")
國家災害防救科技中心從2年前開始用上百個社群媒體的災害資訊,來幫助政府能有效掌握未知的新災情。上圖右至左為負責系統開發的主要成員蘇文瑞、劉致灝。(攝影/洪政偉)
去年7月8日,強颱尼伯特橫掃東臺灣,破表的17級風更在臺東肆虐,造成重大災情,挾帶的豪大雨,更導致多處淹大水,颱風期間,中央也趕在第一時間,在國家災害防救科技中心(簡稱:災防科技中心)3樓成立臨時災害應變中心嚴陣以待,並由內政部長葉俊榮現場坐鎮指揮,隨時緊盯前方螢幕牆上不斷回傳更新的民眾第一手災情資訊,並依這些情資現場馬上下達指令。
只要一有民眾在社群網站貼出新災情,隔沒多久,應變中心的社群災害情資平臺,就能看到這些災害資訊,這些網站每增加一筆災害情報,螢幕牆上就會新增多一筆,並依時間排列,每一張社群災害資訊上,皆會以照片形式來呈現,照片下方還會搭配日期時間、地點描述、資料來源,甚至還會在螢幕牆右側的大型地圖上,顯示災害發生的定位資訊。
政府救災也開始結合社群情資
尼伯特颱風警報從早上6點發布後,不到25分鐘,應變中心從社群網路已經得知臺東市區路上開始出現災情,颱風登陸3小時後,也收到高雄市三民區淹大水的情資,隔了5小時,臺南市仁德區也傳出相同的淹水情形,直到下午4點,颱風登陸的9小時後,指揮中心已經可以大致掌握主要災情分布,指揮官可以馬上指揮動員救災。
從颱風登陸到警報解除期間,應變中心蒐集到的社群災情資料超過4萬5,000件,可供政府掌握全臺即時救災情資來使用。
尼伯特颱風並不是政府第一次開始結合社群情資救災的重大災害事件,早在5個月前的高雄美濃6.4大地震時,政府就已經開始運用社群輿情來救災。尼伯特襲臺之後,從9月的莫蘭蒂及馬勒卡雙颱,以及中颱梅姬,到今年7月的尼莎和海棠過境時,也都結合社群情資,來縮短災情通報時間,讓現場指揮官可以依據民眾提供的即時災情,迅速調度人力來支援救災。
「以前因為救災速度太慢,所以政府常被批評是看媒體找災情。」長期擔任政府災害科技技術支援的災防科技中心系統開發專案組組長蘇文瑞很有感。他表示,這其實是和過去政府救災資訊情資的掌握速度太慢有關。
蘇文瑞表示,過去發生緊急災害後,政府在蒐集這些災害資料時,多半都得靠民眾的通報才知道,如撥打119電話,等到消防單位到現場處理後,才由各局將各地災情資訊統一彙整回傳中心,「但這樣的速度,用在現場救災應變上,反應還是太慢,所以才會惹得背負罵名。」他說。
隨著社群媒體竄紅,成為時下最熱門的資料傳遞與散布的新管道,甚至取代了傳統媒體。蘇文瑞表示,政府的緊急災害應變也有新作法,開始結合社群情資的力量,只要民眾將災害情報,以文字、照片或影片等方式,發布到社群網路上,政府馬上可以從這些地方蒐集到最新災害資訊,來加快救災,等於是「全民都變成政府的資料蒐集器。」他說。
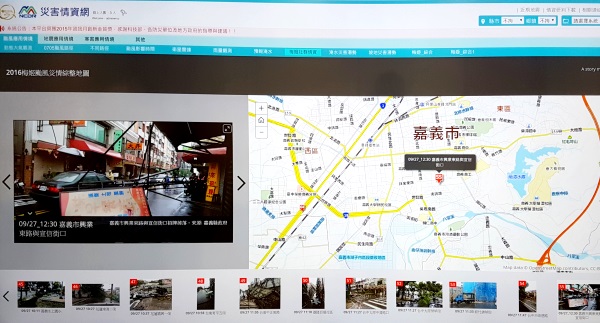
政府的社群大數據災情蒐整及分析平臺,自2年前開始推出上線後,現在每當發生重大緊災害事件時,只要有民眾在社群網站貼出新災情,隔沒多久,中央災害應變中心的社群災害情資平臺,就能快速看到整理篩選過的最新社群災情資訊,能依照時間排列,以照片來呈現每一件社群災情資訊,還會顯示發生時間、地點、資料來源,也會直接在大型地圖上,顯示災害發生位置。(攝影/余至浩)
掌握災情的速度能比媒體更快20分鐘
有了社群媒體情資來救災後,蘇文瑞表示,現在,不一定要靠民眾通報,也能夠很快知道哪裡有災情發生,掌握救災情資速度更快,而且是第一手消息,資訊更即時,如果跟傳統媒體相比,「甚至能做到比傳統媒體還提前快20分鐘知道。」他說。
透過社群媒體取得災害資料,還有另一個好處,蘇文瑞指出,民眾以前只有在災情嚴重時才會通報,還沒釀災就不會通報,只會在社群媒體上分享,而直接蒐集社群平臺上的公開資料,也可以幫助政府提前知道哪些區域需要特別注意,針對可能即將有災情發生的地點,及早提高警覺,加強各項防災工作。
政府之所以能在發生緊急災害後,可以很快取得社群網路發布或討論的最新災害資訊,靠的是災防科技中心在2015年建立的一套社群大數據災情蒐整及分析平臺,可以即時蒐集來自不同社群討論的最新災情資訊,以便提供給現場指揮官即時作判斷,才可以迅速掌握救災情資。
蘇文瑞表示,目前可用來蒐集災情的社群平臺來源,共有213個,其中包含了許多臺灣民眾常用的社群媒體,例如臉書(FB)、噗浪(Plurk),或是討論區及論壇,如批踢踢(PTT)或Mobile01等,但並不包含社群通訊軟體Line。至於蒐集的資料內容,主以網民在社群網站上發布的文字、照片,以及影片連結為主。

政府之所以能在發生緊急災害後,可以很快取得社群分享或討論的最新災害資訊,靠的是災防科技中心在2015年建立的一套社群大數據災情蒐整及分析平臺,可以透資料攀爬,即時蒐集來自不同社群網路發布的最新災情資訊,並經過濾及篩選後,可供政府迅速掌握救災情資。(圖片來源/國家災害防救科技中心)
社群災害情資蒐集分3階段
當一有緊急災害發生,政府就會立刻啟動社群災害情報的蒐集活動,整個社群災情輿情的蒐集流程分成3階段:社群災情文章列表、重點災害情資應用,以及災情發布。
一開始資料蒐集,會利用爬蟲程式,從社群網站或論壇,來分批抓取災情資料,再將資料匯入到後端資料庫可以被查詢。攀爬機制也經過設計,例如只針對社群網站或討論區較可能出現與災情相關的地方來蒐集,如PTT地方版等,以防止撈到與災害無關的資料。不同資料來源的管道,資料擷取的次數頻率也有所不同,整體來說,「只要社群媒體一有新資訊出現,到匯入我們系統可以查詢得到,只須20分鐘。」他表示。
不過,蘇文瑞也提到,即使有利用攀爬程式來抓資料,但有時還是會遇到少數災情資料無法取得的情況,像是颱風期間才出現的臨時性活動,如民眾在臉書成立的災情回報專區等,因為不在原來程式設定抓取的範圍,因此就可能會漏掉,所以這時還是得透過人工的方式,將這些新出現的災情回報熱點,手動列入到攀爬的名單。
蘇文瑞也指出,將這些資料蒐集下來以後,並不是全部的資料都會變成政府參考的重要災害情資,而是會先經過二階段篩選的步驟,「畢竟這些都是即時災情的資訊,使用上也相對要更加謹慎。」他說。
每次資料蒐集完後,會先以「關鍵字」搜尋的方式,針對這些雜亂未經過整理的原始資料,進行初步過濾的動作,只保留內容有符合特定關鍵字的資訊,例如「豪大雨」、「淹水」、「颱風」或「地震」等。
蘇文瑞表示,災防科技中心還自行建立一套災害關鍵詞字庫,內含許多相關的災害關鍵詞可以搭配組合,再透過關鍵字過濾出的第一步資料,就會在社群災情平臺上列表,也是社群情資發布過程的第一階段。
針對災情資料特徵的快篩過程,也結合機器學習
緊接著,針對這些過濾後的資訊,還會再進一步的快篩,透過分析資料特徵,找出符合政府救災可用的資訊特徵,這些特徵有4大,包括了時間、地點、災害描述,以及照片資訊。全部特徵都必須具備後,才可以列入重點災害情資的候選名單,進到下一階段的人工判斷,如果缺少其中一項,例如照片等,就會先不處理,優先處理其他還沒篩選過的資料,除非是前面過濾的資料已經比對完畢後,才會針對原先不完整的資料,重新確認有無更新的災害資訊進來。
蘇文瑞還指出,在進行文本分析時,也借助了機器學習,將這些蒐集起來的社群災害資料進行分類,找出哪些可能是符合災情的正確特徵,來分別進行過濾。蘇文瑞表示,災防科技中心也建立一套大數據分析平臺,並找來800篇的社群媒體災情文章,來持續做為機器學習訓練,以建立預測模型,目前學習效果的準確度約70~80%。
蘇文瑞表示,若以地址資訊來說,透過這套預測模型,可以直接從每篇社群災害資料中,分辨出哪些是災害描述的地址,即使是分散在文章不同段落,也可以自動重組拼湊,找出可能相近的地址,之後再透過門牌地址定位服務TGOS,或如Google的地址位置查尋,以取得經緯度的座標,以便之後可以在實際地圖上定位。
不過,蘇文瑞也坦言,如果原來的資訊本身就不夠完整時,例如路名不清楚等,最後還是需要人工來判斷。
人工做最後把關還是不可少
如何確保網友分享的災害資料是正確可信的?蘇文瑞表示,靠的是背後建立的3道篩檢關卡,前兩道是透過系統來自動篩選過濾,先將一些與災害資訊無關或資訊不完整的資料剔除,只保留與災情相關且重要可用的資訊,即使篩選通過後,再上架到政府社群災害情資平臺前,還要由人工判斷做最後的把關,以確認資訊真偽,才可以實際用來當作政府災害情資的發布使用。
之所以最後仍要由人工來幫忙把關,蘇文瑞解釋,這是因為目前電腦還沒辦法完全辨識資料的真假,所以一旦民眾提供的是假資訊時,如假造的照片等,系統收到後並沒有辦法判別訊息真假。
蘇文瑞也回憶說,去年梅姬颱風期間,就曾經有民眾貼出一張假照片,照片中地點的確有淹大水,而且災情描述也都正確,但後來發現民眾用的是好幾年前的舊照片,「這就不是系統可以自己判斷得了的,還是得靠人工方式來找資訊佐證。」他表示,在人工判斷上,像是可以透過即時觀測的雨量資料,或是調閱現場附近交通監視器的影像畫面,來進行交互比對,確認照片所在地區現在的雨量,是不是真的已經造成淹水情形。
也因為透過這3道篩檢機制,來進行層層把關,才可以確保這些網友發布的災情資料是正確且可信的,才可以被政府所採用。
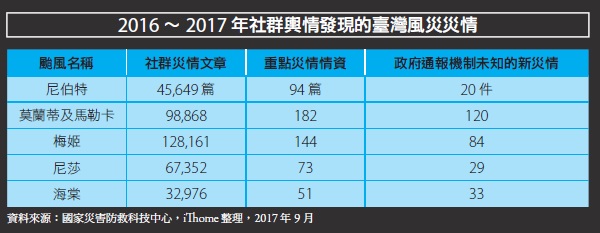
若以去年的梅姬颱風為例,根據災防科技中心的數據統計,颱風期間,總共蒐集的社群災情文章共有128,161篇,雖然經過系統過濾及人工篩選後,到最後實際能用的災情資訊,只有84個,大約占了梅姬颱風全臺災情923處的8.6%。
但不能小看這84件災情的重要性,因為這些透過社交網站資訊所發現的每一件災情,是以原有政府監測機制、各種通報機制、民眾報案系統都沒能發現的新災情,等於這個從社交平臺蒐集災害輿情的作法,讓政府更快掌握那過去看不見的近1成災害事件,而能讓救災資源的調度再早一步,甚至也能用來加快災害風險評估,讓現場指揮官可以針對有潛在高風險的偏遠鄉區,提早擬定疏散撤離的計畫,以保障民眾生命安全。
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
")
2026-02-09
")
2026-02-09

2026-02-09