Nvidia
在Nvidia的一系列GPUDirect傳輸技術中,GPUDirect Storage(GDS)是作為儲存裝置與GPU之間的傳輸加速用途,在AI應用的資料流框架中,原本是最後端、外圍的角色,只在最初的資料饋入,與最終的寫入保存運算結果時派上用場,但隨著AI應用的資料量持續暴漲,也讓GDS的重要性跟著水漲船高。
為此,我們去年(2023)12月的封面故事「GPU直連I/O傳輸架構的崛起」,曾初步介紹GDS傳輸加速架構的運作概念,與當時儲存業界的支援情況,如今GDS的相關應用又有一連串顯著進展。
首先,過去幾個月以來,又有多家重要儲存廠商加入GDS支援行列,或是發表支援GDS的新產品,使得力挺GDS的廠商與儲存產品數量一舉超過20個,涵蓋所有一線大廠與重要新創廠商,以及不同層級的儲存產品與裝置。其次,各儲存廠商也紛紛以GDS模式下的傳輸效能數字,標榜自身產品的AI應用效能,因此,GDS儼然成為衡量AI應用中的儲存效能基準。這些新發展,也促使我們再次回到這個議題。
在檢視GDS應用的新發展之前,我們首先簡單回顧GDS的基本概念,以及運作方式。
克服GPU運算時代的I/O瓶頸
GDS這項技術誕生的遠因,是為了因應GPU運算時代,效能瓶頸從運算力轉移到I/O的現象。
過去基於CPU為核心的運算環境中,資料處理的主要瓶頸在於CPU的運算能力,I/O相對不是大問題;而在今日基於GPU的運算環境中,由於GPU的運算能力提升幅度,大於I/O吞吐能力的提升,反而讓I/O成為整個資料處理過程中的效能瓶頸所在。必須同步提高I/O效能,才能有效改善整體處理能力。
GDS這項技術誕生的近因,則是AI應用資料量持續暴漲的結果。
儲存裝置在AI應用中的主要任務,是負責向運算單元饋入訓練資料集,以及寫入與保存運算結果。但隨著AI訓練的資料集容量持續增加,從儲存裝置將資料載入到GPU,所需時間也越來越長。
如此一來,從本地端儲存裝置到GPU之間的資料傳輸,以及從外部儲存設備到GPU伺服器之間的資料傳輸,成為制約AI應用的效能瓶頸所在,如果儲存設備向GPU載入資料的速度過慢,將會大大拖累整體處理速度。這也促使Nvidia在2019年推出GDS架構,以提高從儲存設備到GPU伺服器之間的傳輸效率。
AI應用環境的I/O需求
大語言模型、1080P高畫質影像訓練的資料集,動輒就能達到TB或數十TB等級,不可能完全預先載入GPU伺服器的記憶體,而需多次從內部或外部儲存裝置讀取,因而會對儲存裝置帶來龐大的讀取流量需求;為了確保訓練過程中的容錯需求,也需要定期寫入檢查點,從而為儲存裝置產生TB等級資料的龐大寫入流量。
所以,儲存裝置也必須確保足夠的傳輸效能,才能讓AI訓練工作有效率的執行,這也正是GDS的目的。
在Nvidia的DGX SuperPOD參考架構文件《NVIDIA DGX SuperPOD: Next Generation Scalable Infrastructure for AI Leadership Reference Architecture Featuring NVIDIA DGX H100》,就針對資料集較龐大、無法直接載入快取記憶體的AI訓練工作,建議應啟用GDS架構,提供更高的持續傳輸速度,從而發揮最佳的AI訓練效能。
事實上,上述這份文件,推薦適用於大型AI模型訓練所需的「最佳」(Best)儲存效能指標——單一節點可提供40GB/s以上讀取效率,以及20GB/s寫入效率,理想目標是盡可能接近80GB/s的網路最佳效能,然而,目前也只有在GDS架構的幫助下,才能有效率地實現這個目標。
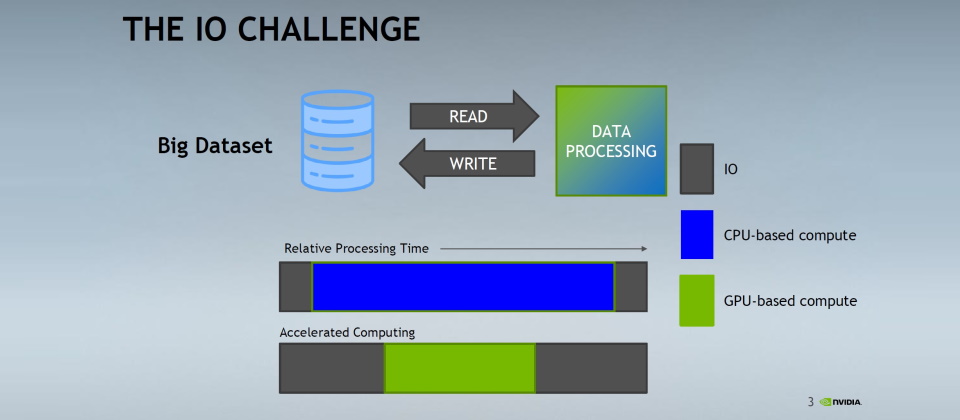
效能瓶頸的轉移:CPU運算 vs. GPU運算
-600.jpg)
關於資料處理的過程,我們可以簡單分解為資料的讀取載入、運算,以及寫入運算結果等3個步驟。
在以往基於CPU的運算環境,資料處理過程的大部分時間,都耗費在運算,資料讀取與寫入占用的時間比重有限,瓶頸往往落在運算這一環節,I/O相對不是大問題。
而在今日基於GPU的運算環境中,依靠GPU大幅縮減運算處理時間,也使得整個資料處理過程中,I/O耗費時間的比重大幅增加,成為新的瓶頸所在。圖片來源/Nvidia
GDS打破傳統傳輸架構的限制
在傳統的伺服器I/O架構下,如果我們要從GPU伺服器的本地端儲存裝置,將資料傳送給GPU當中處理時,資料會先經由GPU伺服器的PCIe交換器,複製到伺服器CPU記憶體的回彈緩衝區(Bounce Buffer),後續再複製到GPU記憶體。
若要從外部儲存設備傳送資料到GPU,則會經由GPU伺服器的網路卡與PCIe交換器,先將資料複製到伺服器主機CPU記憶體的回彈緩衝區,再複製到GPU記憶體。
在這樣的資料傳輸路徑中,存在2個效能瓶頸:
延遲增加
將資料從儲存裝置傳送到GPU的過程,需要經過至少3到4個環節的中介,內接SSD會經過PCIe交換器、主機CPU、與系統記憶體等3個環節,外部儲存設備還會多經過網路卡這個環節。而這整個過程中,還須進行至少2次記憶體資料複製——先複製到主機CPU記憶體回彈緩衝區,再複製到GPU記憶體,資料才能為GPU存取,因而增加了延遲,也會耗費許多CPU操作週期,增加CPU負荷。
傳輸頻寬受限
儲存裝置將資料傳送到GPU的過程中,傳輸率會受到GPU與CPU之間的PCIe傳輸通道頻寬制約。
這個問題主要是出現在一些較舊款的GPU伺服器,如搭配A100、V100等GPU平臺的伺服器,主機CPU連接PCIe交換器的傳輸頻寬,只有GPU的PCIe傳輸頻寬一半,因而若資料傳輸路徑通過CPU,那麼傳輸率就會受限於CPU的PCIe傳輸頻寬。
直接記憶體存取(DMA)技術突破效能瓶頸
從儲存裝置向GPU傳送資料的過程中,須經由主機CPU與記憶體的中介,正是形成效能瓶頸的原因所在,解決辦法就是盡量不讓資料繞經這個環節,而是直接讓儲存設備將資料傳送到GPU,亦即應用直接記憶體存取(Direct Memory Access,DMA)技術。
而Nvidia的GDS傳輸加速架構的基本概念,就是儲存裝置透過直接記憶體存取(DMA)技術,直接經由PCIe交換器晶片將資料寫入GPU記憶體,繞開GPU伺服器主機CPU。如此一來,既能減少延遲,又能利用到GPU的最大傳輸頻寬。
GDS省略將資料複製到主機記憶體(即回彈緩衝區)的過程,因而能顯著減少延遲。另一方面,由於主機CPU不參與資料傳輸作業,也能減輕主機CPU的負荷。最後,儲存裝置到GPU之間的傳輸效能,也不會受到主機CPU的PCIe傳輸通道頻寬限制。
GDS傳輸架構的價值
Nvidia宣稱,透過GDS可獲得2倍以上的資料傳輸頻寬提升,並降低存取延遲與CPU負荷。而相關廠商的實測報告,也印證GDS的效能提升效果。
如VAST Data所提供的測試數據顯示,他們的儲存平臺透過8個InfiniBand埠將資料載入Nvidia DGX-2,啟用GDS可讓持續傳輸率提高近3倍(從33 GB/s提高到94 GB/s),CPU負荷減輕將近85%(CPU利用率從99%降到15%),證實GDS提高傳輸率、減少主機CPU負荷的效果。
美光的測試報告,進一步突顯GDS在高負載環境的效能改善效益。
該公司以9400 NVMe SSD搭配Nvidia DGX A100系統進行的實測顯示,比起傳統I/O架構,GDS在4KB小區塊傳輸下,可提升33%的傳輸率,並減少25%回應時間,在1024KB大區塊傳輸測試中,則有16%的傳輸率與回應時間改善。數字雖然看來不錯,但似乎不如Nvidia宣稱那樣大幅度的提升,然而美光的報告顯示,GDS的真正價值,其實是在主機處於高負載的繁忙情境。
前述測試數字是在主機處於閒置狀態、沒有其他工作負載的效能表現,但實際應用並不會如此,用戶往往必須在主機處於訓練工作的高負載情況下,同時讓儲存裝置向主機傳送資料,資料傳輸工作會面臨與其他工作負載爭搶主機CPU與記憶體資源的困境,導致效能大受衝擊。此時若有GDS這種繞過主機CPU與記憶體的存取架構,便能維持一定程度的傳輸能力。
美光模擬了主機CPU處於86%的高利用率,CPU的記憶體頻寬利用率也達到50%的情境,此時利用傳統I/O架構進行傳輸作業,效能將變得極為低落,GDS則仍能維持相當程度的運作。在最消耗主機資源的4KB小區塊傳輸測試中,GDS仍能提供相當於理想狀態一半的傳輸率與回應延遲表現,相較同樣環境中的傳統I/O架構,GDS的效能與傳輸率足足高出7.3倍與6.4倍。而在相對較不消耗主機資源的1024KB大區塊傳輸測試,GDS的回應時間雖然增加2倍,但傳輸率幾乎不受影響,比起傳統I/O架構,傳輸率與回應延遲都改善1.5倍。
迅速擴展中的GDS應用環境
Nvidia是在2019年中發表GDS技術架構,2020年底推出正式的第1版軟體,隨後便在2021年湧現了第一波儲存廠商支援熱潮,DDN、Dell、Hitachi Vantara、HPE、IBM、VAST Data、Weka、ScaleFlux等儲存廠商,都是在這個時期,將GDS納入自身產品平臺的傳輸架構支援。
到了2022與2023年,GDS支援產品的擴展速度稍有減緩。2022年只增加NetApp、Kioxia,但NetApp是先後以2種平臺參與對GDS的支援,2023年有華為、美光、PEAK:AIO,HPE也在此時增加了第2種支援GDS的平臺。
在我們去年底首次介紹GDS時,市場上支援GDS的廠商大致就是以上這些。不過在這個時間點之後,GDS的產品支援擴展速度又開始加快。
首先是Pure Storage在2023年底宣布支援GDS,並獲得Nvidia認證。當時間進入2024年後,Hammerspace、WD分別在年初與年中,加入支援GDS的行列,HPE也在2024年中時、新增旗下第3種支援GDS的儲存平臺,Nutanix亦在7月預告,他們的儲存平臺也即將加入GDS的支援。
最近發布的GDS相關產品消息,則是Pure Storage在9月底發布的新產品FlashBlade//S100規格,也列入GDS的支援,是目前最新一款支援GDS架構的產品。
躋身AI應用的標準儲存傳輸架構
儘管儲存界支援GDS的聲浪浩大,然而,並非所有儲存廠商都認同GD這項技術,例如高效能物件儲存系統供應商MinIO便聲稱,他們的平臺利用標準乙太網路,就能提供足夠的傳輸效能,無需使用GDS,從而避免使用InfiniBand或RDMA架構所帶來的複雜性。
MinIO認為自身的部署經驗顯示,GPU應用環境的I/O瓶頸在於網路通道頻寬,而不在於傳輸路徑是否使用回彈緩衝區,因而GDS並非是必要的架構。
但MinIO只是少數派,多數主要儲存廠商都認同GDS的價值,並積極支援GDS技術,持續增加的GDS支援廠商便是證明,也讓GDS逐漸成為AI應用必備的傳輸架構。
當前AI應用的熱潮仍持續不減,考慮到Nvidia GPU在AI應用中的關鍵地位,以及GDS所能提供的傳輸效能提升效果,我們可以很肯定地認為:任何想要在AI應用中扮演重要角色的儲存廠商,都必須支援這套傳輸架構,才能具備足夠的競爭力。
GPUDirect Storage的適用場合
藉由GPUDirect Storage(GDS)所帶來的I/O傳輸加速效益,並非所有場合都有效,必須是在I/O密集型環境,以及不涉及CPU處理的情境中,才能發揮作用。
首先,GDS針對的是儲存設備到GPU之間的I/O瓶頸問題,如果I/O不是應用環境的瓶頸,GDS自然沒有幫助。例如在不涉及大量資料傳輸的運算密集型環境,運算耗費的時間遠大於資料傳輸時間,或運算工作無須等待I/O完成的非同步I/O環境,由於I/O並不是這些應用的瓶頸,GDS便無法發揮效益。
其次,GDS僅有助於儲存裝置到GPU之間的傳輸,GPU必須是應用程式資料傳輸過程第1個或最後1個接觸的環節,GDS才能發揮助益。若應用程式在GPU運算之前或之後,還需使用主機CPU處理或分析資料,將會消除GDS的效益。
反之,如果是涉及大量資料傳輸,且能卸載給GPU執行的應用情境,GDS便能發揮顯著的加速效果,AI模型訓練便是這種情境的典型。

熱門新聞

2026-02-06
")
2026-02-09
")

2026-02-06
")
2026-02-09

2026-02-06

2026-02-06