Google近日針對超越固定長度的上下文資料,發布全新的NLU架構Transformer-XL,並將Transformer-XL於GitHub上開源釋出,包含研究論文中用到的預先訓練的模型、超參數和程式碼。現今的自然語言理解模型有一定的限制,由於上下文之間的依賴性,導致既有的自然語言理解模型,在面對篇幅較長的上下文理解時,效果有限。
在自然語言理解研究中,通常必須使用前面的片段資訊來了解當前的訊息,稱之為長期依賴性(long-range dependence),簡單來說,就是為了正確地理解一篇文章,有時候需要參考數千個字之前的一個單詞或是一個句子,大多數的研究人員用神經網路處理這項問題時,會用門控循環網路(Gating-based RNNs)和梯度裁剪(gradient clipping )技術,來改善長期依賴模型,但是還是不足以完全解決這項問題。
目前最好的方法是透過Google於2017年推出的NLU神經網路架構Transformers,Transformers允許數據元(data unit)之間直接連接的特性,能夠有效地擷取長期依賴性,但是在語言建模中,Transformers目前實現的方法適用於固定長度的文章,舉例來說,一個長篇文章會被切成由幾百個字符組成的固定長度的片段,每個片段再分開處理,而這樣的方法有2大限制,一是該演算法無法為超過固定長度的文字篇幅建立依賴模型,二是裁切片段的程式無法識別句子的邊界,導致上下文破碎化而難以優化,這個問題就算對長期依賴性不強的較短序列而言,也是非常麻煩。
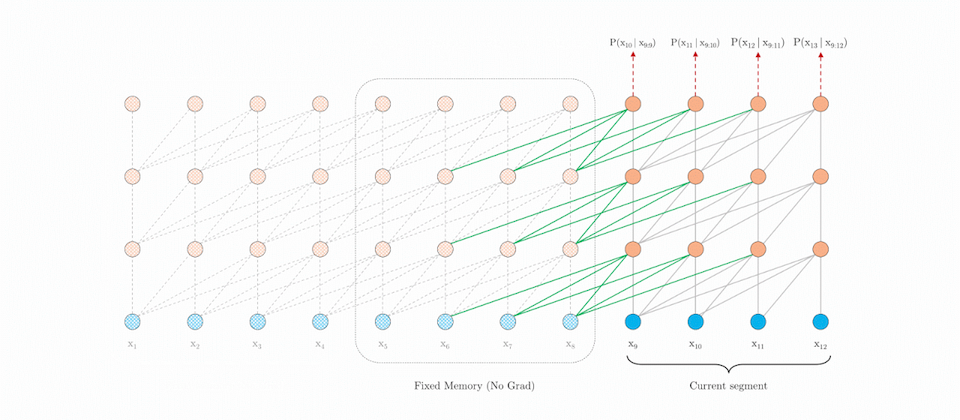
為了解決上述的限制,Google針對超越固定長度的上下文資料,發布了全新的NLU架構Transformer-XL,該架構包含2項技術: 片段式遞迴機制(segment-level recurrence mechanism)和相對位置編碼設計(relative positional encoding scheme)。
片段式遞迴機制是在訓練的過程中,將前一個片段的計算結果修復並保存,以利在下一個新的片段執行時重新利用,由於上下文資訊可以在片段的邊界中流動,神經網路深度有幾層,這項額外的連接機制就能為依賴關係的長度提升幾倍,除此之外,遞迴的機制也解決了上下文破碎化的問題,提供新的片段上下文必要的標註。
而當系統要重複使用上一個片段的結果時,必須將上一個片段的編碼位置,整合至新的片段位置編碼中,這樣的操作會導致位置編碼不連貫,為了實現片段式遞迴機制,因此需要搭配相對位置編碼的設計,與其他相對位置編碼設計不同的是,Google是用可學習的轉換固定向量,如此一來,該相對位置編碼設計能夠更廣泛地適用於較長的序列中。
Google研究團隊實驗發現,Transformer-XL比vanilla Transformer模型更能有效地理解更長的上下文,且不需要重新計算就能處理新片段的資料,因此大幅提升自然語言理解的效能,Google認為,該研究成果可以改善語言模型預先訓練的方法、創造逼真的長篇文章,也能協助影像和語音領域的應用開發。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09

2026-02-10


2026-02-10

2026-02-10