Google今日(6日)在臺發表過去Google Brain團隊在科學探索上的研究,包含用機器學習發現新行星的成果,以及用於基因變體識別的深度學習工具DeepVariant,而DeepVariant已經於去年底在GitHub上開源。
Google臺灣董事總經理簡立峰表示,這兩項都是跨領域合作的研究成果,臺灣發展AI也可以從跨領域的方向著手,現在有許多開放的資料集,讓資料的取得更加方便,再加上許多開源的AI工具,臺灣可以善加利用,打造出跨領域的AI應用。
另外,有趣的是,這兩項成果也都是用了開源的資料庫,來當作訓練資料,意味著若配合開源工具,科學研究的門檻將會大幅地降低。
臺灣天文科教界元老之一的臺師大科學教育中心推廣服務組組長傅學海就表示,若Google將發現新行星的機器學習工具,像DeepVariant一樣開源,將可以把前端天文科學研究技術帶給更多人,發現行星就不再是研究學者和機構的專利,由於NASA的資料都是公開的,加上開源的工具,就連高中生也有機會可以發現系外行星,這將會是科普教育的一大推力。
用機器學習模型分析微弱訊號,找到2顆新行星
尋找新行星是天文學家一大研究方向,NASA過去4年間透過克卜勒太空望遠鏡收集了超過20萬顆恆星的亮度,每30分鐘記錄一次,累積超過140億筆資料,由於天文學的時間有限,只能聚焦在3萬顆恆星的明顯訊號,從中找到2,500個行星訊號,但是還有超過10萬顆恆星的訊號因為訊號較微弱,且有較多雜訊,無法用人工的方式處理。
因此,Google鎖定較微弱的訊號資料,利用1萬5千個已經過天文學家標示的克卜勒訊號,訓練機器學習模型,該模型可以分辨較微弱的亮度訊號,搜尋克卜勒資料庫中的670顆恆星訊號,成功地找到2顆以往未發現的新行星,分別命名為克卜勒-90i和克卜勒-80g。
Google Brain研究團隊資深軟體工程師Chris Shallue表示,以往天文學家尋找新行星是先透過電腦演算法找出潛在行星的訊號,接著用肉眼辨識訊號是否來自行星,但是人工用肉眼判斷的方式不僅耗時,且無法辨認較微弱的訊號,因此,常常忽略掉隱藏的訊號。
機器學習演算法則可以透過大量的數據,從數據中學習如何判斷行星的訊號,Chris的團隊將訊號轉為亮度曲線圖,輸入完整的亮度曲線圖和局部變化的亮度曲線圖,透過卷積神經網路(Convolutional Neural network)模型來分類影像,判別該亮度曲線圖是否為行星。
特別的是,克卜勒-90i為第8個圍繞在克卜勒-90星系的行星,這是除了太陽系外,第一個被發現的8大行星系統,因此,與Google Brain團隊合作的德州大學奧斯汀分校天文學家Andrew Vanderburg也將Kepler-90描述為「迷你太陽系」。而克卜勒-90i是克卜勒-90星系中最小的一顆行星,也是第三靠近恆星的行星,根據估計,表面溫度超過攝氏400度。
不過,Chris也表示,目前的研究還有一項瓶頸就是模型的預測結果會出現假陽性(False Positive),也就是說,偵測到的恆星亮度可能來自附近的恆星,模型還無法去除掉這樣的雜訊,還得透過人工的方式確認模型偵測到的行星位置訊號,因此,他期望,未來在建立模型時,可以加入位置的特徵,讓模型能夠辨識雜訊。
另外,克卜勒資料庫中有超過20萬顆恆星,目前的成果只是從670顆恆星的訊號中,找尋到2顆新行星,未來還希望可以透過模型分析更多恆星訊號,他也相信會有更多的新發現。
用於基因變體識別的深度學習工具DeepVariant
另一方面,基因定序的研究應用範圍相當廣泛,新一代的測序儀雖然只需要百元美金就能檢測基因序列,相較於以往的設備也較快速,但是測序儀測序的結果常常有誤,得到的基因序列的資訊也是片段、不完整的,Google嘗試著用軟體來解決這樣的問題,讓新一代便宜的測序儀器可以更加準確。
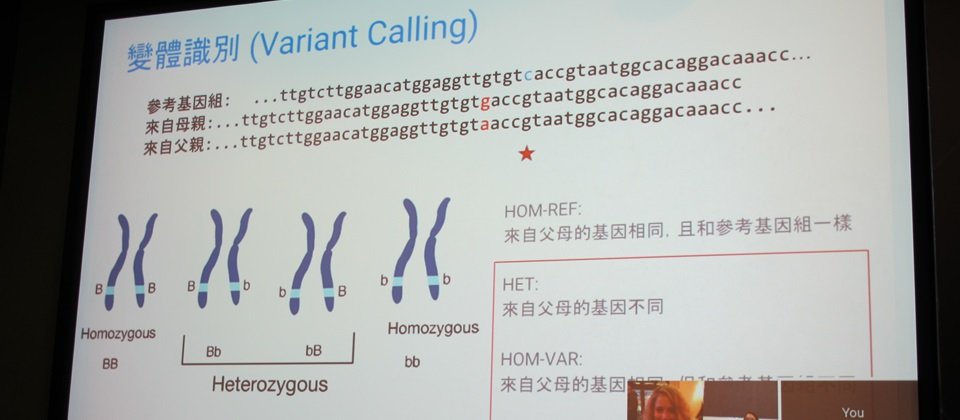
Google透過深度學習來做變體識別(Variant Calling),變體即是個體和參考基因組之間的差異,有些變體會造成疾病,目前Google主要聚焦在全序列和蛋白質序列的變體識別,也在去年底將用於基因變體識別的深度學習工具DeepVariant開源釋出。
負責這項研究的Google Brain研究團隊資深軟體工程師張碧娟表示,變體識別對於醫療上的病因解釋、藥物開發、癌症標拔治療都有幫助,但是檢驗變體是一項非常困難的研究,因為資料量太大,且目前透過測序儀測序的結果常常有誤,再加上,目前的統計方式都需要手動設計特徵和參數,不同的測序儀或是統計的方式不同,這些設計都不容易轉移到不同的實驗方法中。
也因此,Google Brain的團隊採用機度學習,不需要手動萃取特徵和調整參數,並與Verily Life Sciences合作花2年多時間開發基因變體識別工具DeepVariant,將測序儀讀取到的資訊轉成圖像,用常見的圖像分類演算法Inception V3辨識圖像,張碧娟表示,Google Brain用超過百萬的基因序列資料,訓練出DeepVariant,辨識的準確率高達99%以上。
未來,張碧娟期望將DeepVariant應用在不同的生物上,像是老鼠或是植物的變體識別,也希望來有更多臨床驗證的機會,實際結合臨床的資訊與病史,驗證DeepVariant的準確性。
熱門新聞

2026-02-09

2026-02-10

2026-02-06

2026-02-09

2026-02-10

2026-02-10

2026-02-10

2026-02-09