
LinkedIn開源TonY專案,讓使用者可在單節點或是大型Hadoop叢集上,基於YARN建置TensorFlow應用的解決方案,TonY其運作方式就像是在Hadoop中的MapReduce,執行Pig和Hive腳本的方式類似,提供TensorFlow任務第一層級的支援。TonY由三個主要元件組成,分別是客戶端、ApplicationMaster以及TaskExecutor,主要提供四大特色GPU調度、精度資源請求、TensorBoard支援以及容錯。
LinkedIn平臺會員接近6億人,隨著深度學習技術的發展,LinkedIn的人工智慧工程師,努力在眾多像是摘要或是回覆等功能中應用人工智慧,而其中有許多使用案例,皆使用Google開發的深度學習框架TensorFlow建置。一開始LinkedIn內部TensorFlow用戶都只在小型和非託管的裸機上執行應用,但隨著發展,他們逐漸意識到必須要讓TensorFlow連結並使用Hadoop大資料平臺上的運算以及儲存資源。LinkedIn的Hadoop叢集擁有數百PB的資料,很適合用於開發深度學習應用。
雖然TensorFlow支援分散式訓練,但要編排TensorFlow必非一件簡單的事,LinkedIn調查了市面上現存的解決方案,但終究沒能符合需求。有一個Apache Spark運算引擎TensorFlow的開源解決方案,能夠在框架上執行一些LinkedIn內部深度學習應用程式,但其缺乏GPU調度和異構容器調度是最後不被採用的致命傷。而另一個TensorFlowOnYARN獨立函式庫則較接近LinkedIn的需求,但是其容錯以及可用性較差,且該專案已經停止維護更新。
基於這些原因,LinkedIn只好開始動手開發自家基於Hadoop YARN的TensorFlow解決方案TonY,以便可以完全控制Hadoop叢集資源,TonY直接在YARN上運作,並以輕量相依執行,因此除了可以在YARN中使用堆疊較低階的部分,也能使用TensorFlow中堆疊高階的部分。
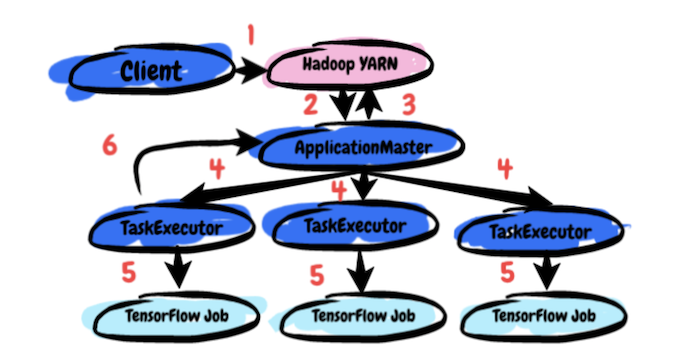
LinkedIn提到,TonY運作TensorFlow的方法,類似在Hadoop中MapReduce引擎執行Pig與Hive腳本,或是在Spark中以API執行Scala程式碼,TonY透過處理資源溝通或是容器環境設定等任務,支援TensorFlow的工作。TonY主要有3個元件,客戶端、ApplicationMaster和TaskExecutor。使用者向客戶端提交TensorFlow模型訓練程式碼、參數以及Python虛擬環境,並由客戶端設定ApplicationMaster將其交付給YARN叢集,ApplicationMaster會根據用戶的資源要求,與YARN的資源管理器進行資源協商,當ApplicationMaster收到確定的資源分配,便會在分配的節點上創建TaskExecutors,由TaskExecutors啟動用戶的訓練程式碼並等待工作完成。
TonY除了可以完成基本在Hadoop上執行分散式TensorFlow的工作外,也實作了用來支援大規模訓練的功能。TonY支援GPU調度,能夠利用Hadoop的API向叢集請求GPU資源。另外,還支援高精度的資源請求,由於TonY能請求不同的實體作為單獨的元件,因此用戶可以針對每種實體類型請求不同的資源,也就是說,用戶可以良好的控制應用程式使用的資源,同時也有助於叢集管理員避免浪費硬體資源。
TonY現在可以將應用程式追蹤的URL重新導向TensorBoard上,讓使用者方便透過TensorBoard理解、調校和最佳化TensorFlow應用程式。而TonY重要的特色之一便是容錯,可以讓深度學習訓練更可靠。即便使用大量的機器,TensorFlow訓練仍可能需要數小時甚至數天,但長時間運作的TensorFlow任務比短期的任務,更容易受到暫時性錯誤或搶占的問題影響。TensorFlow擁有容錯API,可以將檢查點儲存成HDFS,還能從先前保存的檢查點恢復繼續訓練。TonY則透過提供彈性分散式基礎架構,來從節點故障中恢復,因此當Worker錯誤、或是ApplicationMaster失去回應等情況,TonY將會重新啟動應用程式,並恢復到之前的檢查點。
現在LinkedIn在GitHub上開源他們在Hadoop和TensorFlow上的努力,讓其他使用者也能方便的建置分散式機器學習應用。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10


2026-02-06

2026-02-10