Google最近開源釋出實驗性的語意框架剖析器(Parsing)SLING,有別於以往用斷詞的方式,SLING不需要靠人工的方式標註語句,而是可以透過語意框架(Frame Semantic Parsing)的方式自動抽取出文字所要描述的語意結構,再以語意框架圖(Semantic frame graph)的方式呈現,Google研究團隊表示,SLING是透過Tensorflow和Dragnn訓練過的標註語料庫,這是自然語言理解技術的一大進展,語意分析不再靠斷詞,而是從語言意義層面,自動標註出語句的結構。
SLING是採用一個特定用途的遞歸神經網路(Recurrent neural network,RNN)模型,在該框架圖上,透過輸入文字的遞增編輯動作,來計算輸出值,也就是說,該框架圖因為靈活的特性,可以擷取多個語意任務,SLING的語意剖析器只用了輸入詞句來訓練,沒有採用額外的生成的標註,像是語句相依性分析產生的標註。
大部分的自然語言理解系統都是採用一種分析流程,從詞性標註 (Part-of-speech tagging),到透過語句相依性分析(Dependency parsing)來計算輸入的文字語意。這種模型較容易將不同的方析階段模組化,但是往往也導致一個問題,一旦產生錯誤將會影響整個模型的預測。
SLING輸出的語意框架圖可以直接擷取使用者感興趣的語意標示(Semantic annotation),也能避免系統流程中的設計缺陷,還能避免不必要的計算。
舉例來說,傳統的自然語言理解系統會先執行語句相依性分析的工作,最後才會執行指代消解(Coreference resolution),指代消解是將指定代名詞還原為被替換的名詞,來避免重要的字詞因被替換為指定代名詞,而在計算權重時降低的問題,如果語句相依性分析過程若有錯誤,將會連帶影響最終輸出的結果。
語意框架剖析的機制
語意框架代表語句的意義,也是一個描述,每個描述都被稱為一個框架,該框架可被視為知識或是意義的單元,也包含了與其相關的概念或是框架的相互關係。SLING將每個框架組織成一個Slot的清單,每個Slot都有自己的角色或是名稱,以及代表的值,該代表值可以是個字詞的原意,或是與其他框架的連結。
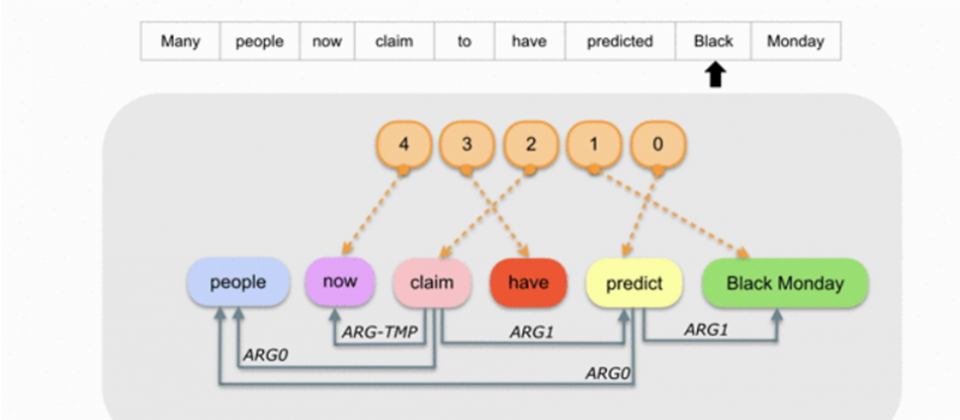
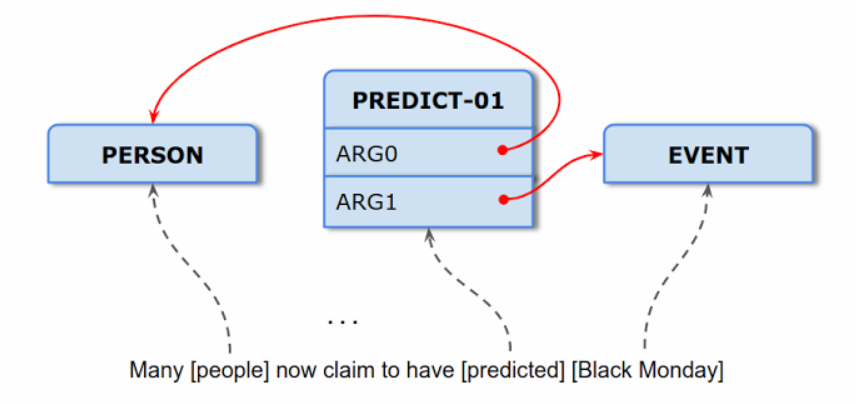
例如,Many people now claim to have predicted Black Monday這句話,SLING先辨識語句的實體、測量值和其他概念,實體像是人物、地點,事件,測量值像是時間、距離,其他概念則包含動詞,接著,將這些辨識出來的字詞分類到正確的語意角色,當作輸入值,因此,SLING會先將people視為人物框架、predicted是動詞類別框架、Black Monday是事件框架,predicted這個動詞表示為PREDICT-01框架,PREDICT-01框架與預測的主詞Slot有相互關係,因此,PREDICT-01與PERSON框架連接,除此之外,PREDICT-01框架也與被預測的受詞有相互關係,與Black Monday的EVENT框架連接。
Google研究團隊認為,SLING透過語意框架,來訓練並優化遞歸神經網路。神經網路在隱藏層中學習到的知識,可以取代了人工標註特徵。
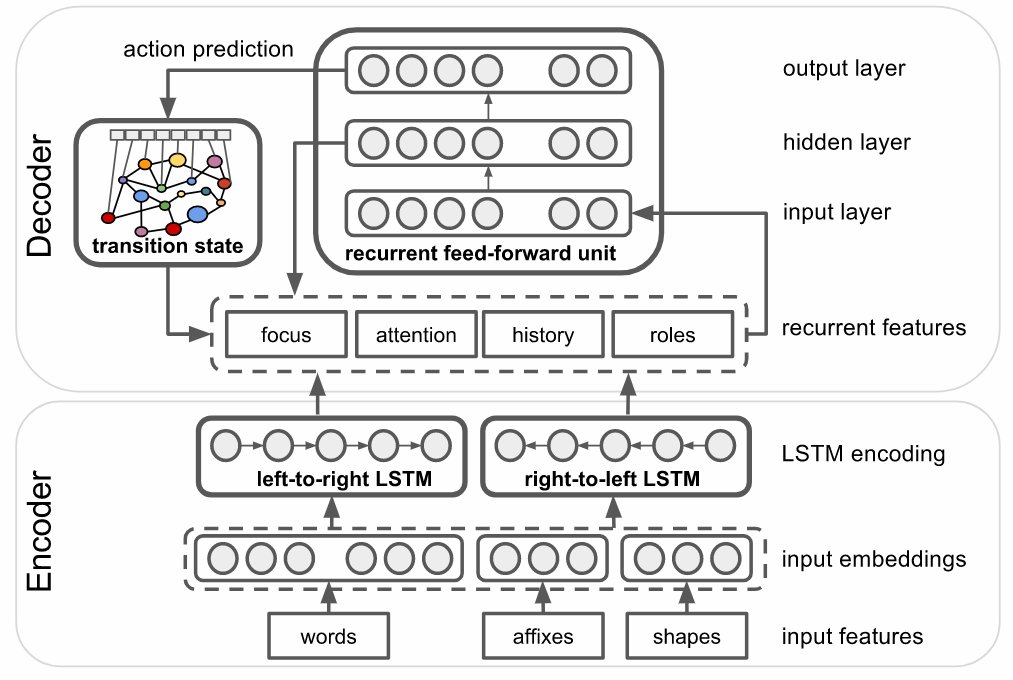
該語意剖析器的輸入是以雙向長短記憶單元(Bi-directional LSTMs)演算法為基礎的轉換語意框架剖析方法,使用Transition Based Recurrent Unit (TBRU)來輸出,結合成一個訓練過的模型,只需要文字標註當作輸入,經過轉換系統,輸出語意框架圖形,不需要中間產生的標註(Intervening symbolic representation)。
輸出層的文字在輸出後,還會經過轉換系統(Transition system),再重新進入輸入層,其中,轉換系統的一項關鍵機制是採用了固定大小的框架來記錄字詞對上下文預測的重要程度,也就是說,該框架是用來表示最近提及,或是在語句中被增強的關鍵字。Google研究團隊發現,透過這個簡單的機制,在擷取大量語意框架的關聯上,效率提升有非常多。
目前,Google的研究團隊表示,SLING是研究語意剖析的實驗,Google已在Github將SLING開源釋出,提供開發人員預先訓練完成的語意剖析模型,可應用於知識萃取、解析複雜引用(Resolving complex references),以及對話理解等工作,未來,Google將會持續擴增SLING的功能。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10