
Meta透過論文《The Llama 3 Herd of Models》公布訓練Llama 3的基礎設施硬體架構細節。(https://tinyurl.com/2d5pkww5)
談到超大型AI運算設施的維運,多數人首先想到的,便是滿足大量GPU運作所帶來的供電與散熱問題,但Meta的經驗顯示,即便滿足了供電與散熱需求,大規模AI運算叢集的維運,仍面臨效能調校與穩定性方面的巨大挑戰。
Meta用於Llama 3大語言模型訓練的「24k GPU叢集」,是當前規模最大,效能也最高的AI運算設施,擁有2.4萬個GPU、6,000個CPU與3,000臺AI伺服器。
不過龐大的系統規模,是Meta的Llama 3硬體基礎設施最引人注目之處,也是執行大語言模型訓練不可或缺的基礎。但另一方面,足夠的系統規模,只是執行這類應用的必要門檻,而不能保證運算工作能順利進行,並獲得期望的成果,想要讓這類超大規模基礎設施充分發揮效益,還需要仔細的調校,並維持足夠的穩定性。
效能調校與可靠性的確保至關重要
首先,一味地擴大基礎設施的規模,並不保證整體效能成比例的增加,若未經妥善調校,將只是徒然浪費基礎設施資源而已。
Meta提出實例指出,相較於經過最佳化調校的小型AI叢集,大型AI叢集一開始的效能表現很差,而且很不穩定。
小型叢集的通信效能(整體通訊頻寬利用率)可以維持在90%以上,大型叢集的通信效能則在10%到90%間跳動,無法發揮規模擴大的效能,直到Meta調整作業排程器 軟體、依網路拓樸動態的工作調派機制,並更動網路路由策略後,才讓大型叢集的通信效能恢復到90%以上。
其次,眾所周知,AI叢集這種超大型高效能基礎設施的營運成本十分昂貴,若系統穩定性不足,將導致運算作業頻繁中斷,造成操作成本的無謂增加。
但不幸的是,Meta的經驗顯示,相較於傳統以CPU為核心的大型叢集,GPU為核心的大型叢集,相對更不穩定。Meta在其論文中指出,Llama 3訓練用的16k GPU叢集,複雜性與潛在故障情境,都超過更大規模的CPU叢集,而且容錯能力也較低,因為如果發生單一GPU故障的狀況,就有可能導致作業中斷,而需要重新啟動。
GPU叢集頻繁的硬體故障
Meta在論文《The Llama 3 Herd of Models》,以為期54天的Llama 3 405B版模型訓練為例,16k GPU叢集訓練的過程中,共發生466次工作中斷,裡面就有47次,是系統更新或維護造成的中斷,叢集每天都會因預設的維護與更新,至少中斷1次,其餘419次是意外中斷,這樣換算起來,平均每天發生將近8次意外中斷,也就是說,訓練作業每天都會被意外狀況打斷數次。
而在這419次意外中斷事件中,78%的狀況都歸因為硬體問題,GPU相關問題是最大宗,占所有意外中斷因素的58%,故障次數最多的是GPU本身失效(148次,占30.1%),然後是GPU的HBM3記憶體失效(72次,占17.2%),其他GPU相關問題還有GPU的SRAM記憶體與系統處理器失效(19次與17次,4.5%與4.1%)。在GPU類別的問題之外,故障次數較多的是交換器與纜線問題(35次,8.8%)。相較下,CPU、系統記憶體、SSD、電源供應器這些傳統伺服器元件的故障率低了許多,訓練期間只發生過2、3次故障。
Meta還提及外部環境對於GPU作業,以及GPU作業對整體電網的影響。Meta發現在一日之中,隨著時間的推移,訓練作業的吞吐量會有1到2%的變化,而這種吞吐量波動,是受到外部環境氣溫變化對GPU運作的影響導致。例如,在中午時分的高溫下,會影響GPU運作的動態電壓與頻率縮放。
使用大量GPU執行模型訓練作業,也會衝擊資料中心電網。數以萬計的GPU,很可能會同時增加或減少功耗,例如一同等待檢查點寫入或集體通訊作業完成、或訓練作業的啟動與關閉等,Meta表示,當這種情況出現,將導致整個資料中心的功耗,瞬間出現數十MW等級的波動,以致超出電網限制。
緩解硬體故障的手段
Meta營運這套AI環境的經驗指出,GPU固然是大語言模型訓練硬體基礎設施核心,卻也是最脆弱、最不可靠的環節,易受外部環境溫度影響,還有衝擊整體電網之虞。
隨著GPU複雜性的持續增加,這種情況未來可能也難有顯著改善。
不過,Meta對此並非完全束手無策,透過自行開發的快速診斷與自動復原工具,幫助他們迅速確認GPU叢集的問題,並自動排除故障,而這種方法也收到良好的效果。Meta表示,儘管他們在模型訓練的期間曾遭遇大量故障的狀況,但其中只有3次需要人工干預,其餘問題都可透過工具自動處理。最終,Meta達到了90%以上的有效訓練時間(在總操作時間中,有效執行訓練時間的比例)。
這也顯示,透過操作層面的自動化偵測與復原工具,對於硬體層面高度複雜性導致的先天不可靠問題,能夠一定程度地予以緩解,雖然難以避免硬體故障發生,但仍有辦法盡量減少故障的衝擊,與作業中斷時間。
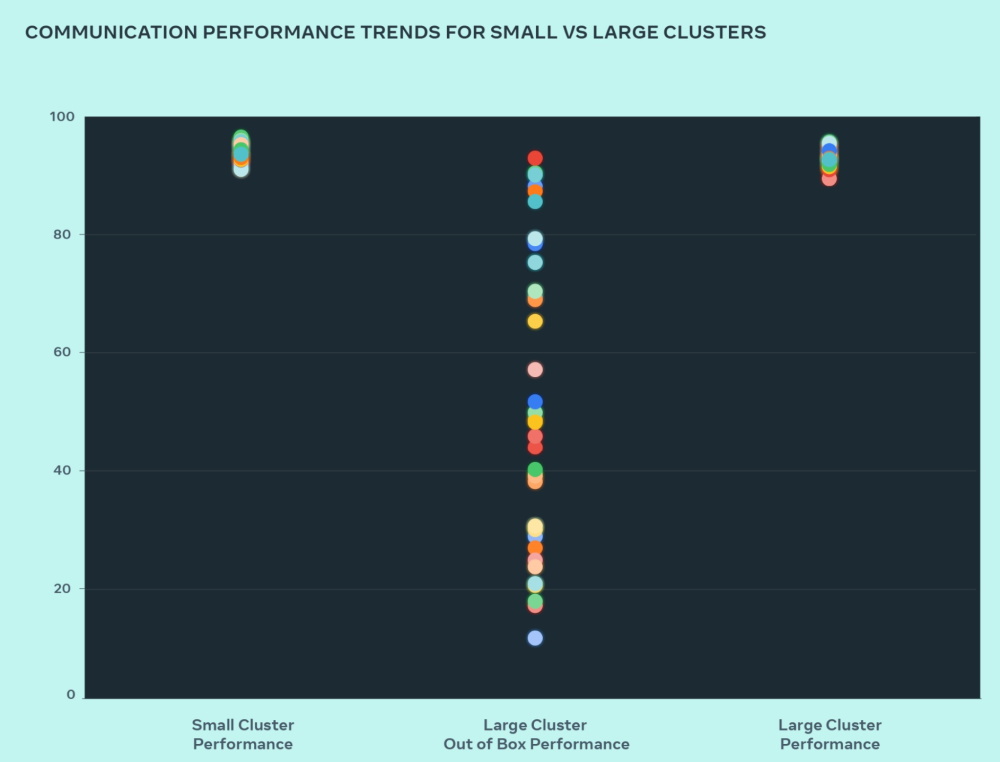
Llama 3訓練用叢集的調校
效能調校對於大型叢集效能相當重要,Meta舉例表示,相對於能發揮90%的通信效率的小規模叢集,大型叢集一開始的效率很差,表現也不穩定,通信效率在10%到90%間跳動,經過調校後,才得以獲得90%以上的通信效率。圖片來源/Meta
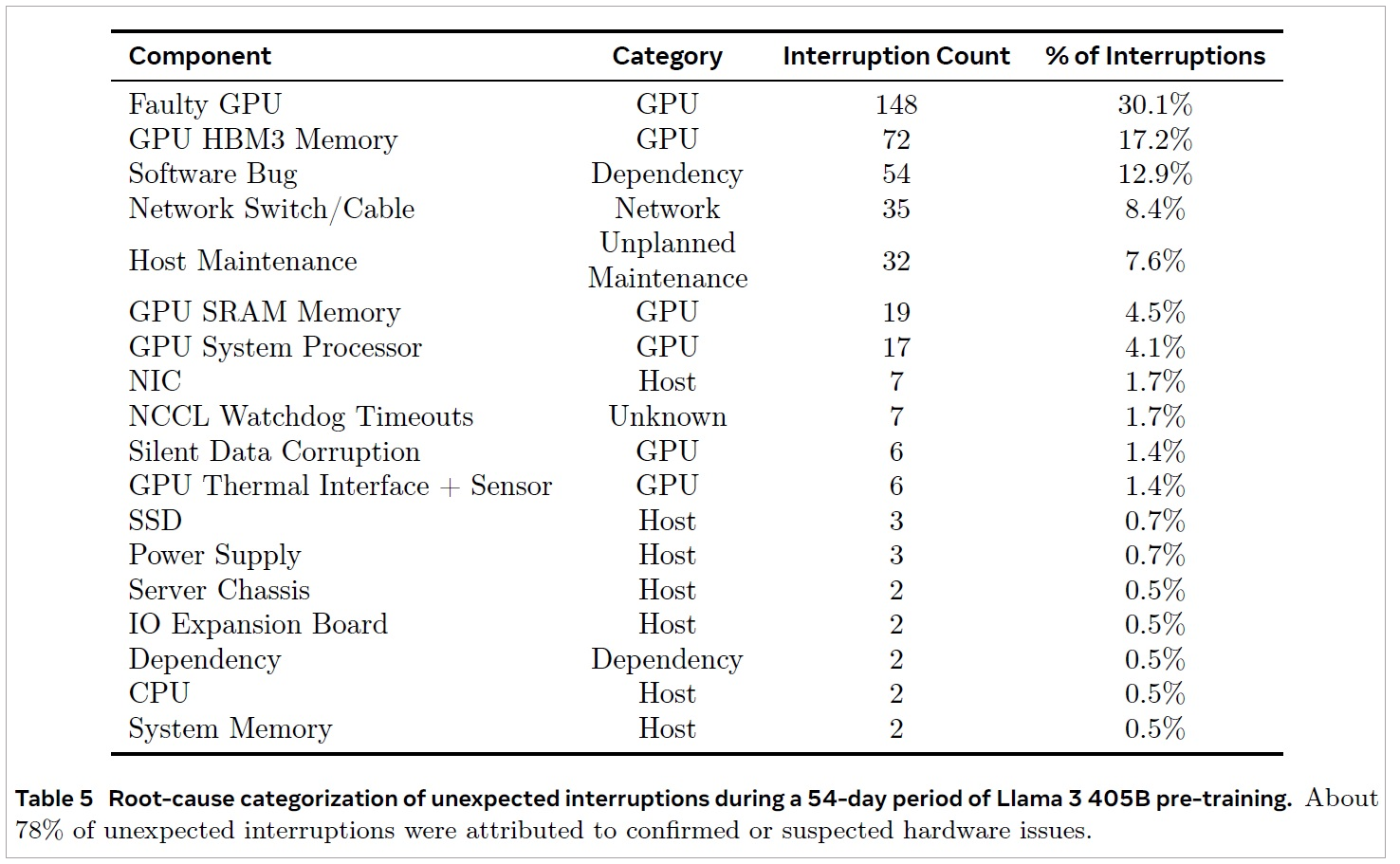
GPU叢集的脆弱性
Meta以一次為期54天的Llama 405B模型訓練為例,說明大型GPU叢集遭遇的可靠性問題,這次訓練過程中發生了419次意外中斷,相關故障原因如上表所示,可見到GPU相關類型(Category)的故障次數最多,占了將近6成,可說是叢集中最不可靠、最脆弱的環節。圖片來源/Meta

熱門新聞

2026-02-02

2026-02-03

2026-02-04

2026-02-02

2026-02-04


2026-02-03

2026-02-05