支援、提升穩定性,以及替Spark Streaming加入更多新功能。")
Spark 核心開發者范文臣表示,在Spark 2.2版本中,將加強資料定義語言(Data Definition Language,DDL)支援、提升穩定性,以及替Spark Streaming加入更多新功能。
iThome
「Spark SQL不僅僅是SQL」,Spark 核心開發者的范文臣表示,Spark SQL除了強化Spark處理結構化數據的能力,同時也為用戶提供結構化API,「如果時光可以倒流,我們可能會稱它為Spark Structure。」
Spark的分散式計算模型RDD(Resilient Distributed Dataset)雖然簡單,但是相當通用,像是Spark SQL、Spark Streaming及圖像API模組GraphX,都是以RDD為基礎進行實作。但范文臣表示,此模型也有其限制,「它像是黑盒子,導致開發者不易進行修改、優化。」
另外,計算函數對於Spark也是個黑盒子,使用者不知道變數類型相對應的資料結構為何。在不了解系統如何進行運算、讓儲存效率更高的情況下,也讓開發者喪失許多改善效能的機會,「Spark SQL就是為了解決如此問題而出現。」他表示。
范文臣表示,雖然Spark SQL僅負責處理結構化數據,並且犧牲部分的通用性,使得靈活度不如RDD模型,「但現實生活中,企業經常面對辦結構化資料及結構化資料,藉此改善Spark的執行效能,是非常划算的決定。」此外,Spark SQL也提供DataFrame、DataSet等高層次API,讓企業開發Spark應用更為方便。
Spark SQL核心三大架構
Spark SQL核心架構分為三大部分:API模組、前端模組Catalyst,用於分析、改善使用者查詢,以及負責執行對應RDD的後端模組。他認為:「Spark SQL之所以可以成為活耀的Spark專案,Catalyst可謂功不可沒。」范文臣表示,Catalyst這個模組的優勢在於程式碼簡潔、框架靈活。
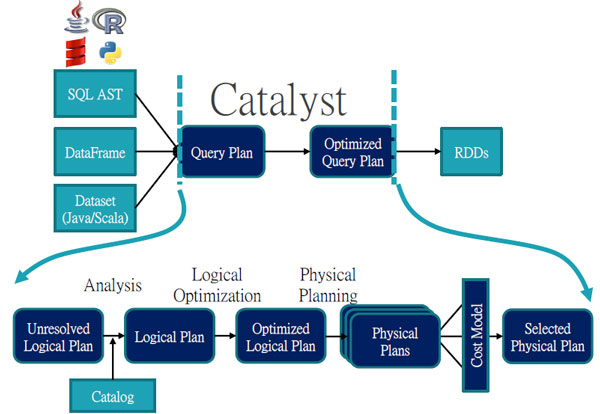
Catalyst模組利用分析、邏輯優化、實體計畫三階段,將更優化的查詢計畫交給後端RDD執行。因此,Spark 核心開發者范文臣認為:「Spark SQL之所以可以成為活耀的Spark專案,Catalyst功不可沒。」(圖片來源/Databricks)
利用查詢計畫定義如何產出新數據
Catalyst的運作機制則仰賴查詢計畫(Query Plan)來表達使用者的查詢。而上層API如SQL AST、DataFrame、Dataset,也靠著Catalyst模組提供介面,讓開發者建構查詢計畫。范文臣表示,使用者雖可以定義平臺如何產生新的資料欄位,「但是仍要定義如何產生新的數據,而查詢計畫的目的就是用於此」,可用來描述數據的處理行為,例如Join、Project、Filter等操作。在開發者完成查詢計畫之後,Catalyst模組再進行一系列轉換,輸出一個經過優化的查詢計畫,並且交由後端RDD模組執行。
兩大查詢計畫:邏輯查詢計畫、實體查詢計畫
而查詢計畫還可以細分為邏輯查詢計畫(Logical Query Plan)和實體查詢計畫(Physical Query Plan)。范文臣表示,邏輯查詢計畫定義數據的運算過程,「但是並不特別指明該計算如何進行。」
他舉例,根據資料量的不同,使用者可能會判斷使用Hash Join、Sort-Merge Join,但是透過邏輯查詢計畫,開發者只需表明利用Join處理即可。
反之,實體查詢計畫就明確定義了數據如何執行計算,例如根據資料格式不同,提出相對應的處理手段。
3步驟改善查詢計畫
而范文臣表示,Catalyst模組也會自動透過三大步驟來改善查詢計畫。第1步是分析階段,將未解析(unresolved)邏輯查詢計畫,轉換成邏輯查詢計畫。再者則是邏輯優化步驟,透過一系列的優化規則,對完成解析的邏輯查詢計畫,進一步優化。最後才將邏輯查詢計畫交給後端RDD執行。
Spark 2.0已全面超越1.6版
另外,范文臣表示,在去年釋出的Spark 2.0版本中,除了加強效能表現、易用性,也要讓Spark本身變得更加聰明。而這些目標,也透過Spark SQL的三大特色實現。
第一個特色是Tungsten專案,正在邁入第二階段,因此,「Spark 2.0已經全面超越Spark 1.6,所有的Query執行都比1.6快,其中某些操作可以快上幾十倍」,范文臣表示,根據Databricks的測試,光是Spark後端引擎執行資料過濾、加總、分組,Hash Join的效能,就提升了5至30倍。而基數排序法(Radix Sort)的運算,執行速度也快上10至100倍。
第二特色則是加強API功能,讓使用者開發Spark應用程式可以變得更加簡單。范文臣表示,Databricks新增了一個程式碼入口端點SparkSession,它的功能除了作為使用者瀏覽DataFrame的媒介,也可以與中介資料互動,查詢資料表格中的行、列數目及資料大小。同時,SparkSession還可以管理系統組態、叢集資源,「系統資源的調度,也可以透過這個API管理。」
最後在Spark 2.0中,也新增了結構化串流(Structured Streaming)功能模組,「這是Databricks想要簡化串流數據操作的嘗試。」范文臣表示,目前業界對即時串流的需求增加,想藉由處理即時數據,加速企業的決策時間。而他也觀察到,在即時串流處理的實際應用中,往往還要搭配批次處理以及查詢操作,例如,在開發者彙整系統產出即時數據,並且匯入SQL資料庫後,讓其他使用者可以進行SQL查詢,或是讓使用者利用離線資料訓練機器學習模型。
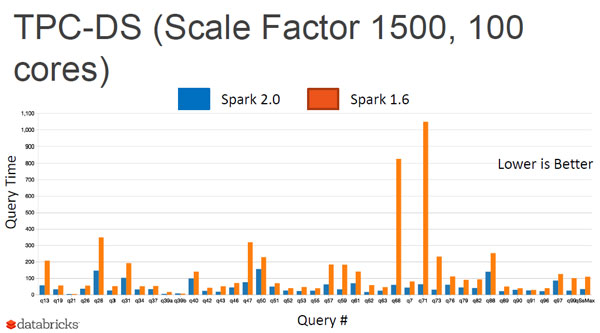
Spark 2.0效能全面超越Spark 1.6,所有的Query執行都比1.6版快。根據Databricks的測試,光是Spark後端引擎執行資料過濾、加總、分組,Hash Join的效能,就提升了5至30倍。而基數排序法(Radix Sort)的運算,執行速度也快上10至100倍。(圖片來源/Databricks)
企業導入即時串流分析碰上的挑戰
但在實際導入串流處理的過程,企業卻碰上不少問題,范文臣舉例,像是資料傳輸延遲而影響了分析結果,或像在分散式串流架構中,部分節點成功將資料寫入至資料庫中,但其餘節點傳輸失敗,導致資料庫中的數據不完整。
在改善串流處理的過程,范文臣也總結了一個基本心得:「企業想要導入串流分析最簡單的方法,便是不要思考串流處理的問題。」他解釋,假設串流分析平臺必須針對系統日誌文件進行ETL處理,如果1個禮拜處理一次,能否被歸為串流處理?范文臣表示,大多數人的回答應該都是否。但他表示,若將極端狀況列入考量,「將時間區間縮小到每5秒,甚至每1毫秒執行一次呢?」
范文臣解釋,在運作邏輯上,串流處理每隔一段時間,就會對所有的數據進行查詢,「企業用戶並不會碰上串流處理,僅會用上批次處理」。然而在實際運行上,Spark則會按照即時串流的方式處理資料,例如,減低每次執行計算資料量、掃描新增數據,「達到串流處理的效能。」
未來Spark要提升穩定性、加強串流功能
而范文臣也預告未來Spark的發展方向。他表示,在Spark 2.2版本中,將加強資料定義語言(Data Definition Language,DDL)支援、提升穩定性,以及替Spark Streaming加入更多新功能。
最後是將持續提升Spark的效能。在Spark執行資料的映射(Map)及化簡(Reduce)過程中,中間必須透過Shuffle串接兩者。
范文臣表示,由於CPU核心數增加是未來趨勢,導致Mapper及Reducer都在同一節點上運作,「未來得要朝In-Memory Shuffle發展,藉此提高Spark的性能。」
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-10

2026-02-09


2026-02-10

2026-02-06