近期也紛紛發布旗下儲存產品運行GPUDirect Storage的實測結果,根據他們得到的數據,透過GPUDirect Storage直連傳輸,可以讓外部儲存設備以80、90 GB/s以上的頻寬,向GPU伺服器傳輸資料。
目前奪得最高GPUDirect Storage傳輸速度紀錄的廠商,應該是PEAK:AIO,他們透過HPE的ProLiant DL380 Gen11伺服器來運行PEAK:AIO軟體平臺,並以200GbE/HDR埠分別透過RDMA NFS與NVMe-oF協定連接Nvidia DGX A100 GPU平臺時,單一節點便擁有162 GB/s與202 GB/s傳輸率。第二名是IBM運行Spectrum Scale平臺(現已更名為Storage Scale)的ESS3500,單一節點擁有126 GB/s傳輸率,第三名則是DDN AI400X2(運行EXAScaler平臺),以119 GB/s緊追其後。
上述都是屬於外部儲存平臺,支援的是遠端GPUDirect Storage應用。而在內接儲存裝置方面,目前Micron的9400 NVMeSSD,以及ScaleFlux的CSD 2000運算儲存裝置,都可支援內接形式的GPUDirect Storage直連傳輸應用。
典型的GPUDirect Storage應用架構
.png)
這是NetApp的GPUDirect Storage實測架構,為了匯聚更大的傳輸吞吐率,一共使用了4臺AFF A800儲存陣列,透過100/200GbE網路連接2臺DGX A100與2臺Nvidia DGX-1伺服器。每臺A800儲存陣列,DGX A100與DGX-1都有400Gb的對外頻寬。在使用2組、4組、8組A800控制器的情況下,透過GPUDirect Storage分別可得到45.6 GB/s、86.5 GB/s與171 GB/s的傳輸率,顯示能夠此架構可以隨著節點數量而提供線性增長的效能。圖片來源/NetApp
儲存設備支援AI應用的必備架構
自Nvidia於2019年中發表GPUDirect Storage技術架構後,2020年起開始獲得儲存廠商的支援,接著在2021到2023年之間,支援的廠商迅速增加,尤其是所有主要的一線儲存設備大廠,都已經支援這套傳輸架構。
到了現在,我們甚至可以這樣認為,考慮到Nvidia GPU在AI應用中的關鍵地位,以及GPUDirect Storage所提供的效能表現,任何想要支援AI應用的儲存設備,都必須支援這套傳輸架構,才能具備足夠的競爭力。
熱門新聞

2026-02-06
")
2026-02-09
")

2026-02-06
")
2026-02-09

2026-02-06

2026-02-06