在炙手可熱的生成式AI技術領域,近來最受到眾人所矚目的消息,便是Meta發表了當前規模最大的Llama 3.1大語言模型模型,該公司宣稱在多項基準測試中,超越原先的領先者OpenAI的GPT-4o,與Anthropic的 Claude 3.5 Sonnet,成為當前最強大語言模型,也標誌著開源大語言模型的能力已追上閉源大語言模型。
除了亮眼的AI表現,Meta也透過論文《The Llama 3 Herd of Models》,以及部落格文章《Building Meta’s GenAI Infrastructure》等文件,公布訓練Llama 3的基礎設施硬體架構細節,方便外界了解,使更多人得以一窺這種頂級AI模型所需耗費的硬體資源規模與架構形式,進而還能作為這個領域的參考範本。
Meta AI基礎設施的演進
雖然Meta投入AI基礎設施建置已久,但2022年才陸續公開相關訊息。
Meta在AI研究方面的起點,可追溯到Facebook於2013年成立的AI研究實驗室(AI Research lab),Meta第1座專為AI研究建置的高效能運算系統則是在2017年完成,由2.2萬個Nvidia V100 GPU構成,每天可執行3.5萬個訓練作業。
接著Meta於2020年開始打造新一代基礎設施,成果便是2022年中完工的AI研究超級叢集(AI Research SuperCluster,RSC),含有1.6萬個Nvidia A100 GPU,Meta自詡是當時最快的AI研究用超級電腦,而Llama模型前2個世代——Llama 1與Llama 2,都是利用這座RSC叢集來訓練,也用於電腦視覺、自然語言處理、語音識別、圖像生成與程式編撰等AI模型開發。
Meta在2024年又建置更大型AI叢集,是Meta第3代的AI運算叢集,能夠支援更大、更複雜的模型運算,以便為開發生成式AI產品鋪路,Llama 3模型便是採用這座設施來訓練。
目前Meta尚未給予這座新AI叢集正式命名,而是在不同場合以「新AI叢集」、「生產叢集」(production clusters),或是「24k GPU叢集」(24k GPU clusters)稱呼。
其中新AI叢集的說法,是相對於RSC叢集,表明這座叢集是新建置的;生產叢集的稱呼,是強調這座叢集的設定,針對生產層級的可靠性(production-grade reliability)做了最佳化,以便擴大訓練的規模;而24k GPU叢集的稱呼,則是指稱其含有的GPU規模,達到24k個Nvidia H100 GPU(24,576個)。

Meta新AI叢集的特色
相較於上一代的RSC叢集,新的24k GPU叢集無論在運算單元、網路規格與儲存裝置組成方面,都有明顯的差異。
就運算單元來說,上一代RSC叢集,是採用搭載8個Nvidia A100 GPU的Nvidia DGX A100 AI伺服器,新AI叢集改用Meta自身開發、搭載8個Nvidia H100 GPU的Grand Teton AI伺服器。
在規模方面,新AI叢集擁有24,576個H100 GPU,上一代RSC叢集則為16,000個A100 GPU。新AI叢集的GPU數量比先前RSC叢集多出1/3,而就個別GPU的效能而言,H100在不同浮點數精度的運算效能,約比A100高出2到3倍以上,所以整座新AI叢集的GPU運算效能,至少比RSC叢集高出3到4倍。
在網路架構方面,上一代RSC叢集是以2層式的200Gb InfiniBand網路,作為GPU伺服器節點的互連架構。新AI叢集則依模型規模,分別採用400Gb頻寬的RoCE乙太網路或InfiniBand,提供GPU伺服器節點間互連,並採用3層式網路架構,以支援更大規模的叢集環境。
而在儲存裝置方面,基本上,RSC叢集是以市售儲存產品為主,包括:作為儲存層的175 PB容量PureStorage FlashArray儲存陣列,作為快取的46 PB容量Penguin Computing Altus系統,加上提供NFS存取的10 PB PureStorage FlashBlade儲存設備,總容量為231 PB。
到了新AI叢集,Meta則改用自身的Tectonic分散式檔案系統,來打造配套的儲存叢集,總容量維持在同級的240PB,但擴展能力更大,整個儲存叢集由7,500臺伺服器構成。
所以,無論在GPU運算能力、網路傳輸頻寬,還是儲存架構擴展性,新AI叢集都比上代RSC叢集躍升一個檔次。
除了規格全面提升外,新AI叢集的另一特色,是大幅度的「Meta化」與「OCP化」。
上一代RSC叢集的主要元件,多是其他廠商提供的現有產品,如AI伺服器採用Nvidia DGX A100,網路交換器是Nvidia Quantum系列,儲存設備則是購自Pure Storage與Penguin Computing。
而新AI叢集的主要組成元件,則多是Meta自行開發的OCP開放規格硬體,包括做為AI伺服器的Grand Teton GPU伺服器平臺,構成儲存叢集的Yosemite伺服器、Open Rack機架、以及Wedge 400與Minipack交換器等,另搭配部分外部廠商產品。
Meta目前一共打造了兩座這種24k GPU叢集。而Llama 3的3種規模版本——8B(80億個參數)、70B(700億個參數)與405B(4050億個參數),最大型的405B版本使用16k個GPU(16,384個)的叢集,也就是耗用了每座24k GPU叢集約2/3的運算能力。
接下來我們就依運算單元、儲存單元與網路單元的順序,逐一介紹Llama3模型訓練基礎設施的詳情。
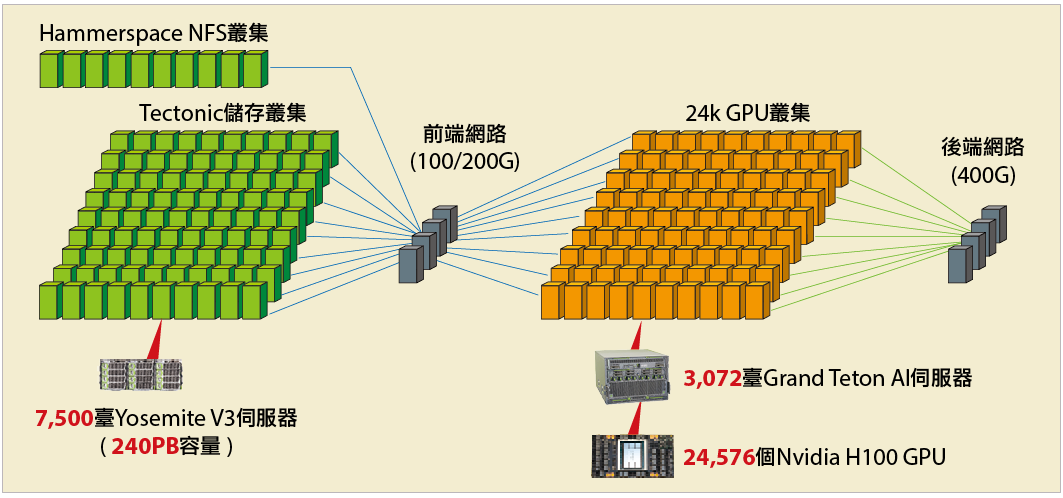
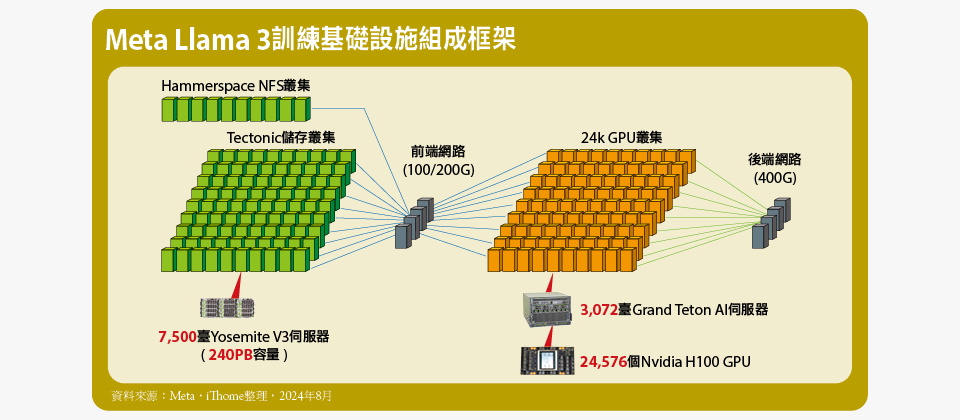
Meta Llama 3訓練基礎設施組成框架
Llama 3模型使用的訓練基礎設施,是以24k GPU叢集為核心,搭配儲存叢集,以及前、後端網路而成。
24k GPU叢集是由3,072臺Grand Teton AI伺服器組成,一共有24,576個Nvidia H100 GPU與6,144個CPU。
儲存叢集則分為2大部分,一為提供模型訓練資料輸入、保存檢查點等主要訓練任務的儲存需求,由Tectonic分散式檔案系統構成的儲存叢集,採用總數達7,500臺的Yosemite V3伺服器組成。另一為基於Hammerspace平臺的NFS儲存服務叢集,用於程式開發修改等任務,同樣採用Yosemite V3伺服器來部署。
而儲存叢集透過100/200G規格的前端網路,來與24k GPU叢集連結。24k GPU叢集內部的所有運算節點,則透過400G的RoCE或InfiniBand互連,構成GPU互連專用的後端網路。
超大規模的GPU運算單元
如同前面提到的,訓練Llama 3使用的24K GPU叢集中,作為運算核心的Nvidia H100 GPU,是安裝在Meta的Grand Teton AI伺服器平臺上運行。
Grand Teton是Meta於2022年OCP全球大會所發表的AI運算平臺,同時,也是Meta上一代AI運算平臺Zion與Zion-EX的後繼者,整套系統圍繞著Nvidia H100 GPU打造,並引進一系列新硬體規格,包括PCIe 5.0介面、DDR5記憶體、OCP 3.0規格的200GbE或400Gb網路卡等,不僅提供2倍於上一代平臺的運算與資料網路頻寬、4倍的CPU與GPU頻寬,還能承受2倍的熱量,機箱架構也大幅更動。
上一代的Zion平臺是由3個機箱模組組成——CPU頭節點(CPU Head Node)、交換器同步系統(Switch Synchronization System),以及GPU系統,需透過外部纜線來連接這3個模組,但這也增加布線複雜性與故障機率。
而Grand Teton則改用單一機箱設計,組成的3大基本單元:CPU、交換器與GPU加速器,都各自以托盤模組(Tray)安裝在單一機箱內,完全去除電源與網路之外的所有外部佈線,藉此能改善整體效能、信號完整性與熱效能,還能大幅簡化部署程序,便於資料中心叢集快速導入與擴展,並減少潛在故障點,提供更高的可靠性。
Grand Teton AI伺服器的架構
Grand Teton伺服器在8個OU高度的機箱內,由上而下分別容納2 OU高度的CPU托盤模組、2個OU高度的交換器托盤模組,以及4個OU高度的加速器托盤模組。
其中CPU托盤模組含有2組CPU插槽,各自搭配1張OCP規格的前端網路卡與1組開機磁碟,在處理器組態方面,則有搭載Intel Xeon Sapphire Rapid處理器與2 TB DDR5記憶體,或是搭載AMD EPYC Genoa與2.3TB記憶體等兩種選項;交換器托盤模組則是以4組Broadcom的PCIe 5.0交換器晶片為核心,提供CPU、GPU、網路卡與SSD等裝置互連所需的PCIe 5.0通道,以及安裝網路卡與SSD的空間,最多可安裝8張OCP規格RDMA網路卡,以及16臺E1.S SSD;至於加速器托盤模組,則可安裝8個H100 GPU單元。
請注意!在整臺Grand Teton伺服器中,GPU與RDMA網路卡採1比1的配置,確保為每個GPU提供充足的跨機箱連結傳輸頻寬。
個別托盤模組之間,則是透過內含PCIe 5.0×16通道的ExaMax連接埠互連,CPU模組與加速器模組各自透過位於機箱後方的4條ExaMax纜線,連接到交換器模組上,藉此構成3大模組間的互連。

Meta Llama 3訓練設施的運算核心:Grand Teton AI伺服器
Llama 3訓練用的24k GPU叢集,採用Meta自行開發的Grand Teton AI伺服器,構成叢集的運算核心。Grand Teton是一種符合OCP規格的GPU伺服器,機箱內含有3個核心的托盤模組,由上到下分別是GPU模組、交換器模組與GPU模型,CPU模組含2個CPU、記憶體、開機碟與前端網路卡,交換器模組含16臺E1.S SSD與8張後端網路卡,GPU模組則安裝了8張H100 GPU卡。
AI叢集的規模
24K GPU叢集的Grand Teton AI伺服器,每臺都滿載8個H100 GPU與2個CPU,但Meta並未公布其採用的CPU型式,其中8個GPU透過NVLink彼此互連,而GPU與其他裝置,以及其他裝置之間,則都是透過PCIe 5.0互連。
依這個規格推算,整個24k GPU叢集,至少包含3,072臺Grand Teton AI伺服器,匯聚了24,576個H100 GPU與6,144個CPU,還有分別用於搭配GPU與CPU的1,920TB HBM3記憶體,與12 PB以上的DDR5記憶體,可說是相當龐大的運算資源,但這樣高的配置,必然也會在功耗上付出可觀的代價。
依照Meta提供的規格,每臺Grand Teton伺服器的TDP大約是8.3kW,所以整個24k GPU叢集中,光是AI伺服器部分累加的TDP,大約是25,497kW,也就是接近25.5 MW左右。相較之下,臺灣目前運算能力最高的超級電腦——Nvidia 今年於高雄啟用的Taipei-1(TOP500排名第38),據稱功耗為7.68 MW,只相當於Meta 24k GPU叢集的1/3。
.png)
Llama 3訓練基礎設施運算單元圖解
Llama 3訓練用的24k GPU叢集,是以1座包含2臺Grand Teton AI伺服器的機櫃(Rack),作為基本單位。
每一臺Grand Teton AI伺服器的GPU托盤模組,含有8個H100 GPU,彼此間透過NVSwitch互連,並透過交換器托盤模組上的8張400G RDMA網路卡,連接到機櫃上扮演機架訓練交換器(RTSW)的角色的1臺Minipack2交換器,構成跨伺服器機箱的GPU互連。GPU與400G RDMA網卡為1比1配置,以確保傳輸頻寬。
而每1座機櫃上的2臺AI伺服器,便藉由RTSW交換器的連接,構成1組含有16個GPU的機櫃單元,然後再經由RTSW交換器連接到上一層的叢集訓練交換器(CTSW)上,組成跨機櫃的GPU互連網路,也就是後端網路。
Grand Teton AI伺服器的CPU托盤模組另有2張前端網路卡,是作為連接前端網路之用,至於機架上的Wedge 400C交換器,我們推測可能是作為讓AI伺服器介接前端網路的機架交換器(RSW)角色。
高擴展性的儲存單元
在儲存配置上,Meta使用自身開發的Tectonic通用分散式檔案系統,建立搭配Llama 3的預訓練(Pre-training)儲存環境。
Mtea之所以會決定要採用Tectonic,是希望透過這套系統強大的橫向擴展與負載平衡能力,因應Llama模型訓練過程當中,高突發性(Highly bursty)的檢查點(Checkpoint)資料寫入作業需求,這也是支援大語言模型訓練的儲存基礎架構,所面對的主要挑戰。
所謂的檢查點是為了保存每個GPU的模型訓練狀態,作為復原或偵錯之用,每個GPU會為此產生大約1 MB到4 GB的資料量,然而,當數千個GPU同時寫入檢查點,會在短時間內讓底層的儲存架構達到飽和狀態,甚至癱瘓。
Meta的設計目標,是盡可能減少寫入檢查點期間的GPU暫停時間,並增加建立檢查點的頻率,降低復原後損失的工作量,因此,盡可能提高持續寫入效能便成為這套儲存架構的需求重點,藉此減少每次檢查點寫入作業耗用時間。
為此Meta選擇旗下最大型的分散式檔案系統Tectonic,來承擔Llama 3儲存基礎架構的重任。
Tectonic分散式檔案系統
Tectonic是Meta自2014年起開始發展,2021年正式發表的分散式檔案系統,最初計畫名稱為Warm Storage,特點是3層式、可橫向擴展規模的Metadata儲存架構,以及基於Erasure Coding的Chunk Store資料儲存節點單元,擁有強大的擴展與負載平衡能力,可支援EB等級的儲存空間需求。
依照Meta的資料,當時他們內部實際使用的Tectonic儲存叢集,最大規模已達到4千個節點,以及1,590 PB總容量。
而在搭配Llama 3訓練工作的執行時,Meta是以7,500臺配備E1.S SSD的YV3 Sierra Point伺服器,建構Tectonic分散式檔案系統的儲存環境,節點數量超過先前Meta最大型的Tectonic儲存叢集,但容量低了一個層次,總共240PB空間。
採取這種配置的目的,應是透過數量更多的節點匯聚更高的存取效能,Meta宣稱這座儲存叢集擁有2TB/s的持續吞吐率,以及7TB/s的尖峰吞吐率,支援數千個GPU同步載入與儲存檢查點。
在儲存環境的存取方面,AI叢集節點是透過FUSE API,經由100GbE或200GbE網路,來掛載與使用Tectonic分散式檔案系統的空間。
建構儲存叢集的硬體元件
至於Meta部署Tectonic儲存叢集使用的YV3 Sierra Point伺服器,則是Yosemite V3模組化伺服器,以及Sierra Point E1.S儲存刀鋒模組的組合。
其中的Yosemite V3是Meta於2021年OCP大會發表,符合OCP認證規格的多節點模組化伺服器,也是Meta前身Facebook時期,於2015年起陸續推出的Yosemite系列模組化伺服器第3代版本。
Yosemite V3的基本單元是4個OC高度的機箱底座,機箱內部分為3個橫向的滑橇(Sled)空間,每個滑橇含有1到4個插槽,可以垂直堆疊的方式,安插1到4個刀鋒(Blade)模組,每個滑橇內的刀鋒模組共用1個管理板(Management board),以及1張多主機(Multi-Host)OCP 3.0網路卡。藉由這種刀鋒式模組化設計,可提高運算密度,減少網路與供電布線,並改善擴充與維護便利性。
目前Yosemite V3有多種刀鋒模組可供選擇,而Meta建構Llama3的Tectonic儲存叢集時,使用的硬體組態,應該是Yosemite V3的Delta Lake伺服器刀鋒,加上Sierra Point儲存刀鋒的組合。Delta Lake伺服器刀鋒含有1個Intel第3代Xeon Scalable處理器與1.92TB記憶體,Sierra Point儲存刀鋒則能提供6臺E1.S SSD。
額外的輔助儲存架構
除了支援主要訓練儲存作業的Tectonic儲存叢集外,Meta還與Hammerspace合作,開發部署了一套平行式NFS存取儲存系統,作為輔助的儲存架構,藉此為AI叢集提供跨大量伺服器的高效率遠端共享存取操作,例如藉由跨節點即時存取程式碼異動的能力,來執行包含數千個GPU的互動式作業偵錯。這套NFS存取系統,也是利用Yosemite V3伺服器,以及Sierra Point儲存刀鋒來部署。
Meta並未詳細解釋這套平行NFS存取架構。我們推測由於Hammerspace擅長領域是超大規模NAS,以及平行NFS存取技術,或許Meta是利用Hammerspace技術,為AI叢集部署一套使用平行NFS存取的NAS,或NAS閘道器。
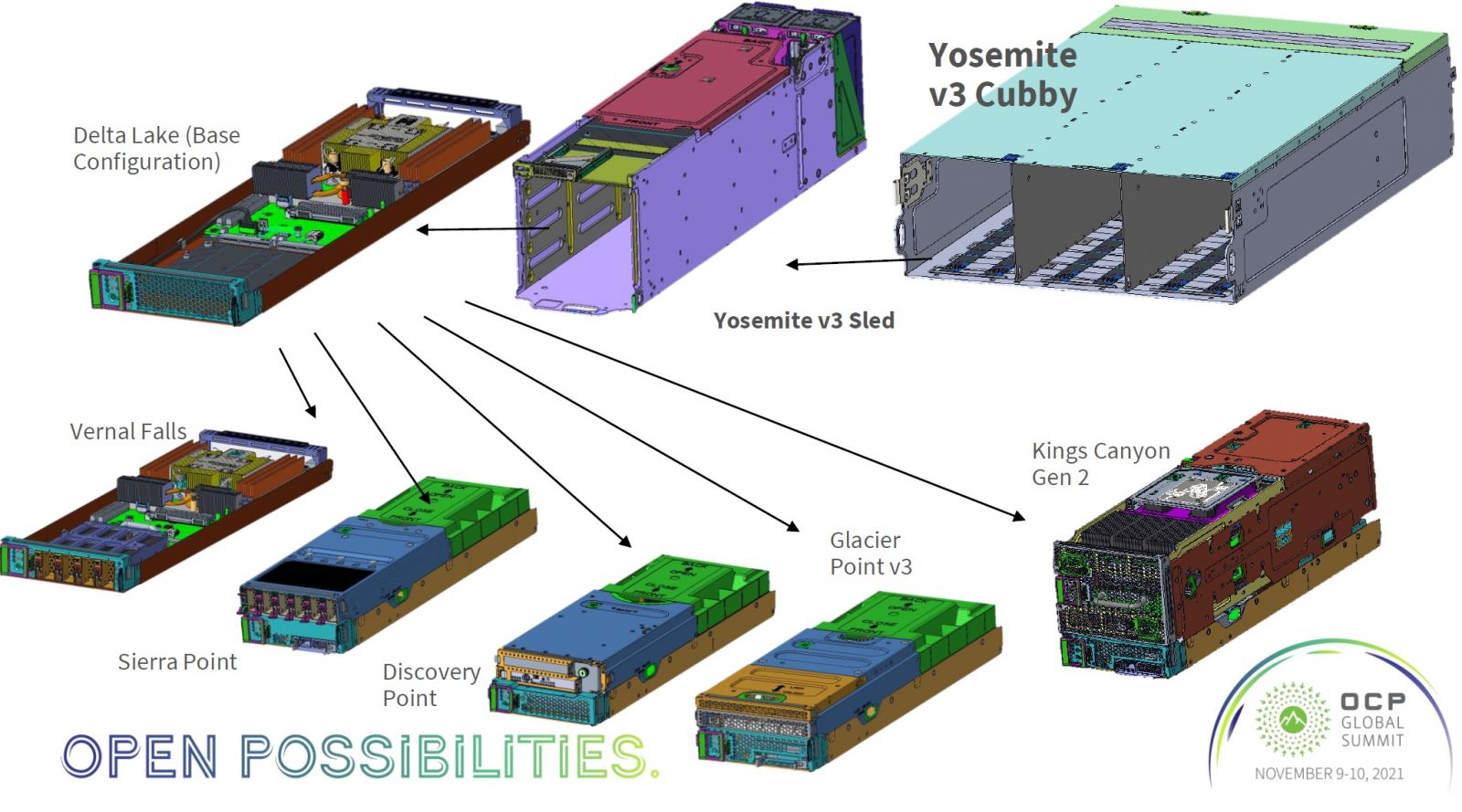
Llama 3基礎設施的儲存單元硬體
Meta使用自行開發的Yosemite V3模組化伺服器,來運行Llama 3基礎設施使用的Tectonic儲存叢集,與Hammerspace NFS儲存環境。
Yosemite V3是OCP規格的模組化伺服器,有多種刀鋒模組可供搭配,最基本的模組,包含1個Intel第3代Xeon Scalable處理器、1.92TB記憶體與1臺M.2 SSD的Delta Lake伺服器刀鋒,另外再搭配各式各樣用於擴展儲存與介面卡的刀鋒模組,包括提供4臺E1.S SSD的Vernal Falls 儲存刀鋒,提供6臺E1.S SSD的Sierra Point儲存刀鋒,用於提供CEM附加卡插槽的Discovery Point刀鋒,提供6個Dual M.2加速器模組與2臺E1.S SDD的Glacier Point刀鋒等。
建構多層式網路連結2.4萬個GPU
關於Meta Llama 3訓練環境使用的網路架構,目前有2個主要參考來源,第一篇是Meta論文《The Llama 3 Herd of Models》,提供了概略網路框架,另一篇也是Meta論文《RDMA over Ethernet for Distributed AI Training at Meta Scale》提供更詳細資料,Meta部落格文章《RoCE networks for distributed AI training at scale》,則是後者精簡版本。
Meta將Llama 3訓練環境的網路,區隔為前端網路(Frontend,FE),以及後端網路(Backend,BE)等兩大部分。
● 前端網路
前端網路用於為AI叢集提供訓練工作負載的資料輸入,保存檢查點以及日誌等用途,採用100Gb與200Gb來與AI叢集連結,Tectonic儲存叢集便是透過前端網路,來與AI叢集連結,將資料匯入AI叢集,並接受從AI叢集的檢查點寫入。
前端網路是典型的階層式架構,最前端是直接與AI叢集連結的機架交換器(Rack Switch,RSW),下一層是網路交換器(Fabric Switch,FSW),最底層是儲存節點。
前端網路的關鍵,在於機架交換器必須提供足夠的入口頻寬,以免妨礙工作負載的傳輸。
● 後端網路
後端網路是專門用於AI叢集內,每一臺AI伺服器之間的互連,為GPU與GPU之間,提供跨伺服器機箱之間的高頻寬、低延遲與無損的傳輸通道,這部分採用400Gb規格。
● AI伺服器的網路連接
AI叢集中的每一臺Grand Teton AI伺服器,都同時連接了前端網路與後端網路,我們推測應是利用CPU托盤模組配置的2張前端網路卡,來連接前端網路;並利用交換器托盤模組配置的8張RDMA網路卡,來連接後端網路。
從Meta公開的資料來看,當訓練工作負載規模較小,只使用少於8個GPU時,直接透過伺服器內的NVLink來提供GPU與GPU之間的連結,而不需要使用後端網路進行跨伺服器的連結。當訓練工作負載較大時,才會啟用後端網路,藉由GPUDirect RDMA技術進行跨伺服器的GPU對GPU資料傳輸。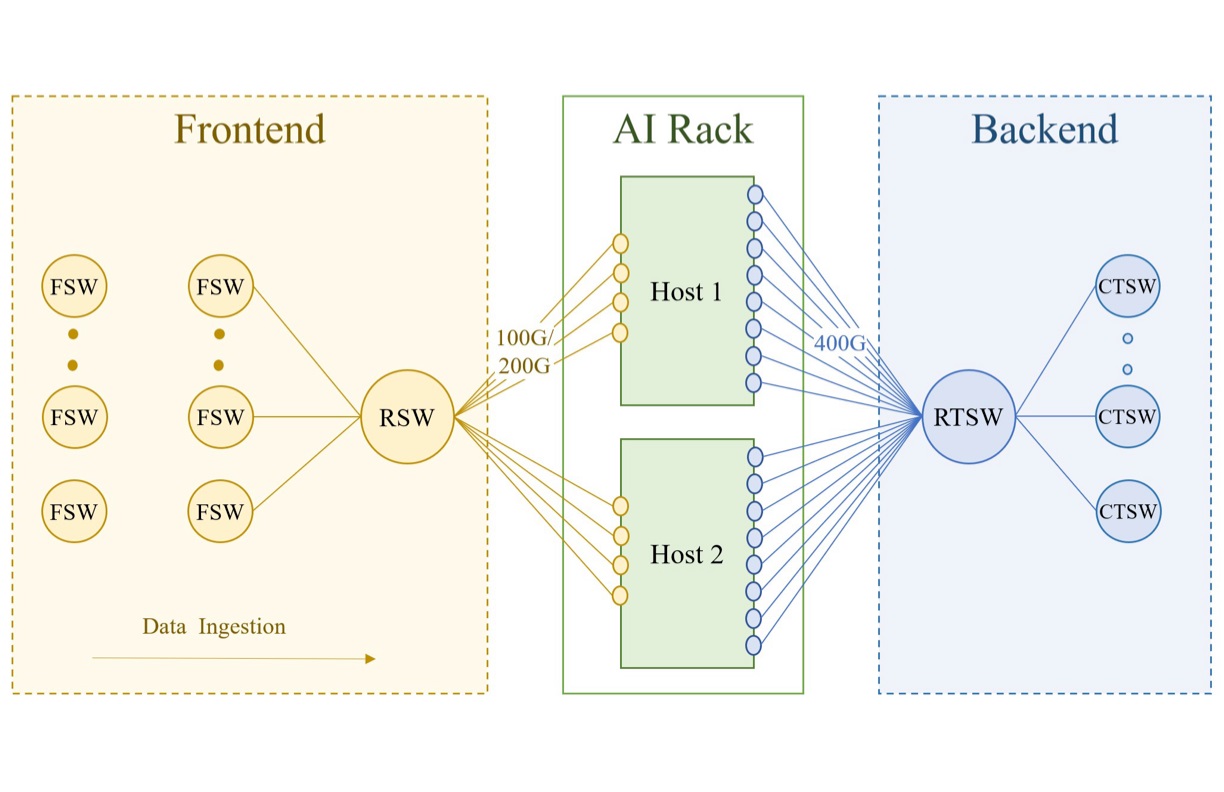
Llama 3訓練基礎設施的網路架構
GPU叢集的基本單元,是1座含有2臺Grand Teton AI伺服器的機櫃,也就是上圖中間位置的AI機櫃(AI Rack),然後機櫃當中的每一臺AI伺服器,透過100G/200G網路連接前端網路(Frontend),並透過400G網路連接後端網路(Backend)。
前端網路用於連接儲存叢集,用於饋入訓練資料,以及傳輸與保存檢查點。AI伺服器先接到機架交換器(RSW),再接到網路交換器(FSW),最後連接到儲存叢集的節點。
後端網路是GPU專用的互連網路,用於跨伺服器、跨機架的GPU互連。AI伺服器先接到機架訓練交換器(RTSW),然後再接到叢集訓練交換器(CTSW)。圖片來源/Meta
後端網路的架構
Meta在不同規模的Llama 3模型訓練工作中,分別採用不同後端網路架構。
最大型的405B版本Llama 3,採用RoCE乙太網路作為GPU伺服器叢集的網路架構,規模較小的8B與70B版本採用InfiniBand。無論RoCE乙太網路,還是InfiniBand版本的叢集網路,都是採用400Gb的頻寬規格。
Meta表示,儘管這2種叢集網路底層技術存在差異,但他們透過調整,為大型訓練工作負載提供相同效能表現。
在具體組成的網路設備元件方面,Llama 3 405B版本的RoCE乙太網路,是由Arista的7800R3系列骨幹交換器、Meta自身的Wedge 400C交換器與Minipack2模組交換器所組成。而8B與70B版本的InfiniBand網路,則以Nvidia的Quantum2 InfiniBand交換器構成。
Meta為405B版本Llama 3使用的RoCE乙太網路架構,提供了更詳細的拓樸架構、負載平衡與雍塞管理資訊。Meta這麼做的理由是因為他們完全擁有這套網路架構的設計,不像InfiniBand版本的網路架構是基於Nvidia的技術。
● 網路拓樸架構
基於RoCE乙太網路的Llama 3叢集,是藉由3層式網路拓樸架構,將叢集中的24k個(24,576個)GPU連結在一起。
最底層是個別AI伺服器層級的互連,每兩臺AI伺服器共同安裝在1座機櫃(Rack)上,透過DAC銅纜連接到稱作機櫃訓練交換器(Rack Training Switch,RTSW)的TOR交換器上,每座機櫃一共含有16個GPU。
中間層是機櫃層級互連,每座機櫃的RTSW交換器,透過400Gb光纖纜線連接到叢集訓練交換器(Cluster Training Switch,CTSW)上,然後,192座機櫃可以藉由CTSW交換器之間的連結,構成1組包含3,072個GPU的Pod單元,並具備完整的頻寬對分(Bisection Bandwidth)設計,讓每個GPU之間都有完整的400Gb頻寬,確保不會有超額配置(Oversubscription)的情況。
RTSW交換器與CTSW交換器這2層,組成了AI區域(AI Zone),RTSW構成枝葉交換器(leaf),CTSW作為主幹交換器(Spine),可支援數千個GPU互連,我們推測1個含3,072個GPU的Pod單元,應該就是1個AI區域最大規模。
但Llama等新一代大語言模型,所需要耗用的GPU數量,明顯大於單一個AI區域所能提供的GPU數量規模。所以,Meta在RTSW與CTSW交換器這2層之上,再加上跨AI區域的聚合層,利用聚合訓練交換器(Aggregation Training Switch,ATSW)連接不同AI區域CTSW交換器,建立跨AI區域、跨Pod單元互連。
同一資料中心建築內的8組Pod單元,利用ATSW交換器互連組成含有24k個GPU的叢集。
但聚合層的網路連線並未維持完整頻寬對分設計,而採用1:7超額配置比率。我們推測這或許是基於成本考量,要在聚合層為24k個GPU提供無超額配置的傳輸頻寬,所需成本過高,效益又相對不顯著所致——大部分資料流量都是在個別AI區域內,跨AI區域流量相對有限,因而可容許一定程度超額配置。
另一方面,Meta的Llama 3模型平行作業架構,以及訓練作業排程器(training job scheduler),也針對前述網路拓樸做了最佳化,以最大限度地減少跨AI區域的資料流量,以緩解聚合層因頻寬超額配置導致的流量瓶頸問題。
● 負載平衡
Meta表示,相較於傳統的資料中心工作負載,大語言模型的網路資料流具備幾個不同的特徵,包括資料流數量與樣式明顯較少,通常是重複且可預測,但會在毫秒(millisecond)層級上,出現突發性(Burstiness)流量衝擊,而且在突發流量發生時,強度可達到網路卡的線速,幾乎會佔滿網路卡的傳輸頻寬。
而這樣的特徵,也給支援大語言模型訓練的網路架構,在流量的負載平衡與壅塞管理上,帶來新的挑戰,促使Meta在Llama 3訓練網路架構中,引進有別於傳統架構的負載平衡與壅塞管理機制。
Meta指出,大語言模型的訓練過程所產生的「胖(fat)」網路資料流,不易藉ECMP路由(等成本多路徑)等傳統方法,在可用路徑有效進行負載平衡。
為此Meta採用下列兩項技術:
首先,Meta以Nvidia NCCL的負載平衡集體傳輸庫(collective library),做為基礎,在2個GPU之間建立與維持16個網路流,不像一般只有1個網路流,藉此可減少每個網路流的流量,並為負載平衡工作提供更多可操作的網路流。
其次,利用增強型ECMP協定(E-ECMP),為RoCE封包標頭的附加欄位進行雜湊處理(hashing),從而可以在不同網路路徑上,有效地平衡GPU與GPU之間的16個網路流。
● 壅塞管理
Meta最初是採用傳統的DCQCN(資料中心量化壅塞通知)來進行壅塞控制,但發現在400Gb網路上效果不佳。
於是Meta放棄DCQCN,改在主幹網路(Spine)交換器,也就是CTSW交換器這一層,使用深度緩衝技術(Deep-buffer),利用GPU的HBM記憶體來維持多個傳輸通道,作為傳輸緩衝區,因應多處理器集體通訊引起的瞬間壅塞。
Meta表示,這種作法有助於限制陷入慢速的伺服器,所導致的壅塞與網路背壓(network back pressure)衝擊,這種情況在訓練過程中很常見。
此外,藉由E-ECMP協定實現更好的負載平衡,也顯著降低壅塞的可能性。
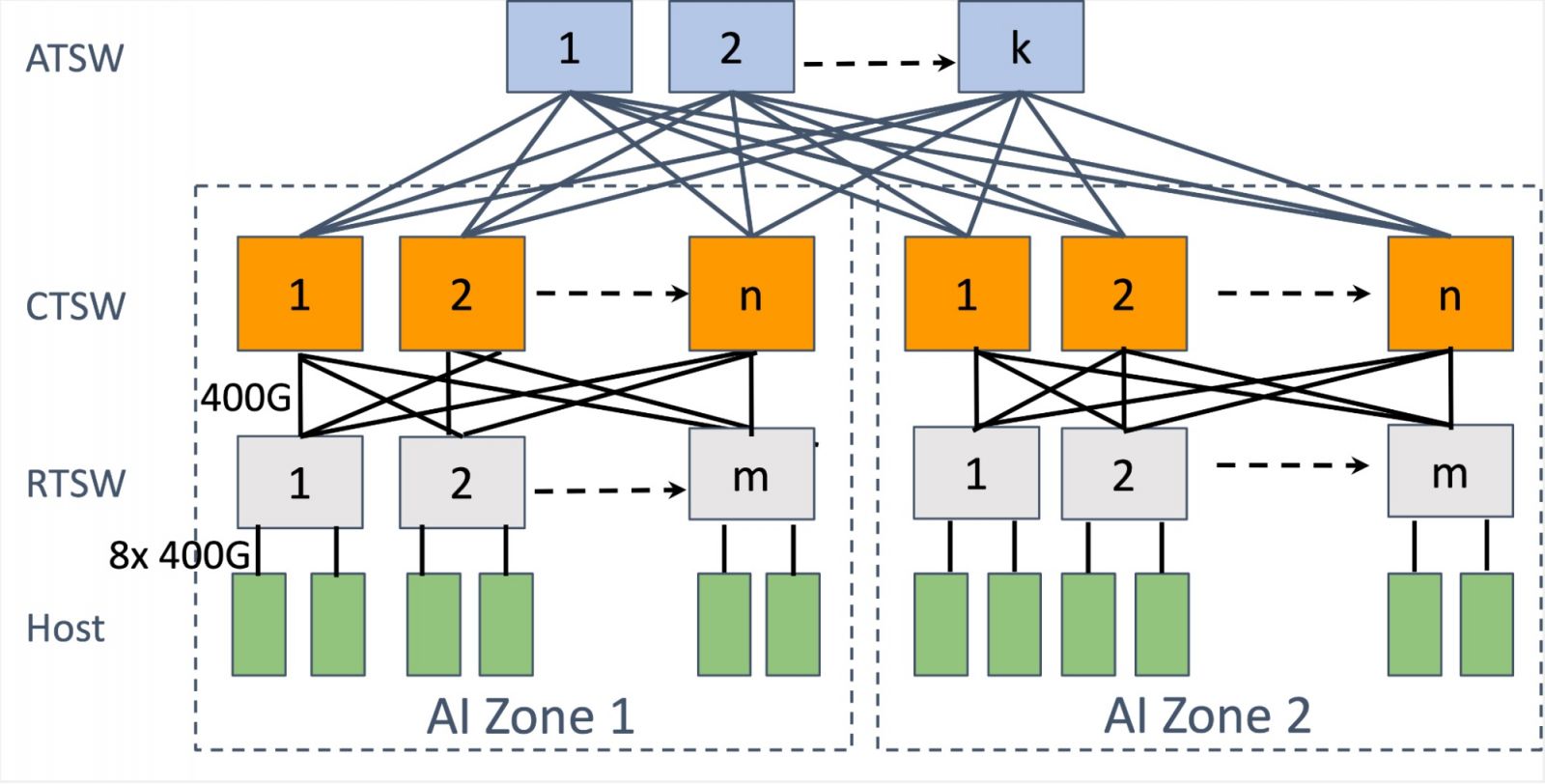
Llama 3訓練基礎設施的GPU後端網路拓樸
後端網路一共分為3層,最底層是伺服器層級的互連,每2臺AI主機,也就是Grand Teton AI伺服器,各自透過8條400G網路連接到機架上的機櫃訓練交換器(RTSW)。
中間層是跨機櫃的互連,機櫃的訓練交換器(RTSW)接到上一層的叢集訓練交換器(CTSW)上,組成跨機櫃的GPU互連網路。而192座機架藉由CTSW交換器的連結,構成1組包含3,072個GPU的Pod單元,這應該也是一個AI區域(AI Zone)的最大單位。
最上層則是跨AI區域的互連,利用聚合訓練交換器(ATSW)連接不同AI區域的CTSW交換器,建立跨AI區域、跨Pod單元間的互連。圖片來源/Meta
持續擴張中的AI運算環境
無論就規模或運算力,Meta 24k GPU叢集都是當前AI訓練基礎設施的頂點,儘管如此,這還未達到Meta幾年前設定的目標。Meta在2020年曾提出AI運算基礎設施目標:在1EB容量的資料集上、訓練擁有1兆個參數的模型,而目前Llama 3的規模,以及24k GPU叢集的能力,離這個目標都還有一段差距。
因此Meta目前的2座24k GPU叢集,只是該公司新一代AI訓練基礎設施建設的起步,仍在持續擴充,近期目標,是在今年年底時將35萬個H100 GPU納入AI基礎設施,屆時Meta的AI基礎設施資產將擁有相當於60萬個H100運算能力。
前述訊息是在今年3月發表,這意味著,Meta將以每個月近4萬個H100 GPU的速度,持續擴展運算能力。
不過,其他廠商也在快速追趕!
例如,馬斯克(Elon Musk)在今年4月曾透露,旗下AI新創公司xAI發展的Grok-2模型,訓練時使用2萬個H100 GPU,這樣的規模,與Meta的Llama 3模型訓練使用的24k GPU叢集,大致在伯仲之間。稍後馬斯克5月又聲稱將大肆購買Nvidia晶片,以滿足xAI下一代Grok-3模型需要的10萬個H100需求,這套新設施預定在2025年秋季打造就緒。
其他第一線大廠也有同等規模的AI硬體擴充計畫,例如,微軟Azure技術長Mark Russinovich 5月表示,他們正以每個月部署5座Eagle超級電腦的速度,擴展旗下基礎設施運算能力。Eagle是擁有14,400個H100 GPU、在TOP500名列第3的超級電腦,這意味著Azure的運算能力擴充速度,相當於每個月增加7萬個H100 GPU,比起Meta更為驚人。
從各大廠商競相擴充GPU部署規模,也可看出大語言模型對GPU運算能力需求,是如何迫切。以目前來看,為了支撐大語言模型的進一步完善,這股AI基礎設施建置熱潮,還會持續好幾年。
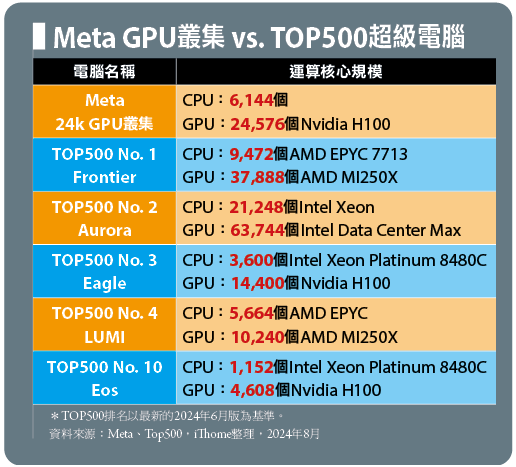
當前最頂級的高效能運算環境:與TOP500對比
Meta用於Llama 3模型訓練的24k GPU叢集,不僅是當前最高效能的AI研究用超級電腦,事實上也是最快的超級電腦之一。
談到全球頂級的高效能運算基礎設施,多數人首先想到的,便是名列TOP500榜單的超級電腦。然而用於自然語言處理、大語言模型等AI研究用的大型運算設施,雖然應用面向與這些超級電腦略有差異,但是在效能與規模上,其實不比這些超級電腦遜色。
我們將Meta 24k GPU叢集的運算核心規格,與TOP500榜單中幾臺較知名的超級電腦運算核心規格,列於下表當中進行對比。由於Meta並未公布24k GPU叢集使用的CPU型號,所以我們無法計算總核心數,而只能比較CPU與GPU數量,但即便如此,24k GPU叢集的處理器規格與數量規模,確實可與TOP500前3名超級電腦媲美,甚至猶有過之。

熱門新聞

2026-02-02

2026-02-03

2026-02-04

2026-02-02

2026-02-04


2026-02-03

2026-02-05