Uber
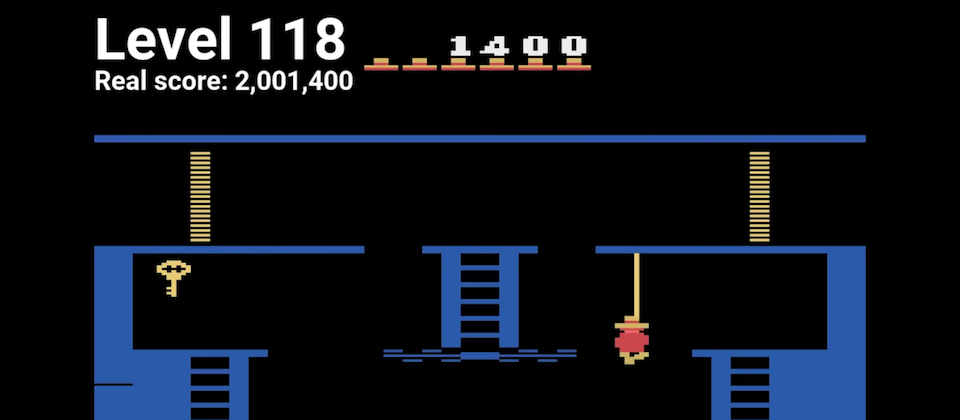
在AI玩遊戲的研究中,Atari發行的「蒙特祖馬的復仇」(Montezuma’s Revenge)和「陷阱」(Pitfall)一直都被公認為AI難以突破的最難遊戲,這兩款遊戲中都體現了真實世界問題的挑戰,這種問題被稱為探索問題(Hard-exploration problem),而Uber的AI實驗室最近發表新型機器學習演算法Go-Explore,不需要人類的示範,該AI程式創下高分的超人類表現,在蒙特祖馬的復仇這款遊戲中,AI程式最高獲得超過2,000,000分,超越人類玩家最高記錄分數,而平均也拿下超過400,000分,並突破到第159關,在陷阱這款遊戲中,AI程式則是獲得平均21,000分,遠遠超越人類玩家的平均表現。
與其他AI程式不同,Go-Explore並沒有用人類的示範作為訓練資料,而是從人類的專業知識中學習,該演算法與其他深度學習演算法有很大的不同,Uber認為,該演算法能夠在多種具有不同挑戰的問題中,獲得很大的進展,特別是在機器人的開發上。
蒙特祖馬復仇遊戲中的探索問題挑戰在於,程式必須在很少的獎勵訊號,或是具有混淆性的回饋機制中,學習複雜的任務,由於只有非常少量的回饋訊號,隨機的行為很難產生有效的回饋,也使得程式難以在執行中自我學習,而在陷阱遊戲中,甚至,有些回饋是令人混淆的,導致程式學習到錯誤的行為,因為許多行為會導致小的負面回饋,像是打敵人,因此程式就學習到不要採取行動,因而永遠無法收集到珍貴的寶物,這些情況其實正是在真實世界中的問題。
為了解決這類型的挑戰,現有深度學習演算法會加入內在動機(intrinsic motivation)機制,在程式進階到新的狀況或是到達新的位置時,給予獎勵,但是這樣的方式對於探索還是有所限制,舉例來說,當給AI程式在2個迷宮探索時,一開始程式選擇了其中一個迷宮的入口,進入迷宮開始探索後,會因為不斷更新位置得到獎勵,但是程式完成一個迷宮的探索之後,對於一開始放棄另一個迷宮的行為並沒有明確的記憶,更糟的是,前往另一個迷宮的路徑已經被認定為探索過的位置,因此,由於不會獲得獎勵,AI程式不太可能重新探索該區域。
Go-Explore將學習分為2個階段,包含探索和穩固(robustification),第一階段系統進行探索時,會同時記錄探索的路徑,並往返可能的區域進行探索,檢查是否有助於提供更好的效果,Go-Explore試圖探索所有可能到達的區域,因此不容易受到混淆回饋機制影響,第二階段則是透過模仿學習找出最佳穿越路徑。Uber研究團隊表示,這項研究成果解決了探索增強學習的問題,也開啟了許多研究方向,包含用不同的方式記錄探索路徑、挑選往返探索位置的方法、不同的探索方式等。
日前DeepMind和OpenAI也有發布用AI程式玩蒙特祖馬復仇的研究成果,DeepMind是利用模仿學習(Imitation Learning)來讓AI程式學習玩遊戲,OpenAI則是從人類遊戲示範中挑選一段適當的狀態,使用近端政策最佳化(Proximal Policy Optimization,PPO)的增強學習來學習遊戲。
熱門新聞

2026-02-11

2026-02-12
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-09


2026-02-13

2026-02-10