自從作為伺服器的I/O介面骨幹的PCIe,於4、5年前全面邁入PCIe 4.0世代後,緩解了長期以來伺服器I/O架構的不均衡問題。儘管目前PCIe 4.0已能滿足絕大多數周邊裝置的傳輸需求,但AI應用興起,以及GPU配置的普及,又帶來更大的資料傳輸流量要求,進而也促使PCIe 5.0進入普及階段,以及新一代PCIe 6.0規格的發展,同時也在PCIe之外,催生出GPU專用的超高速傳輸介面規格,這也讓伺服器內部I/O架構,有了大不同於以往的面貌。
PCIe 5.0為下一世代需求做好準備
在當前的伺服器I/O架構中,PCIe可說是最基礎的I/O介面,幾乎所有周邊裝置或其他I/O介面,都是直接或間接透過PCIe的介接,來與運算核心連結。這也意味著,PCIe介面規格的更新,對伺服器整個I/O架構的發展,也是牽一髮而動全身,勢必會影響所有周邊裝置與其他I/O介面的發展。
過去兩年來,PCIe介面的發展,正處於PCIe 4.0到5.0的轉換過渡期。事實上,PCIe 4.0普及的時間還不過數年時間,2017年規格制定完成,2020到2021年間才為主機平臺與周邊裝置全面支援。然而短短2、3年後,主機平臺便開始轉向支援PCIe 5.0。不過,從PCIe 4.0向5.0的過渡,其中的意涵並不同於幾年前從PCIe 3.0到4.0的交替。
當初是因為PCI-SIG組織的PCIe 4.0規格制定延宕,以及Intel平臺對PCIe 4.0的支援過晚,才導致主流規格在PCIe 3.0停滯過久,成為伺服器I/O架構的瓶頸,不僅影響到NVMe介面的大規模應用、SSD效能的提升,以及多GPU協調運作的效率,最終還促使Nvidia自行發展GPU專用傳輸介面。
而就今日的應用情境來說,由於GPU的直連傳輸已轉向採用專用介面,不再依靠PCIe,對於其餘的伺服器I/O傳輸應用,PCIe 4.0仍能滿足絕大多數的需求,只有一些要求極端傳輸效能的應用或周邊,才實際需要PCIe 5.0的頻寬,包括400Gb等級以上的網路卡,要求10GB/s等級以上傳輸速度的高階SSD,以及發展中的CXL共享記憶體技術等。
所以先前從PCIe 3.0到4.0的升級,是「滯後」的升級,目的是要「追趕」實際需求;而現在從PCIe 4.0到5.0的升級,可算是「提前」的升級,「預先」為日後的需求做好準備,以免重蹈過晚替換PCIe 3.0的覆轍。
PCIe 5.0時代正式來臨
PCI-SIG在2019年5月正式發布PCIe 5.0規格後,第一批支援PCIe 5.0的主機與周邊產品,便在2021年下半年到2022年初陸續問世,但直到2023年,市場主流規格仍是PCIe 4.0,只有部分高階主機與SSD產品才支援PCIe 5.0。到了今年,這個情況才有所改變。
觀察PCIe 5.0普及程度的最佳指標,便是每年的Computex展。在去年的Computex,出現了第一批支援PCIe 5.0的主機板與伺服器產品,但多數產品仍只支援PCIe 4.0。到了今年Computex,所有展出主機板與伺服器產品幾乎全都支援PCIe 5.0,也出現不少PCIe 5.0 SSD產品,意味整個應用生態系已基本成形。
邁向PCIe 6.0與7.0
彷彿是要追趕因PCIe 4.0延宕而損失的時光,負責PCIe規格制定的PCI-SIG組織,在PCIe 5.0之後明顯加快了新一代PCIe規格的制定。在發佈PCIe 5.0正是規格過後僅僅2年半,便在2022年1月宣布PCIe 6.0的規格制定完成,接著又在2022年宣布將發展PCIe 7.0,預定2025年完成規格制定。
相較於過去的PCIe規格,PCIe 6.0與7.0引進了重大的技術變革,以4級脈衝調變(PAM4)技術,取代自PCIe 3.0沿用到5.0的不歸零(NRZ)
調變技術,可在相同頻率內承載兩倍資料,幫助PCIe 6.0與7.0實現翻倍的頻寬增長——比起每通道32GT/s的PCIe 5.0,PCIe 6.0與7.0分別提高到64GT/s與128GT/s。
但PAM-4編碼錯誤率也比NRZ高出許多,故需另外結合前向糾錯技術(FEC)來確保資料完整性,然而這又會帶來延遲增加、減少有效頻寬利用率的代價。儘管如此,PAM調變藉由較高的資料承載能力,已成為當前超高速網路傳輸技術普遍使用的信號調變技術,除了PCIe 6.0與7.0外,後面介紹的NVLink等GPU互連通道,以及400Gb等級以上的乙太網路等。
雖然PCI-SIG加快了制定新一代規格的步伐,但在產品應用方面,並不能跟上這樣快的更新頻率。PCI-SIG曾樂觀地預測,最快在2024年初便能見到PCIe 6.0被應用在實際產品上,隨後PCIe 7.0也將在2027年內進入實際應用。但現實並不如PCI-SIG設想的那樣順利,直到已經要進入2024年下半的今日,還尚未有任何採用PCIe 6.0的實際產品進入市場。
迄今PCIe 6.0仍處於產品開發的早期階段,自2022年初正式發布規格後,一直到2023年中,只陸續有廠商發表PCIe 6.0配套的開發測試用設備,以及中介片(Interposer)等元件。實際的PCIe 6.0產品應用,或許要等到2025年以後。
從目前的情況來看,PCIe 6.0的產品應用速度,將會落後於前2代的PCIe 4.0與5.0。以PCIe 4.0來說,在2017年6月正式版規格發布後,在該年年底到2018年初,第一批支援的主機與周邊產品就隨之問世,在PCIe 5.0方面,自規格發布到首批產品問世,則相隔2年左右。至於PCIe 6.0,恐怕會拖到3年以上。
GPU專屬傳輸架構的興起
相較於10年前,當前伺服器內部I/O架構最大的變化,便是出現了GPU專用的直連傳輸通道。以Nvidia為首,隨後AMD與Intel陸續跟進,先後推出搭配自身GPU的互連傳輸技術。
事實上,直到7、8年前,GPU之間也是透過PCIe來相互連接,例如Nvidia最早的多GPU直連技術——GPUDirect P2P,便是讓多個GPU之間透過PCIe介面,直接存取彼此的顯示記憶體。問題在於,對於GPU直連應用來說,2010年代初期當時主流的PCIe 3.0,頻寬早已不敷所需,即便是當時發展中的PCIe 4.0,頻寬也略嫌不足,促使Nvidia決定打造自身專屬的GPU直連傳輸通道技術,成果便是2016年開始正式採用的NVLink技術。
NVLink是Nvidia專屬的GPU點對點直連匯流排技術,可以擺脫PCIe帶來的瓶頸,第1代的NVLink就能提供最大160GB/s的總頻寬,是PCIe 3.0x16(32 GB/s)的5倍以上,相當程度解決GPU相互直連的傳輸頻寬需求,可藉此將多個GPU連結組成一個GPU運算陣列。
由於NVLink的點對點直連傳輸架構,能能為個別GPU提供的傳輸鏈路數量有限,於是Nvidia接著在2017年推出NVSwitch交換器晶片,可以連結2組NVLink,從而構成規模更大的GPU運算陣列。
稍後在2022年,NVLink又對NVLink技術做了重大的擴展,首先是採用新式調變技術、進一步提高頻寬的第4代NVLink與NVSwitch,其次是同步發表2項延伸技術:
一是NVLink C2C,C2C即Chip to Chip之意,可為CPU與CPU,或CPU與GPU,提供900GB/s的雙向直連傳輸頻寬。二是NVLink Switch,這是以NVSwitch為基礎,所衍生出的獨立交換器產品,可將NVLink的連接擴展到機箱之外,提供跨機箱之間的GPU相互直連。
先前的NVLink與NVSwitch,都是提供Scale-Up縱向形式的GPU直連擴展,用於連結單一GPU伺服器節點內的多個GPU。而NVLink Switch提供了Scale-Out橫向形式的GPU直連擴展,可以連結多臺GPU伺服器節點,從而極大幅度地擴張NVLink網域內直連GPU數量。
另一方面,過去利用乙太網路或InfiniBand介接的跨GPU伺服器節點互連,雖然也能串連多臺GPU伺服器,建構出大型GPU運算網路,但節點之間並非GPU直連架構,傳輸效能會受中介網路的制約。而NVLink Switch是以NVLink直連形式實現跨節點互連,能維持NVLink的低延遲與高傳輸效能。
每臺1U尺寸的NVLink Switch機箱,含有2個NVSwitch晶片(一共128個NVLink埠),可提供32個OSFP埠,每個埠含有8個112 Gb傳輸通道。由於NVSwtch與NVLink Switch系出同源,Nvidia目前已統一稱為NVLink Switch。
到2024年為止,NVLink已經發展了5個世代,總頻寬從160 GB/s逐步提高到1800 GB/s,每顆GPU允許的最大鏈結數量也從4個提高到18個。NVLink Switch也已發展到第4代,GPU直連傳輸頻寬從300 GB/s提高到1800 GB/s,允許直連的GPU數量更從16個大幅提高到576個。
AMD與Intel的GPU互連架構
在陸續推出NVLink、NVLink Switch與NVLink C2C之後、Nvidia也完成自身的伺服器I/O架構轉型,運算核心單元完全依靠自身專屬架構互連,至於PCIe,則退居次要角色,只剩下連接網路、儲存等周邊裝置的用途。
這也讓Nvidia徹底擺脫PCIe這類開放規格的制肘,可以透過自身專屬I/O架構,連結大量的GPU,建構出超大規模、超高密度的GPU運算環境,這也是10年前所無法想像的。因而NVLink等專屬GPU互連I/O技術,也就成為維持Nvidia在GPU領域「霸業」的護城河之一。
而NVLink的成功,自然也促使競爭對手AMD與Intel跟進,推出類似的GPU互連I/O技術。
AMD的GPU互連I/O技術,是由Infinity Fabric晶片互連匯流排延伸發展而來。
2017年推出的第1代Infinity Fabric,最初是搭配當時新推出的第1代Zen架構處理器,作為CCX處理器核心模組間的互連通道,類似傳統chiplets之間Hypertransport匯流排的升級版本,AMD又稱為全域記憶體互連介面(xGMI)。
接著,跟隨第2代Zen架構處理器一同發表的第2代Infinity Fabric,不僅提高傳輸頻寬,並新增GPU與GPU互連功能,具備類似Nvidia NVLink的功能,AMD也將應用這種I/O技術的處理器架構,命名為Infinity Architecture。
然後,便是2020年初發布的第3代Infinity Fabric,在先前的CPU互連與GPU互連功能外,增加CPU與GPU互連的能力,同時也提高了傳輸頻寬。最新的是,2023年與Instinct MI300 GPU平臺一同發表的第4代Infinity Fabric,除了進一步提高頻寬,還擴展了連接能力,可為GPU、CPU、FPGA、快取記憶體,甚至第3方晶片組提供高速互連通道。
針對跨GPU伺服器節點的互連,AMD的方案則是透過RDMA乙太網路,來介接Infinity Fabric節點,但這屬於傳統的跨節點網路互連,節點之間須透過乙太網路中介,與Nvidia利用NVLink Switch實現跨節點GPU直連相比,有著本質上的差異。
至於Intel的GPU互連I/O技術,則是2019年底發表Xe GPU架構時,所提及的Xe Link互連架構,後來在2022年底跟著Data Center Max系列GPU,即代號Ponte Vecchio的GPU一同發表。Xe Link可為Max系列GPU卡提供多卡串聯,或是為OAM子板模組上的GPU提供內部互連。
對於跨伺服器節點的互連,Intel則提供基於直連銅纜的Xe Link Glueless,以及基於InfiniBand網路等2種方案,前者可連結64組OAM模組,後者則可連結512組OAM模組。但這2種互連方式,也是屬於傳統的跨節點網路中介互連,不同於Nvidia的跨節點GPU直連。
除了自身發展的Xe Link互連架構,Intel另外在2019年透過併購Habana Labs,而取得後者在Gaudi系列AI加速器上,所應用的整合式乙太網路互連技術,利用整合在晶片上的10或24個100GbE埠,可透過低成本的乙太網路,實現從內到外的高頻寬GPU直連。
GPU I/O架構的競爭
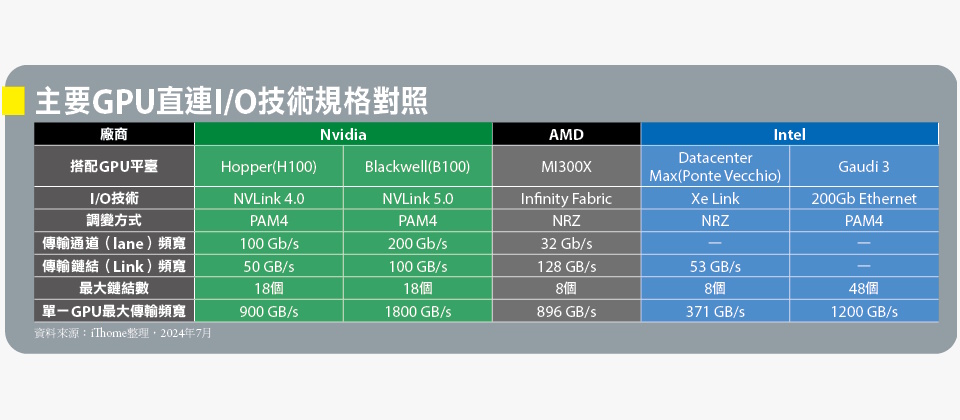
包括Nvidia的NVLink,AMD的Infinity Fabric與Intel的Xe Link,均提供單一節點內的多GPU互連,以及跨多節點的GPU互連,儘管功能涵蓋面相當,但在傳輸效能與跨節點連結能力方面,存在相當大的差距。
以NVLink第4代與第5代為例,每個傳輸鏈結(Link)都是由2條信號傳輸通道(lane)構成,每條通道分別可提供100Gb/s與200Gb/s的頻寬,所以每個鏈結擁有雙向50 GB/s與100 GB/s的頻寬(25+25與50+50)。而每個GPU則擁有最多18個鏈結,理論總頻寬達到900 GB/s與1800 GB/s。
而AMD用於搭配MI300X GPU的最新Infinity Fabric第4代,每個GPU允許最多7個傳輸鏈結,每個鏈結由16個傳輸通道構成,每個傳輸通道32 Gb/s頻寬,每個傳輸連結有128 GB/s雙向頻寬,理論最大總頻寬為896 GB/s。
至於Intel Xe Link,每個鏈結有單向26.5 GB/s頻寬,雙向53 GB/s頻寬,Xe Link可支援最大8組Xe GPU單元(Xe HPC Stack)互連,每組Xe GPU單元的理論最大總頻寬為371GB/s。
單就傳輸效能規格來看,AMD Infinity Fabric與Intel Xe Link的單一傳輸鏈結頻寬,並不比NVLink差,但每個GPU允許的傳輸鏈結數量上限卻遠少於NVLink,因而總頻寬有著數倍的落差,只相當於1、2個世代以前的NVLink規格。
而在跨節點互連方面,Nvidia可透過Nvidia NVLink Switch,實現跨節點NVLink直連,從節點內部到外部都是NVLink直連到底。而AMD Infinity Fabric與Intel Xe Link,都只能提供個別節點內部的GPU直連,至於跨到外部的連結,都需透過乙太網路或InfiniBand的介接,在效能與延遲上與Nvidia有著根本的差距。
傳輸效能與跨節點能力的差異,也制約了AMD與Intel GPU實際應用的效能發揮。
AMD與Intel的個別GPU效能規格,往往不亞於Nvidia的GPU,部分特性甚至猶有過之,然而現實環境大多需要多GPU協同運作,而AMD與Intel的GPU直連I/O架構,在多個GPU互連的環境下,就會暴露總頻寬遠不如Nvidia的問題,連結的GPU數量越多,差距越顯著。而且AMD與Intel都缺乏Nvidia NVLink Switch這一層擴展介接技術,當互連的GPU數量超過8個時,就必須透過外部網路介接來實現跨節點互連,因而也會惡化傳輸頻寬與延遲表現。
相較下,Intel透過併購取得的Gaudi系列AI加速器,I/O架構採取基於乙太網路的低成本互連路線,反而更有競爭力,不僅成本相對較低,也便於利用乙太網路實現從節點內部到外部的直連,但缺點是延遲應該明顯不如NVLink。
最新的Gaudi 3在晶片內整合多達24個200GbE埠,其中21個埠用於節點內OAM模組互連,可為每顆加速器晶片提供最大1200GB/s的頻寬,勝過NVLink第4代,僅次於NVLink最新的第5代。另外3個200GbE埠則用於Scale-Out外部互連,轉接到基板(Baseboard)上的800G OSFP埠,用於連接其他節點。
通用GPU I/O架構的嘗試
比起GPU晶片本身的規格與效能特性,或是搭配GPU的CUDA程式開發框架,Nvidia的I/O架構,其實才是競爭對手更難以跨越的障礙。
無論AMD或Intel,顯然單打獨鬥都不會是Nvidia的對手,唯一辦法是團結求存,於是以AMD與Intel這兩大晶片廠商為首,加上Broadcom、Cisco兩大網通廠商,還有Google、HPE、Meta與微軟,一共8家大廠今年5月共同宣布,將合作發展稱作UALink(Ultra Accelerator Link)的加速器晶片互連I/O架構,企圖以此抗衡Nvidia的NVLink。
目前UALink規格仍在制定中,預定2025年發表1.0版規範,依照目前傳出的消息,一種可能的框架是以Infinity Fabric結合乙太網路,分別構成新協定的上層與底層,藉此實現跨節點內、外的GPU直連架構。
相比於NVLink,UALink最吸引人之處,是可藉此打破Nvidia的規格壟斷,以及多供應商參與帶來的通用性與成本效益。問題在於,Nvidia並不會停下腳步等待競爭對手,依過去經驗來看,Nvidia幾乎每隔2年就會更新一代NVLink規格,待UALink進入實用階段,NVLink屆時也可望進化1到2個世代,從而持續保持優勢。在UALink能發揮多供應商參與的群聚效應之前,NVLink可望仍能長期維持優勢。
PCIe與NVLink的傳輸效能發展過程對照
我們將PCIe與NVLink等兩種傳輸介面,各個世代的傳輸效能規格,依發表時間整理成圖表,其中PCIe介面的傳輸頻寬以16 lane規格雙向頻寬為代表,NVLink則以單一GPU理論上所能獲得的總頻寬為基準。
從此圖可看出,相較於同世代PCIe,NVLink一般都擁有5倍左右的傳輸頻寬優勢。
除了頻寬優勢,比起PCIe這種必須適應各式各樣周邊裝置與應用環境的開放性業界標準規格,NVLink是Nvidia專為自身GPU直連傳輸需求,量身打造的專屬規格,享有規格封閉與完全自主的優勢,因此更新速度也十分頻繁與穩定,近來都是每兩年更新一代。
.png)
擺脫PCIe的制肘:Nvidia的I/O架構轉型
下圖為NVLink問世以前,典型的GPU對GPU,與GPU對CPU互連架構,GPU與GPU或CPU之間,都是透過PCIe介面互連,但PCIe同時是伺服器內部眾多周邊設備共同使用的傳輸通道,因而PCIe的效能與資源也就成為制約GPU I/O效能的瓶頸。這也促使Nvidia另行發展NVLink傳輸架構,以求擺脫PCIe的制肘。圖片來源/WikiChip
.png)
下圖為Nvidia去年發表的Grace Hopper超級晶片I/O架構,在GPU之間與GPU到CPU之間,分別採用NVLink與NVLink C2C介面互連,PCIe只作為次要角色、用於CPU對外連接,只配置了4組16通道的PCIe 5.0介面。圖片來源/Nvidia
.png)

熱門新聞

2026-02-02

2026-02-03

2026-02-04

2026-02-02

2026-02-04


2026-02-03

2026-02-05