DDN
隨著AI應用的興起,成為推動當前IT基礎設施發展的主要動力,儲存領域也不例外,為了便利AI應用環境的部署,近年來也出現專門搭配AI應用的整合式儲存套件,進而逐漸形成新的產品類型。
更進一步來說,這類AI應用整合儲存套件,幾乎等同於依循Nvidia架構的儲存套件。
一般來說,只要具備高效能、高擴展能力與高可靠性的儲存設備,都能扮演支援AI運算平臺的儲存服務角色,就邏輯來說,搭配與整合Nvidia架構並不是AI儲存設備的必要需求,但現實中卻不得不然。
一來,Nvidia在GPU市場擁有壟斷性地位,以支援AI應用為目的的儲存設備,必然得將搭配Nvidia GPU運算平臺,列為優先需求。
二來,Nvidia為其GPU應用涉及的I/O資料傳輸與儲存架構,制定了相對完善的技術框架與認證標準,因而要為Nvidia GPU運算環境提供完整的儲存服務,就必須依循Nvidia制定的I/O與儲存應用架構。
換句話說,在Nvidia佔據主導權的AI運算領域,要扮演好AI儲存服務的角色,儲存設備必須遵循Nvidia制定的規則與標準。於是,這也造成「AI儲存設備」幾乎等同「與Nvidia整合的儲存設備」的現狀。
克服AI應用環境複雜化的問題
隨著AI應用持續深入與擴大,AI資料集的規模也不斷擴大,許多情況下,已超過GPU伺服器本身能容納的範圍,而須搭配外部儲存設備才能容納。
如此一來,也造成AI應用基礎設施的複雜化,不再只是單純的GPU伺服器或GPU運算叢集,而是包含GPU運算單元,外部儲存單元,以及網路設備在內的複雜基礎設施環境,同時也形成兩個新問題。
首先,是外部儲存設備與GPU之間的資料傳輸效率問題。如果從儲存設備載入資料的速度過慢,將會大大拖累整體的處理速度,成為制約GPU應用的效能瓶頸。
其次,是外部儲存設備與GPU伺服器之間的建置與整合問題。為了滿足效能與擴展能力需求,為AI環境提供儲存服務的儲存設備,對於效能規格、網路連接與系統管理,都有一系列要求,從最初的採購評估、到系統安裝建置,以及安裝後的測試與調整,都有許多困難需要解決。用戶往往必須花費相當龐大的時間與心力,才能完成AI基礎設施環境的建置。
IDC這個月初剛發布的白皮書「Scaling AI Initiatives Responsibly: The Critical Role of an Intelligent Data Infrastructure」(由NetApp贊助),根據他們的 AI基礎設施應用調查結果顯示,導致AI應用失利、未能達到期望目標的原因中,有20%是基礎設施導致的資料存取無力(inability),另有接近20%是IT基礎設施的複雜性造成影響。
而這也顯示,AI應用涉及的儲存設備資料存取,以及基礎設施整體的複雜性,是影響AI應用成敗的關鍵因素。
Nvidia針對這兩個問題,都已提出解決對策。
針對外部儲存設備與GPU之間的資料傳輸效率,Nvidia提出GPUDirect Storage(簡稱GDS)架構,用於加快從儲存設備載入資料到GPU伺服器的速度。
而針對外部儲存設備與GPU伺服器之間的建置與整合,Nvidia提出DGX BasePOD與DGX SuperPOD等兩種整合架構,可以大幅簡化與加速AI應用基礎設施環境的部署。
整合套件簡化AI應用環境部署
自Nvidia於2019年提出GPUDirect Storage架構後,逐漸成為GPU應用領域的儲存傳輸標準之一,目前支援的儲存平臺包括:HPE Ezmeral、HPE Cray ClusterStor、NetApp ONTAP與搭配BeeGFS的EF平臺、IBM Spectrum Scale(已更名為Storage Scale)、DDN EXAScaler、VAST Data的Universal Storage、Weka的WekaFS,Dell的PowerScale,Hitachi Vantara的HCSF等,大致涵蓋當前市場常見的分散式儲存平臺與NAS平臺。
至於DGX BasePOD與DGX SuperPOD,由於推出時間相對較短,都是在2022年後期才發表,但目前已獲得不少廠商支援。
DGX SuperPOD
SuperPOD是Nvidia提供,由一系列既定規格設備組成、立即可用(turnkey solution)的GPU基礎設施解決方案,包含DGX伺服器(B200、H100或A100)、Nvidia網路設備與管理軟體,經過認證的第3方儲存設備,再加上安裝與支援服務,整個解決方案套件經過預先驗證,能提供保證的效能,可最大限度地簡化用戶端的部署程序。
目前獲得SuperPOD認證的第3方儲存設備一共有6款,包括DDN的A3I儲存伺服器系列中的AI400X,Dell的PowerScale儲存伺服器,IBM的Storage Scale System(SSS)儲存伺服器(先前的ESS系列),NetApp基於E系列儲存陣列與BeeGFS檔案系統構成的儲存系統,VAST Data的VAST Data Platform,以及WEKA的WEKApod。
DGX BasePOD
相較於由Nvidia直接提供、由既定規格設備組成的SuperPOD,BasePOD是由Nvidia認證的第3方儲存廠商推動,且規格更為靈活的GPU基礎設施參考架構(reference architectures),同樣包括Nvidia的DGX伺服器、網路設備、管理軟體,再加上經認證的第3方儲存設備,用戶可參考這套架構,依需求客製化調整配置規格。
目前獲得BasePOD認證的第3方儲存設備,包括Pure Storage基於FlashBlade儲存設備的AIRI架構,DDN的A3I儲存伺服器,Dell的PowerScale儲存伺服器,IBM的Storage Scale System,NetApp的ONTAP AI整合解決方案(NetApp AIPod),VAST Data的VAST Data Platform,以及WEKA的WEKA Data Platform,一共7款。
AI應用架構的基準
如同前面提過的,AI儲存環境的建構,原則上並非必須採用Nvidia的規範與架構不可。但考慮到Nvidia在GPU領域市占與技術的領導地位,以支援AI應用為訴求的儲存設備,若不支援Nvidia的規範與架構,便會陷入缺乏競爭力的窘境。
Nvidia的GPUDirect Storage傳輸架構,已經是AI應用不可或缺的標準傳輸架構之一。類似的,DGX BasePOD與DGX SuperPOD這兩種整合架構的推廣,雖然還在起步階段,但可預期未來也將成為AI儲存的標準框架。
符合BasePOD認證的Pure Storage AIRI架構
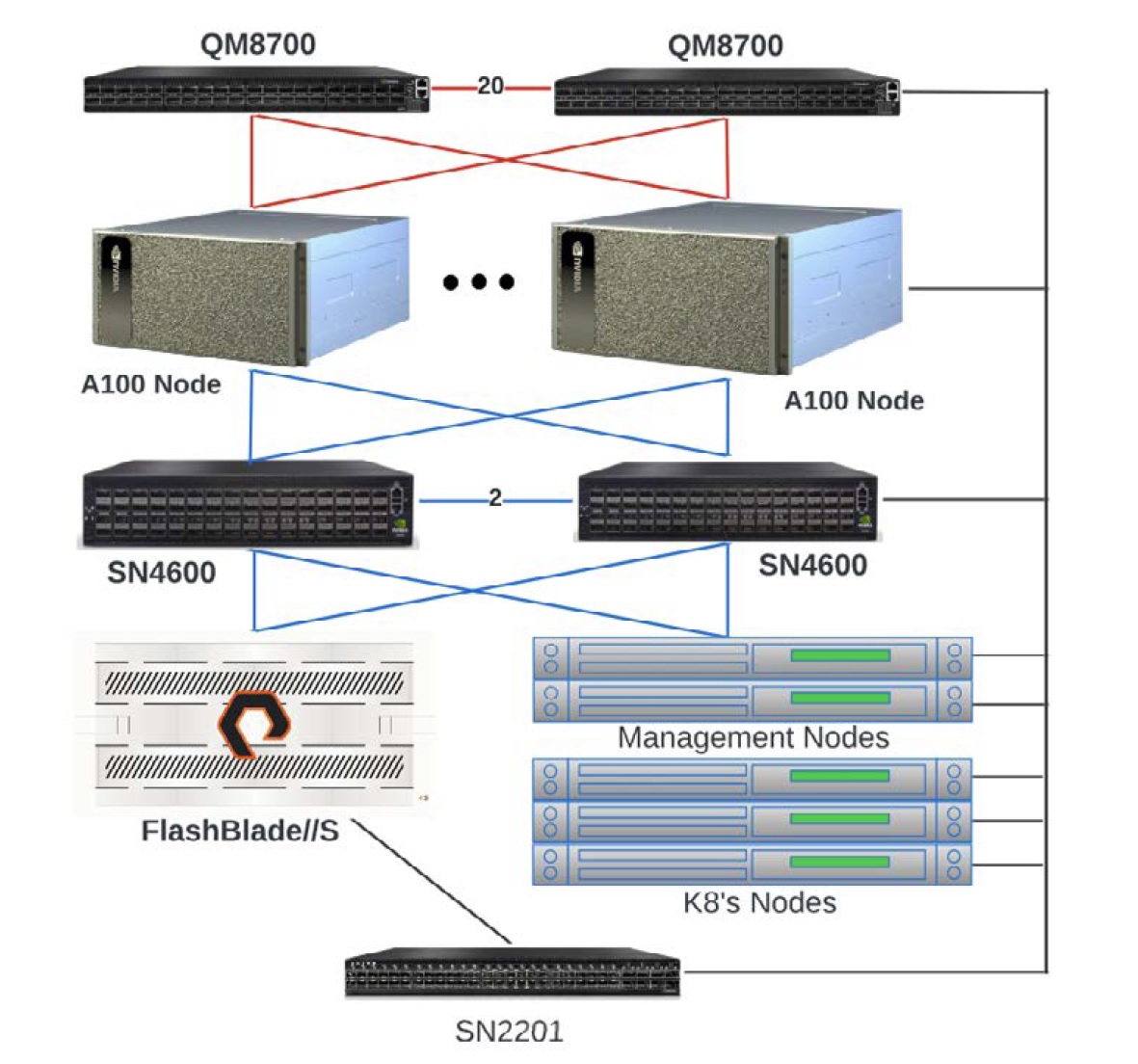
BasePOD的組成,包含DGX H100或A100伺服器,Pure Storage的FlashBlade刀鋒式儲存伺服器、管理節點、InfiniBand與乙太網路交換器等元件。
@資料來源:Pure Storage
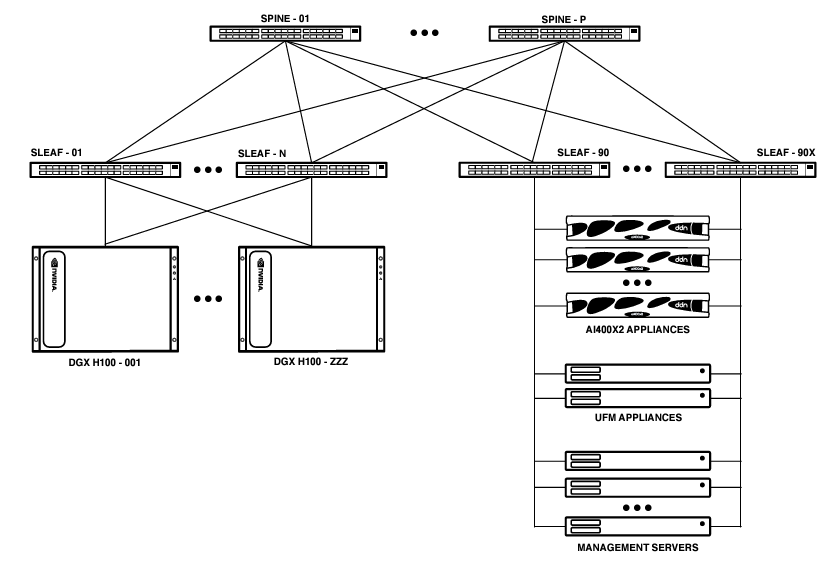
搭配DDN儲存設備的SuperPOD架構
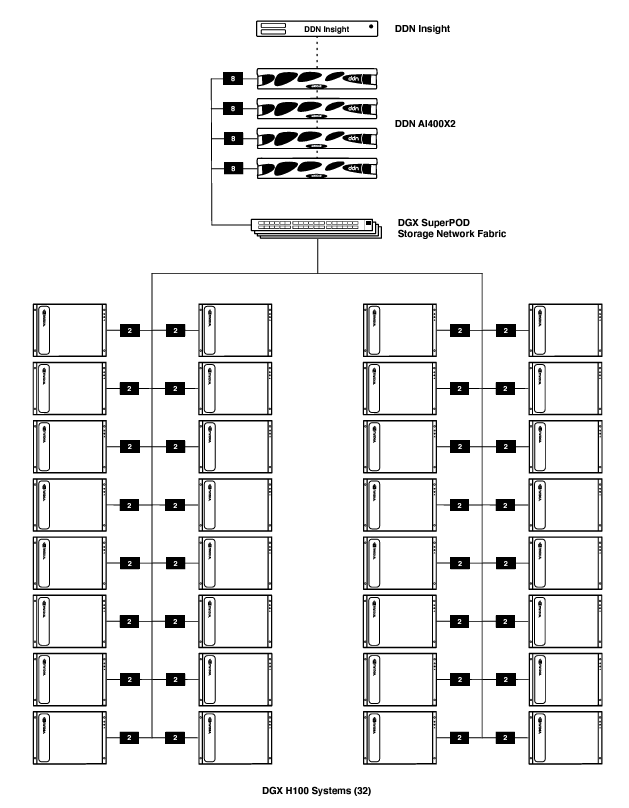
由DDN A3I儲存伺服器與DGX H100伺服器、InfiniBand交換器、管理伺服器等元件組成,可包含4到16臺AI400X2儲存伺服器,以及32到128臺H100伺服器。
@資料來源:DDN
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
")
2026-02-09
")
2026-02-09

2026-02-09