
運用需求預測AI應該以新產品為目標。
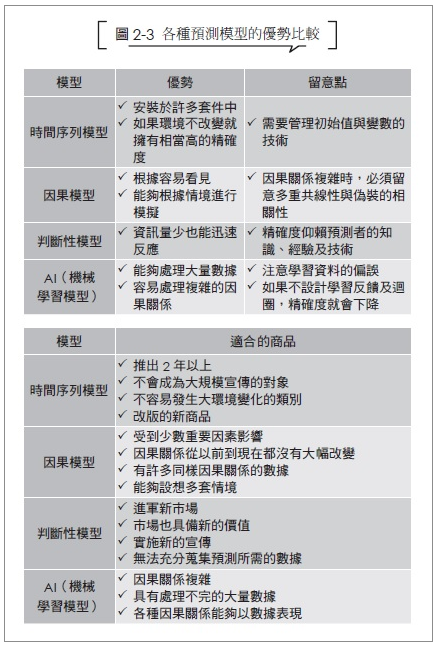
根據我的感覺,現有的商品存在著過去的數據,因此應用統計學的時間序列模型就足以預測其需求。這是基於預測精確度的事實依據。
當然,前所未有的大型行銷活動、社群媒體的話題傳播、疫情之類的劇烈環境變化無法預測,之後的需求預測很難只靠時間序列模型也是事實。但許多商品的短期需求預測,只要能夠確實管理統計學的需求模型,就有機會達到足夠的精確度。畢竟AI也很難應付這些突如其來且前所未有的環境變化與策略,時間序列模型的精確度極有可能遠勝於AI。
至於沒有過去數據的新商品,各個業界都以因果模型處理。他們整理出哪些要素影響需求,並參考擁有類似要素的基準商品的銷售實績,這種方法具有預測精確度較高的傾向。
然而整理出需求的因果關係,需要擁有該商業領域的深入知識。至少也必須具備足以理解多元迴歸分析的統計學知識。因此根據我的印象,在很多行業中,建立自己公司因果模型的企業仍然不多。
除了時間序列模型與因果模型之外還有判斷性模型。譬如應用德菲法或AHP的模型,以及預測市場等,這些都是嚴謹的方法,在某些商品上的預測精確度甚至有可能超越因果模型,然而就花費與技術需求的觀點來看,能夠運用這種預測模型的企業非常之少。廣泛使用的判斷性模型不是由上而下的數字目標,就是將業務負責人報告的數字往上疊加的思考邏輯,這些方法往往具有主觀性高、精確度低的問題。
從這些企業的實際狀況來看,新商品的需求預測,尤其在發售之前仍有很大的改善空間。
即使是AI,在學習資料的選擇與創建,也必須參考背後的因果關係。不過,只要能夠準備一定數量的數據,可能並不需要像統計模型那樣,把因果關係整理得那麼完備。
不斷地有人指出,AI預測存在有根據不明確的缺點,但隨著新的演算法逐漸開發出來,透明度也愈來愈高。我想,日後AI有可能會發現人類尚未察覺的需求法則。
綜合以上所述,我認為如果想要引進需求預測AI,建議優先考慮用在新商品上,尤其是在發售之前。不過,以AI取代現有的預測模型沒有意義,最好兩者併用。
關於預測根據的說明力,統計模型較占優勢。此外,如果擁有許多要素類似的基準商品的銷售實績,譬如商品在改版前的銷售狀況,時間序列模型或因果模型就有機會達到極高的精確度。
採取先進需求預測的全球性企業,使用的是三角測量式概念(Triangulation),以多種預測模型評估各預測值的合理性,考慮如何透過SCM與庫存計畫進行風險管理。我認為AI在這方面可以得到有效的應用。
圖片來源_商周出版
成功實現商品訂購自動化的食品超市
我從二○一七年開始參與需求預測AI的開發,原本以為只要讓AI學習來自公司內外的大量數據,就能提高AI的預測精確度。
但這個方法卻行不通。因為一家企業的新商品相關數據頂多只有數百個樣本,不足以作為AI的學習資料。離開實驗室來到現實的商業環境後,經常出現像這樣的數據量限制,這時候「學習資料的管理」就變得相當重要。
評估不同商品的AI預測結果,就會發現有的精確度高,有的精確度低。由此推測在需求的因果關係方面缺乏某些資訊。想要有效解決這個問題就不能只是蒐集分散公司內部各處的數據,如果有必要也必須感測或創造新的數據。
舉例來說,如果缺乏關於顏色的資訊,就去研究室尋找。為了表現外國旅客的喜好,分析過去受歡迎的商品特徵,並設計指數也能順利發揮作用。公司內部的BI(Business Intelligence)沒有需求預測觀點的數據,因此需要由該領域的商業專家創造數據以表現需求的因果關係,我稱之為「假設驅動的數據管理」。
像這樣創造AI的學習資料,在其他行業似乎也變得同樣重要。分店遍及全日本的食品超市集團LIFE Corporation,在全國分店引進需求預測AI的自動化訂購。他們從需求預測的角度,整合以箱為單位訂購和散裝訂購的商品編碼、考量早晨與傍晚等不同時段的需求特性,充分運用只有零售現場的專家才能想到的智慧。
這樣的數據建立工作花費了將近一年半的時間,而這種AI的預測精確度,也達到傳統主觀預測的訂購負責人同樣的程度。
累積符合商業課題的數據
人類在數據分析的速度與準確性方面比不上AI。但人類擁有靈活的發想力,唯有人類才能蒐集並創造有效的學習資料,因此AI與商業人士協作時的重點就在這裡。人類的其中一項優勢就在於,即使數據模糊或不完整,依然能夠根據這樣的資訊進行預測。
但這樣的預測含有偏誤及雜訊,導致預測精確度降低。需求預測必須考量的要素由人類設定,至於要素的比重或許可交由AI決定。
開發AI的商業人士,需要具備思考「利用AI可以解決哪些商業課題,而解決這些課題又需要累積什麼數據」的能力。
以需求預測為例,需要思考的就是:
● 哪些因素可能影響需求?
● 這些因素具體來說該衡量哪些數據?
利用專家的默會知識設計AI學習資料
常有人戲稱,不使用統計學的需求預測,靠的是直覺、經驗與膽量,但隨著AI開始被應用於需求預測的實務當中,我覺得人們將再次開始重新評估這樣的作法。
在目前的階段,先不論只靠基本數據、銷售實績、庫存資訊以及少許外部環境因素(譬如天氣和人口動態等)就能進行預測的商品,許多商品(服務)的需求,大幅受到宣傳、賣場魅力、銷售員的商品說明等難以定量化的市場因素影響,這些商品就很難開發預測精確度高的AI。
舉例來說,現在已經知道高價化妝品與服飾的需求,大幅受到店內銷售員對商品的介紹影響,卻很少有企業對此進行定量評估,並累積充分數量的體系化數據。如果是該領域的專家,應該能夠從經驗中得知哪些要素會影響這項商品的介紹。設計一個機制將這些要素化為數據,並在盡量不增加負擔的情況下持續累積,就變得非常重要。
這時,找出過去的需求預測專家所使用的、來自經驗的直覺到底是什麼,就變成一件重要的事情。
這樣的直覺不應該是胡亂猜測,而是立基於來自經驗的默會知識,所以才能在實務當中擁有一定程度的精確度。
問題不在於預測邏輯,而是這樣的思考歷程一直以來都沒有被視覺化。
商業中的需求預測,並非培養或聘雇一名頂尖的規劃師即可。擁有一個組織,能夠擴大預測的技術、並磨練維持技術的能力相當重要,這就是組織學習。
換句話說,有必要設計出能夠長期持續的流程或機制,並建立起重視需求預測的組織文化。
這方面可以參考一橋大學榮譽教授野中郁次郎提出的知識創造理論。默會知識是知識間的碰撞,而我對這句話的解釋是,商業領域的專業人士之間,針對彼此的假說認真議論,並藉由這樣的過程所形成的形式化知識。
這可以想像成,精通自家公司商品需求背後的市場、消費者、競爭者等的商業人士,彼此分享與實際銷售數據相關的各種數據,並且討論這些數據的解釋。
實際上,我在二○一四年,也就是從事需求預測的第四年,就開始將這樣的過程體系化,現在已經有一套固定的機制。我們以這個過程中累積的知識為基礎,蒐集並創造AI的學習資料。此外也在AI的學習反饋迴圈運作的過程中,持續同樣的碰撞。這就是需求預測的知識管理。(摘錄整理自《驚人的AI需求預測》第二章,商周出版提供)

圖片來源_商周出版
書名 驚人的AI需求預測
山口雄大(Yamaguchi Yudai)/著;林詠純/譯
商周出版
定價:400元

作者簡介
山口雄大(Yamaguchi Yudai)
NEC AI.分析事業總部需求預測技術傳教士。於青山學院大學擔任兼職講師(Supply Chain Management)。YCP Solidiance需求預測顧問。
畢業於東京工業大學社會理工學研究科,早稻田大學經營管理研究科。在資生堂股份有限公司負責各種化妝品品牌的需求預測,曾擔任S&OP團隊經理,現任職於NEC。日本物流系統協會「將SCM與行銷結合!需求預測的基礎」講師。在《Journal of Business Forecasting》(Institute of Business Forecasting & Planning)等刊物發表需求預測的論文。
熱門新聞

2026-02-09

2026-02-10

2026-02-06

2026-02-09

2026-02-10

2026-02-10

2026-02-10

2026-02-09