美光Micron
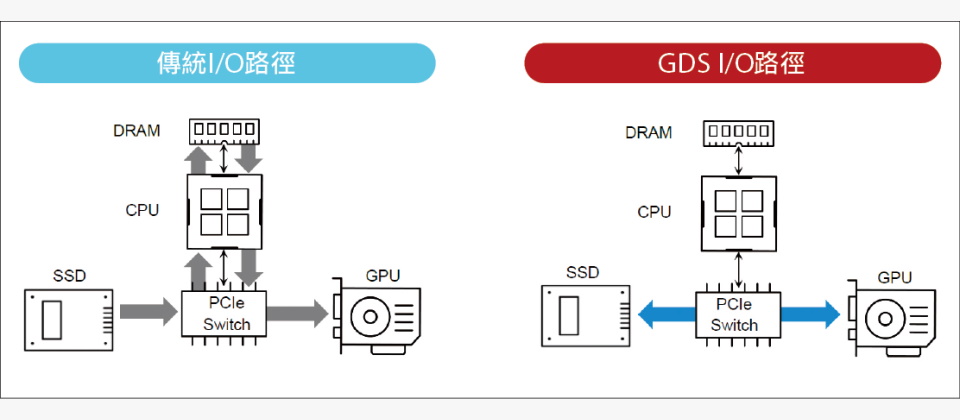
下圖是從SSD向GPU傳送資料的傳統I/O路徑,資料會經由PCIe交換器、經過主機CPU、複製,寫入主機記憶體的回彈緩衝區(bounce buffer),再經由CPU、PCIe交換器,複製寫入GPU的記憶體,供GPU存取。這整個過程需要經過6個環節,以及2次資料複製作業。
-600--1.png)
圖片來源/美光Micron
之所以必須採用這種繁瑣的傳輸路徑,是一系列原因造成的。
在儲存裝置與GPU之間的資料移動,是透過CPU運行的系統軟體驅動程式來管理,並可由下列3種方式來執行傳輸作業,但各有限制:
(1)經由GPU的直接記憶體存取(DMA)引擎執行資料傳輸工作,但是,第3方周邊裝置通常不會公開其記憶體給其他裝置的DMA引擎定址,因而GPU無法以其DMA引擎直接存取第3方的周邊裝置,只有主機CPU的記憶體可供GPU DMA引擎存取。這也導致第3方周邊裝置向GPU的資料傳輸路徑,必須經過主機CPU記憶體中的回彈緩衝區,來作為中介。
(2)經由CPU的載入與儲存指令來執行資料傳輸,但CPU無法在2個周邊裝置之間直接複製資料,而須經由CPU記憶體回彈緩衝區的中介。
(3)經由周邊裝置的DMA引擎來執行資料傳輸,如NVMe SSD、網路卡或RAID卡的DMA引擎,而GPU的PCIe基底位址暫存器(PCIe Base Address Register,BAR)的定址,是可以提供給其他周邊裝置DMA引擎存取的,Nvidia的GPUDirect RDMA技術,就是利用這點來實現GPU與網路卡之間的直連存取。
問題在於,若存取的目標是檔案系統層級的儲存裝置,就必須由作業系統介入存取過程,但作業系統並不支援將GPU的虛擬定址傳遞給檔案系統,因而無法執行DMA存取。
傳統I/O路徑會帶來下列3個副作用:(1)延遲增加;(2)傳輸效率受CPU的PCIe通道頻寬限制;(3)傳輸作業需耗費CPU週期,增加CPU與主機記憶體負擔,並與其他工作負載爭搶CPU資源與主機記憶體頻寬,導致傳輸率的抖動與不穩定。
-600--2.png)
圖片來源/美光Micron
上圖是在GDS架構,從SSD向GPU傳送資料的I/O路徑,可以繞過(Bypass)主機CPU與記憶體,讓SSD直接透過PCIe交換器,以DMA方式將資料複製寫入GPU的記憶體,整個過程只需經過2個環節,以及1次資料複製,從而帶來3項直接效益:(1)避開主機CPU的PCIe通道頻寬限制;(2)減少傳輸過程的環節,降低延遲;(3)降低主機CPU與記憶體的負擔,減少資料傳輸作業對於其他工作負載的影響。
除此之外,GDS架構還能帶來幾項附帶的效益:
(1)透過額外的PCIe傳輸通道提高傳輸頻寬:當資料傳輸無須繞經主機CPU與記憶體,只需在PCIe交換器與周邊裝置之間進行時,若搭配採用多層PCIe交換器,同時啟用多條傳輸通道,將能顯著提高伺服器整體傳輸頻寬。
而在傳統I/O架構下,由於資料傳輸必須經由主機CPU與記憶體,頻寬會被主機CPU的PCIe通道給綁住,即便有多層PCIe交換器,也無法獲得頻寬提高的效果。
(2)解放主機記憶體的占用:資料傳輸使用的回彈緩衝區,會占用到相當可觀的主機記憶體容量,有時候甚至多達1TB,GDS則能解除資料傳輸作業對寶貴主機記憶體空間的占用。

熱門新聞
")
2026-02-09
")

2026-02-06

2026-02-06

2026-02-06


2026-02-06

2026-02-06