iThome
生成式AI技術的興起,帶來AI訓練資料量的大幅增長,大語言模型(LLM)訓練的資料集,動輒達到TB或數十TB等級,對於較具規模的AI應用環境,保有數百TB甚至PB等級的訓練資料集,都已是現實。
而隨著AI訓練使用的資料量持續暴漲,也促使當前AI應用的瓶頸,逐漸從運算能力轉向I/O吞吐能力。低落的後端網路效率,將會導致GPU運算能力的極大浪費。
如AMD在不久前的Advancing AI大會中便舉例指出,在當前AI模型訓練過程中,平均有30%的時間是耗費在等待網路傳輸上,在一些較極端的例子中,網路傳輸耗時占訓練時間的比例,甚至達到40%到75%。
因而如何提升I/O傳輸速度,以便在GPU伺服器與儲存裝置之間,更有效率地傳輸龐大的資料,已成為與擴展運算能力同等重要的AI應用議題,也是當前儲存與網路業界的技術發展焦點之一。
儲存裝置向GPU伺服器傳送資料的效率,涉及儲存設備本身的輸出能力,以及傳輸通道的效能。
當前的主流儲存設備大多可透過橫向擴展的叢集架構,藉由大量節點匯聚出龐大的輸出能力,因而傳輸瓶頸通常是落在傳輸通道方面,常見的改善手段有下列兩種:
一種是從上層的應用程式軟體著手,在儲存裝置與GPU之間建立直接記憶體存取架構,藉此減少傳輸環節,達到減少存取延遲的效果。這方面最典型的應用,便是Nvidia的GPUDirect Storage直連傳輸技術。
另一種是從底層的網路硬體著手,升級網路基礎架構,包括採用傳輸頻寬更高的網路規格,或是改進的傳輸協定,從而達到提高吞吐率、減少存取延遲的效益。例如引進400 GbE、800 GbE規格網路、以及使用基於RDMA架構的RoCE協定等。
過去2年來,我們對AI應用I/O架構議題的關注,主要是放在GPU直連架構方面,陸續在2023年12月的封面故事《GPU直連I/O崛起》,與2024年10月的封面故事《企業儲存市場新動能:GPU直連儲存系統》,以Nvidia的GPUDirect與GPUDirect Storage技術為中心,針對Nvidia發展的一系列GPU直連傳輸架構,介紹AI資料傳輸加速技術的應用現況。
關於新一代網路架構的探討與追蹤方面,我們在2024年8月封面故事《2024資料中心I/O架構新面貌》,概略檢視了AI應用主流網路架構的發展現況,包括乙太網路與InfiniBand等技術。
近兩、三個月以來,針對改善AI應用I/O傳輸效率的需求,儲存與網路領域又有了一系列新進展,分別涵蓋GPU直連傳輸應用,以及基礎網路架構等兩個層面,也促使我們很快又再次回到這個領域,檢視這些新發展。

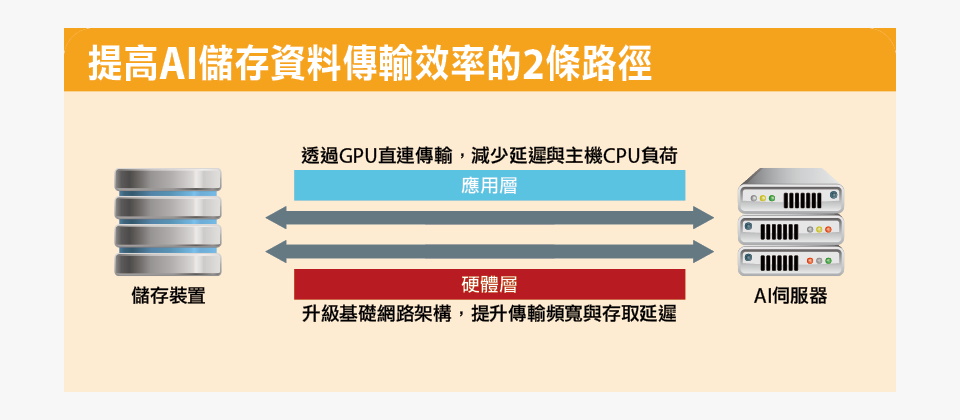
提高AI儲存資料傳輸效率的2條路徑
要改善儲存裝置饋送資料給AI伺服器的傳輸效能,一般可從兩條途徑著手。
一是從上層的應用程式著手,在儲存裝置與GPU之間建立直接記憶體存取(DMA)架構,使儲存裝置能直接將資料載入GPU記憶體,繞開AI伺服器主機CPU的中介,從而減少存取延遲,降低CPU負擔,最典型的應用架構,便是Nvidia的GPUDirect Storage(GDS)。
二是從底層的基礎網路架構硬體著手,升級儲存裝置與GPU之間的網路架構,藉此可以擴展資料傳輸頻寬,並減少存取延遲。典型的做法如引進400GbE、800GbE等更高頻寬的網路,或是採用RoCE等低延遲網路傳輸協定。
資料來源:iThome整理,2025年1月
GPU直連傳輸生態系的再次擴展
在GPU直連傳輸應用方面,近來出現兩項關鍵進展
首先,是Nvidia GPUDirect Storage(GDS)傳輸架構的應用生態系,又有重要的擴展。幾家重量級IT廠商,包括:公有雲服務業者龍頭AWS、老牌企業儲存廠商Quantum等,都在2024年底,加入支援GDS架構行列,Nutanix也預告支援這項架構。
其次,有其他廠商加入戰局,推更多GPU直連儲存傳輸架構。
基本上,Nvidia GDS屬於檔案層級的資料傳輸架構,因而並不適用於物件(Object)儲存設備,這也限制了物件儲存設備在GPU應用環境中的效能表現。
令人意外的是,MinIO與Cloudian這兩家物件儲存廠商,不約而同地在2024年底,發表物件儲存層級的GPU直連傳輸架構,為GPU直連傳輸應用帶來重要的擴展,從GDS原本涵蓋的檔案儲存類型服務,如今得以擴展到物件儲存領域,讓GPU直連儲存傳輸架構能應用到更廣泛的環境中。
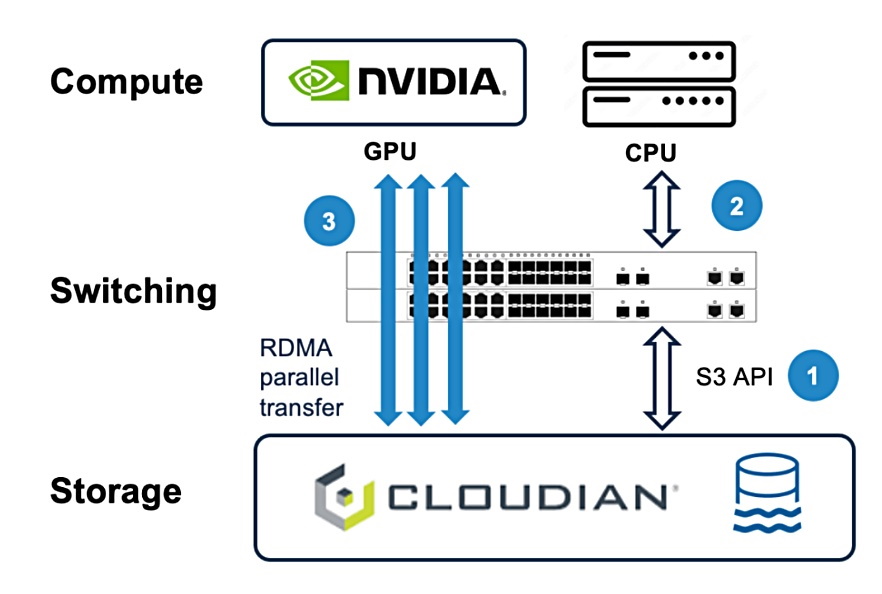
GPU直連儲存傳輸技術擴展到物件儲存領域
Nvidia的GPUDirect Storage是當前GPU直連儲存傳輸架構主流,但只適用於檔案層級,而MinIO與Cloudian則自行發展出物件層級的GPU直連架構,圖為Cloudian的GPUDirect for Object Storage,可在儲存設備與Nvidia GPU之間,透過S3物件儲存協定執行GPU直連儲存傳輸。圖片來源/Cloudian
新世代乙太網路的新進展
除了GPU直連傳輸,在更底層的基礎網路架構領域,也在2024年下半出現突破性進展。
GPU直連傳輸與基礎網路架構的升級,都能幫助AI資料傳輸效率的提升,但兩者的著眼點,與運作層次不同。
在網路通訊架構中,GPU直連傳輸應用屬於上層的應用層,是在既有的網路基礎架構下,透過直接記憶體存取技術來優化資料傳輸路經,達到減少存取延遲的效果,但所能達到的吞吐能力上限,取決於底層基礎網路架構的傳輸能力上限。
所以基礎網路架構的升級,是比GPU直連技術更為根本、也更釜底抽薪的改進傳輸效率手段。
如同高效能運算(HPC)領域,當前AI應用的主流基礎網路架構,也分為InfiniBand與RDMA乙太網路這兩種,其中,InfiniBand擁有效能與可靠性優勢,但成本相對高昂;乙太網路則勝在低成本,以及技術與產品普及,但效能與前者有顯著落差。
所以,追求極致效能的用戶,傾向選擇InfiniBand;對成本敏感的用戶,則只能選擇乙太網路。
有鑑於Nvidia在InfiniBand網路產品的壟斷,多家IT大廠集結、組成超級乙太網路聯盟(Ultra Ethernet Consortium,UEC),試圖從改進乙太網路協定著手,發展出足以與InfiniBand競爭的超級乙太網路傳輸(Ultra Ethernet Transport,UET)協定。
不過,UEC聯盟的規範制定工作出現遲延,UET協定仍未正式實用化的此刻,身為全球電動車龍頭廠商、同時,在自動駕駛與AI應用著力甚深的特斯拉(Tesla),便率先在改善乙太網路效能方面,提出開創性的成果。
在2024年8月的Hot Chips 2024大會,特斯拉發表基於乙太網路的新通訊協定TTPoE(Tesla Transport Protocol over Ethernet),在乙太網路底層堆疊上,結合新開發的資料傳輸層架構,大幅減少了資料傳輸延遲,從而能提供基於通用的乙太網路技術,但效能更勝既有的RoCE協定,使其成為足以與InfiniBand競爭的新協定,進而也在乙太網路與InfiniBand的規格競爭中,為乙太網路陣營注入一劑強心針。
而UEC聯盟透過發展UET協定,所希望達到的一部分目標,TTPoE已在一定程度上予以實現,並且已被實際用在特斯拉自身的Dojo超級電腦。
隨著特斯拉在Hot Chips 2024大會宣布將加入UEC聯盟,並將開放TTPoE協定,而有了這項協定之後,可望在未來的乙太網路發展中,發揮重要的作用,同時,也將大大改變AI與高效能運算領域的基礎網路架構生態。

熱門新聞

2026-02-02

2026-02-03

2026-02-04

2026-02-02

2026-02-04


2026-02-03

2026-02-05