iThome
相較於10年前或20年前,如今災難復原(Disaster Recovery,DR)的角色,可說益發重要。
今日天災人禍對企業IT造成的衝擊有增無減,威脅IT系統運作、導致服務中斷的各式人為與非人為災害持續增加,也對企業IT架構韌性帶來空前考驗,讓企業營運持續性面臨越來越大的風險。
而災難復原解決方案則能在災害發生時,利用預先備妥的備援用站點,接替陷入癱瘓的主站點,讓企業IT環境繼續維持服務,因而也是強化企業數位韌性的關鍵環節。
但問題在於,要實現能確保業務持續性的災難復原環境,是企業IT基礎設施建置最具挑戰性的工作之一,涉及一系列複雜的規畫與設定工作,包括資料的遠端複製傳輸、服務的切換轉移,以及遠端備援站點的建置與維運等,尤其是最後一點:遠端備援站點的建置與運作,須投入可觀的人力與成本,門檻相當高。因此,過去通常只有資本雄厚、且對業務持續性特別敏感的特定行業,才有能力建置完善的災難復原環境。
至於大多數用戶,往往只能遷就選擇較低層次的災難復原架構,被迫忍受較長時間業務中斷,與更大的資料損失。
所幸過去10年來,架構在公有雲平臺上、以租賃與託管服務形式提供的雲端災難復原服務(Disaster Recovery as a Service,DRaaS)逐漸成熟,幫助用戶克服建置災難復原環境最大的障礙——建置與管理遠端備援站點的沉重負擔,大幅降低災難復原的成本與建置門檻,為企業提供「用的起」的災難復原。
雲端災難復原服務的基本概念
關於雲端災難復原服務(DRaaS),可說是雲端災難復原(Cloud Disaster Recovery,Cloud DR)的「服務化」(as a Services)解決方案,而雲端災難復原則是IT災難復原應用的一種類型。
如同傳統的IT災難復原應用,雲端災難復原也是由資料遠端複製機制,以及備援站點等兩大基本部分組成,能定期將資料從主站點傳輸到備援站點保存,一旦主站點因災害而癱瘓時,會改由備援站點接手主站點的服務。差別在於,雲端災難復原是將備援站點建立在公有雲平臺上,藉此讓用戶免除建置與管理實體備援站點的負擔。
就概念來說,任何以雲端環境來作為備援站點的災難復原應用,就可算是雲端化的災難復原。
而雲端災難復原服務,則是雲端災難復原的「服務化」,也就是將整個災難復原應用涉及的資料遠端複製、站點切換與復原管理,以及備援站點的建置與運作,都整合為統一的解決方案,並以按用量付費的「服務」型式,提供給用戶訂閱。
雲端災難復原服務的優勢
在歷史悠久的災難復原應用領域,DRaaS問世不過10年出頭,但挾著雲端架構的先天優勢(成本、靈活性、擴展性、可靠性),以及不受地理環境限制的特性,成長的速度非常快。
首先,如同其他雲端服務,DRaaS也採用按實際用量按月計費的租賃模式,這解決傳統災難復原應用中,備援站點的維運負擔問題。儘管備援站點設備很少實際派上用場,多數時間都處於閒置待命狀態,卻會持續帶來維運成本。
而透過公有雲平臺的DRaaS服務,用戶無須建置與擁有備援站點的設備,只有實際使用到備援站點時,才須依用量向公有雲服務商支付費用。
嚴格來說,這其實是將用戶端原本一次性的備援站點投資成本,轉為向公有雲服務商定期支付租賃費用的經常性營運支出,長期來看,成本效益未必如一開始看來那樣顯著,但關鍵在於成本支出的「靈活性」,透過DRaaS的實用實付計價模式,用戶可依據主站點的工作負載與自身業務變化,隨時調整備援站點配置與組態,這是用戶自建備援站點難以具備的特性。
其次,建構在公有雲平臺大型資料中心的DRaaS,能提供用戶本地端資料中心難以企及的高擴展能力與高可靠性,可以近乎無止盡地為用戶提供資源,並透過大規模的分散式架構,提供極高度的可靠性。
最後,公有雲服務商,特別是大型公有雲服務商,一個重要標誌便是覆蓋於廣泛地理區域範圍的多座資料中心,這不僅便於對不同地區的用戶提供服務,也有利於透過跨多個區域的備援架構提高服務可靠性。而這個特性也為DRaaS帶來不受地理環境限制的服務能力,原則上,用戶可透過DRaaS將備援站點設立在任何地方,遠離用戶自身的位置,這也為備援站點提供了額外保護,降低同時受到災難影響的機率。
雲端災難復原服務的興起
出乎我們的意料,目前幾乎所有市調機構都十分看好DRaaS市場的發展,舉例來說,市調機構Verified Market Research認為,全球DRaaS市場規模在2023年已達139億美元,預期將以27.2%年複合成長率,在2030年成長到744億美元。MarketsandMarkets則認為,DRaaS市場規模在2023年有107億美元規模,預估以19.8%的年複合成長率,在2028年可達到265億美元。Grand View Rearch的也指出,DRaaS在2022年已有106億美元市場規模,到2030年將以平均27.2%年複合成長率持續提升。類似的觀點還有Golbal Market InSights,評估DRaaS市場在2022年已達115億美元。
而這樣的市場規模,已能與傳統的備份與還原領域等量齊觀。以2023年全球備份與還原市場規模來說,市調研究機構KBV估計為129億美元,另一機構The Business Research評估為135億美元。
但備份與還原市場是歷經30年以上時間的累積,才達到現在的銷售規模;DRaaS只花了10年就追上,這不僅能看出DRaaS領域的成長速度驚人,也顯示用戶非常快就接受這項嶄新的服務。
公有雲災難復原服務的供應商
當公有雲運算與儲存服務於2000年代中期逐步成熟後,在2010年代初期便出現第一批DRaaS產品。例如著名的CloudEndure服務,便是在2012年問世。VMware也在2013年推出vCloud Air Disaster Recovery服務。
到了2014到2015年前後,市場上已有超過200家DRaaS相關供應商,初步形成了完整的生態系,
而主要的大型公有雲平臺廠商,也在2015年以後陸續投入DRaaS領域,其中最早的是微軟,於2015年便發表Azure Site Recovery雲端災難復原服務。至於AWS與Google Cloud,腳步相對慢了許多,AWS是在2019年併購CloudEndure,從而擁有自身的DRaaS產品。Google Cloud則是在2022年,推出自身的Cloud Backup and Disaster Recovery 服務。
到了今日,DRaaS市場雖然歷經10年市場競爭,以及廠商與產品整併,供應商仍有增無減,重要供應商至少有三十多家,其中稱得上第一線的,有AWS、微軟、VMware(已併入Broadcom旗下)、11:11 Systems(先前曾併購iland)、Infrascale、IBM等,值得注意的供應商,還有Acronis、Arcserve、Axcient、Carbonite、Cloudian、Cohesity、Commvault、Druva、Datto、Databarracks、Nutanix、Quorum、RapidScale、Recovery Point、Sungard、Tierpoint、Unitrends等。
這些廠商中,我們可以注意到超過一半都是出身備份、備援等資料保護領域,它們原本就以備份、備援為主要業務,隨著雲端環境的風行,將產品轉為雲端服務型式,也是很自然的發展。
另外還有一些廠商,本身並不直接提供DRaaS服務,但產品被應用於DRaaS服務中,算是這個領域的外圍廠商,如Tintri、Veeam等便屬於這種情況。
雲端災難復原服務的選擇
儘管DRaaS領域存在著數百家供應商,但彼此的定位與服務能力有著許多差距,我們歸納出5點,作為評估基準。
資料中心位置與距離
大多數DRaaS服務商都能提供跨國服務,但關鍵在於,DRaaS服務商雲端資料中心的實體位置,與用戶位置之間的距離。若距離太近,有同時受到大型災害影響的風險;但若距離太遠,一旦切換由雲端備援站點接手服務時,將會顯著增加用戶端存取延遲,導致服務品質下降。所以,有意導入DRaaS的用戶,必須仔細評估服務商站點距離與延遲需求,來決定最合適的DRaaS站點位置。
可靠性
這原本是雲端服務的先天優勢之一,但即便是雲端大型資料中心,還是會出現停機、服務中斷的意外,對於DRaaS這類「救命用」的服務來說,當用戶需要使用DRaaS來復原、卻遭遇雲端資料中心停機、服務無法使用的情況,便會導致災難性的後果。
舉例來說,Arcserve的StorageCraft DRaaS服務,在2022年3月間曾發生長達2周以上的服務能力降級事故,影響範圍遍及北美與澳洲的服務區域。
所以,有意導入DRaaS的用戶,不能預設DRaaS站點必定可用,而需把雲端站點也存在著不可用的風險納入考量,並審慎評估DRaaS服務商的SLA條款。
擴展性
這點也是雲端服務的先天優勢,不過,對於DRaaS服務來說,如果用戶端站點的設備具有較特殊的規格配置,須注意DRaaS服務商提供的備援站點運算,以及儲存裝置規格(即備援用執行個體與VM規格),能否對應用戶端站點規格,以確保備援站具備接手主站點工作的能力。
安全性與法規遵循
雲端資料中心同樣有遭到入侵與攻擊的風險,進而影響DRaaS這類雲端服務的可用性。原則上,雲端服務商承擔了保障雲端站點資料安全,以及服務可靠性的責任,不過,對於從用戶端到雲端資料中心的資料傳輸與存取,須由雲端服務商提供傳輸加密,以及存取權限管制功能,做為基本的保障。
另外,對於一些受到監管的行業來說(金融、醫療等),資料中心管理運作必須符合特定法規的要求,連帶地,作為備援站點的DRaaS服務,也需要具備符合這些法規要求的認證。
備援能力層級
當前DRaaS服務都能透過非同步遠端複製,以及預先配置的虛擬伺服器,達到最短小時到數分鐘等級的還原點目標(RPO),以及最快小時到分鐘等級的還原時間點目標(RTO),也就是一般所說的「暖」(Warm)備援能力。
但用戶對於業務持續運作(Business Continuity)如果有更高的要求,需要數分鐘或秒等級的RPO與RTO,甚至是完全不損失資料(RPO為0)、且服務完全不中斷(RTO為0)的備援能力,則需要搭配更高層級的遠端複製技術,例如,連續性的非同步複製,甚至是遠端同步複製技術、或遠端鏡像技術,同時還要採取與本地端站點平行運作、同步存取的遠端站點配置才能實現,但目前大多數DRaaS服務商,都不提供這種「熱(Hot)」備援等級的能力。
雲端災難復原的限制
儘管DRaaS擁有許多優勢,但也存在一系列限制,有些時候傳統災難復原架構反而更適合用戶。
首先,DRaaS完全依賴跨遠端網路傳輸才能運作,若用戶環境存在無法保證網路品質的邊緣站點,或是用戶與DRaaS站點間涉及跨國的遠距離傳輸、網路品質存在許多變數時,將會影響DRaaS服務的有效性。
其次,是資料遷移的成本,要利用DRaaS建立備援站點,需要將用戶端資料中心的資料,複製遷移到DRaaS站點,若用戶端資料中心規模較大,擁有數百甚至上千臺伺服器,則複製遷移工作不僅費時費力,可能還很昂貴。
第3,是安全性與隱私疑慮。如同其他雲端服務,使用DRaaS服務等同於將資料放置在用戶自身管理之外,始終有安全性與隱私風險。
最後,是面臨特定供應商綑綁的疑慮,一旦用戶選擇使用特定DRaaS服務,並將資料遷移到DRaaS站點,就很難再切換到其他服務商,而會遭到該服務商給鎖定。所以,一種折衷的方法,是混合使用DRaaS與傳統災難復原,藉此兼顧DRaaS的彈性與成本優勢,但又不致完全被DRaaS服務商綁住。
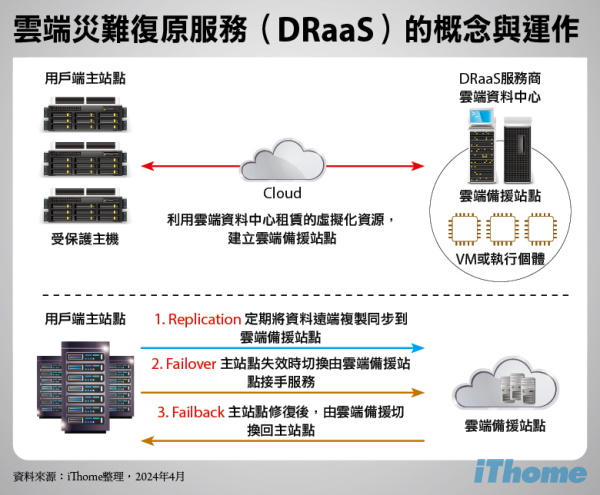
雲端災難復原服務(DRaaS)的概念與運作
DRaaS是雲端災難復原的「服務化」(as a Services)解決方案,將資料遠端複製、站點切換與復原管理,以及備援站點建置與運作,整合為統一的解決方案,以按用量付費的「服務」型式提供給用戶。
用戶利用DRaaS服務商提供的資源,建立雲端上的備援站點,並在主站點失效時,由雲端站點接替服務,運作方式與傳統災難復原相似,差別在於用戶不實際擁有雲端備援站點的設備,而只是租賃設備使用權,並依用量定期付費。
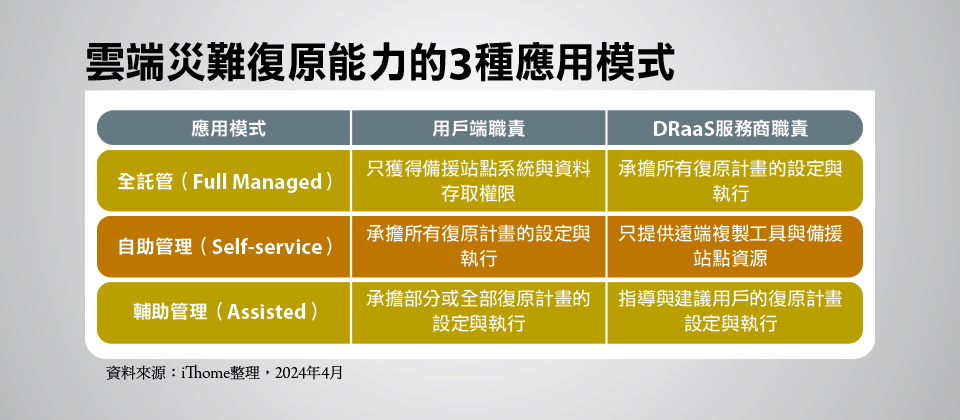
雲端災難復原能力的3種應用模式
依DRaaS服務商與用戶間參與災難復原計畫的程度,DRaaS可以分為3種應用模式,缺乏人力與技術能力的用戶適合全託管模式;若用戶的技術能力充分、或擁有較敏感的應用、不適合委託第3方,可選擇自助管理模式;輔助管理模式則介於前2者之間。


熱門新聞

2026-02-06
")
2026-02-09
")

2026-02-06
")
2026-02-09

2026-02-06

2026-02-06