
歷程或出處是指資料在提取-轉換-載入(ETL)和其他移動過程中,所採用的「路徑」紀錄。當新的資料集和資料表在整個資料生命週期中經歷創建、丟棄、以及普遍被使用時,歷程可以是資料來源,也就是創建、轉換、導入的視覺化表示方式,它應該有助於回答「為什麼這個資料集會存在?」的問題,和「資料從何而來?」
當資料在您的資料湖泊中移動時,它會與來自其他地方的資料,混合並且交互作用以產生洞見。但是,元資料,也就是有關資料來源及其分類的資訊在資料傳輸過程中有丟失的風險。例如,對於給定的資料源,您可能會問「這個來源的資料品質如何?」因為,它可能是高度可靠的自動化過程,也可以是人工建立/驗證的資料集。由於不同來源的資料會混合在一起,而這些描述資料的背景資訊有時會丟失,以致於您可能不太信任其他來源的資料。
資料來源的元資料資訊,例如敏感性、品質、資料是否包含個人識別資訊(PII)等,可以支持是否允許混合某些資料以輸出最終結果、是否允許存取該資料以及該資料應該給誰等等的決策。在混合某些資料以輸出結果時,您需要追蹤其資料來源。而且,預計使用這個資料結果以達成的業務目標尤其重要,因為創建的資料產品應該要有助於實現該業務目標。例如,假設業務目標要求資料在單位時間內須具有一定的準確性,請確保資料歷程不會在處理資料時,降低時間單位的精準度。由此,我們可以得知歷程對於有效的資料治理政策至關重要。
如何蒐集歷程?
理想情況下,從資料的開始到結束,您的資料倉儲或資料目錄將擁有一個可檢視任何被使用的資料產品、儀表板或模型的功能,並且可以蒐集沿途中每個動作的歷程。但這樣的做法很少見,而且很可能會有盲點。對每個資料產品,您將不得不推論相關的資訊,或者以其他方式手動整理資訊以縮小與事實的差距。一旦您獲得此資訊後,便可根據其可信度,將其用於治理目的。
對於成功的企業來說,資料以指數型速度累積很常見;隨著資料的增長,在歷程蒐集過程中,允許越來越多的自動化,並依次減少對人工管理的依賴相當重要。自動化建立資料歷程並且盡量地減少人為的介入,有助於資料產品的發展與獲取終端使用者的信任。
另一種蒐集/創建歷程資訊的方法,是連接到資料倉儲的API日誌檔。API日誌檔應包含所有SQL工作,以及所有程式化的資料渠道,如R、Python等。如果有一個理想的工作稽核日誌檔,您可以用它來創建一個歷程圖。例如,這允許創建資料表的指令以便於回溯至先前資料表的模樣。但這樣的做法不如即時地記錄歷程有效,因為它需要回溯日誌檔和批次處理。但是如果您關注的是資料倉儲中的歷程,這種方法可能非常有用!
如何治理動態資料?
假設歷程資訊保存良好且在一定程度上是可靠的,一些關鍵的治理應用程式就會依賴資料歷程。
歷程可以滿足的一個常見需求是除錯或理解資料的突然變化。為什麼某個儀表板停止正確顯示?哪些資料導致了某種機器學習演算法的準確性發生了變化?諸如此類的需求。從最終產品中找出匯入哪些資訊後就發生了變化,例如,品質突然下降、欄位值缺失、某些資料不可用等等,此外,了解資料的路徑和轉換也有助於快速地解決資料轉換錯誤。
在所述歷程是可靠的前提下,通常針對資料欄位的另一個需求是,推斷資料類別的能力。例如,針對包含個人識別資訊(PII)的特定行,如想將基於此行所衍生的資料都標記為個人識別資訊(PII),而且之後衍生的行,也都想實施同樣的存取/保留/遮蔽等策略,可能就會需要一些特定的演算法,使您能夠在該行被精確地複製時實施相同的存取策略;但如果衍生行的內容是空值,則只能實施不同策略,或無法實施既有的控制策略。
圖6-4是一張稍微複雜一點的歷程圖。隨著資料從外部資料源移動到資料表D,以及隨著資料表D,與資料表A和資料表B的副產品「資料表C」合併,並最終呈現在儀表板中,您可以看到整個歷程經過,尤其是行級別的歷程有多重要。例如:假設不管是資料表A、資料表B還是外部資料源,都是只有其中一行包含個人識別資訊(PII),並且公司對個人識別資訊(PII)的政策是「僅允許全職員工可以存取」。因此,如果讓個人識別資訊(PII)進入到儀表板,應該就會影響到儀表板本身的存取策略。
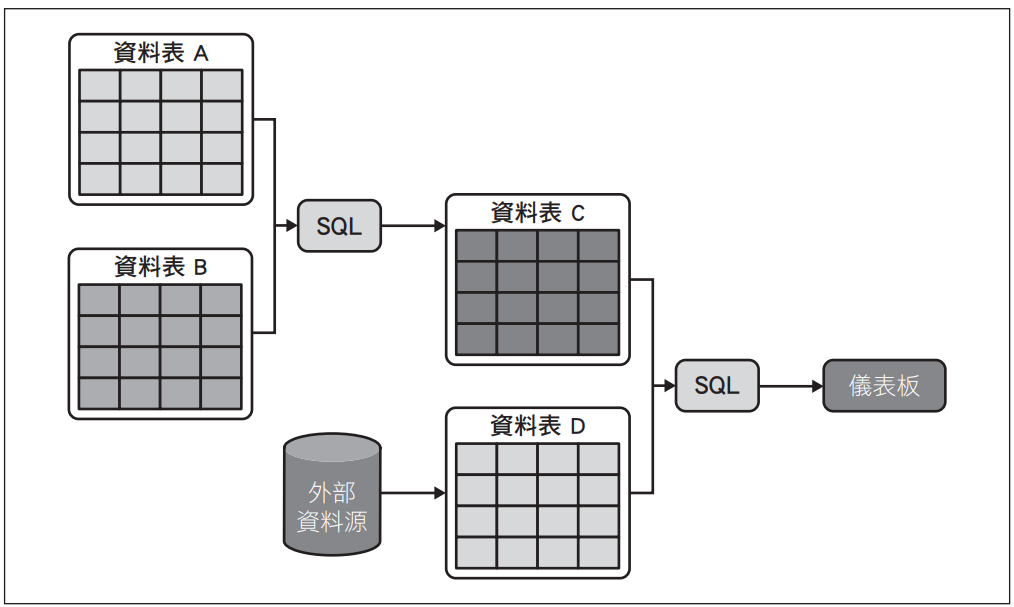
圖6-4:歷程的工作流,如果資料表B包含敏感資料,則儀表板中也可能找到該敏感資料。
但長期以來,資訊長(CIO)和資安長(CISO)期望的使用案例則更為廣泛:
「我想確定哪些系統可信任,並確保就算沒有人工監督,資料也不會存在於其他比較不受信任的系統中。」
這種需求可以透過在受信任系統上實施出口控制來解決,如果使用良好的歷程解決方案,這項任務可能會更簡單。例如,藉由這種方式,資料來源將被顯示在歷程資訊中,因此您可以防止來自未經批准系統的資料被攝取至受信任之環境。
「我需要能夠輸出報告,和稽核所有處理個人識別資訊(PII)的系統。」
這是GDPR時代的普遍需求,如果您標記個人識別資訊(PII)的所有來源,就可以利用歷程圖來識別個人識別資訊(PII)的處理位置,從而實現更高級別的控制。
策略管理、模擬、監控、變更管理
本質上,資料治理政策應該從資料的含義中推導出來。如果在某個組織中想要管理個人識別資訊(PII),並將個人識別資訊(PII)定義為個人電話號碼、電子郵件地址和街道地址,則可以自動地檢測這些個人資訊類型,並將其與資料類別相關連。然而,掃描資料表,並確定哪些行包含這些資訊類型在計算上很昂貴。為了正確識別資訊類型,在不知道哪些行包含敏感資訊的情況下,需要採樣整個資料表,並且透過模式匹配和機器學習模型處理這些採樣,從而提供對基礎資訊類型的可信度,並適當地標記行。
但是,如果您可以只需識別該標記行的創建事件,則此過程會變得更具效率。而這就是資料歷程發揮效用的地方。
歷程資訊的另一個用途是資料變更管理的考量。假設您要刪除某個資料表;或者,您想要更改資料類別的存取策略;又或者您可能想設置一個資料保留控制元件,在一段時間後將資料內容變得更加簡略,例如30天後,將資料從「GPS座標」更改為城市/州。透過歷程,您可以追蹤受影響的資料到其最終產品,並分析此更改的影響。假設您想要限制資料表中某些欄位的存取,您可以透過查看哪些儀表板或系統會使用到這些即將遭受限制的欄位值,並評估受影響的範圍。一個理想的結果是當終端使用者在存取資料/儀表板時,會跳出一個提醒視窗顯示存取權限發生變化,因此可以在更改策略時發出警告,提醒管理員某些使用者將失去存取權限,甚至可能允許一定程度的深入鑽研,以便檢查這些使用者受影響的情況並做出更明智的決定。(本文摘錄整理自《資料治理技術手冊》,碁峰資訊提供)

圖片來源_碁峰資訊
書名 資料治理技術手冊(Data Governance: The Definitive Guide)
Evren Eryurek、Uri Gilad等/著;簡誌宏/譯
碁峰資訊出版
定價:580元
作者簡介

Evren Eryurek
Evren Eryurek博士是Google Cloud資料分析和資料管理產品組合的領導人。

Uri Gilad
Uri Gilad領導Google Cloud中巨量資料的資料治理。
熱門新聞

2026-02-02

2026-02-03

2026-02-04

2026-02-02

2026-02-04


2026-02-03

2026-02-05