
由Apache Spark技術團隊所創立的資料科學公司Databricks,在其整合分析平臺(Unified Analytics Platform)加入自動化機器學習功能(AutoML),讓未經專業訓練的使用者,也能夠簡單地創建機器學習模型。
創建機器學習模型並非簡單的工作,通常需要訓練有素的資料科學家,準備大量的訓練資料才能完成,更進階的需求還有特徵工程、超參數調校、自動模型追蹤、產品化以及部署等工作。Databricks提到,企業對於機器學習功能的需求很大,大型企業每年可能需要創建幾百個模型,來解決各領域的問題,但是由於資料科學人才不足的緣故,企業通常也只實現了一小部分。
而Databricks在整合分析平臺中加入自動化機器學習功能,要來彌補這個需求落差,幫助未經受訓的人員,也能夠順利地創建並訓練機器學習模型。
整合分析平臺新增了AutoML Toolkit以及自定義AutoML解決方案。AutoML Toolkit提供了自動化端到端機器學習工作管線功能,目標是要讓使用者從特徵工程開始,到超參數調校、模型搜尋以及最終部署階段,整個過程都可以不需要撰寫程式碼,但同時也提供精細的控制,讓資料科學家可以在過程進行必要的微調。
Databricks的開源機器學習平臺MLflow則能自動追蹤AutoML Toolkit的執行狀況,使用者能在MLflow觀看模型結果與訓練執行。
而自定義的AutoML解決方案,給資料科學家足夠的靈活性,設計機器學習工作管線。整合分析平臺讓資料科學家,能夠在同一個地方完成ETL、模型建置到模型推理等工作,透過與熱門的函式庫整合,資料科學家可彈性地控制端到端機器學習工作管線,並由系統自動執行生產作業需要執行的步驟。
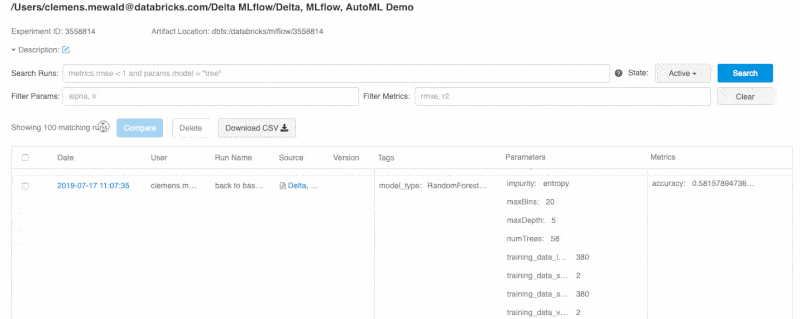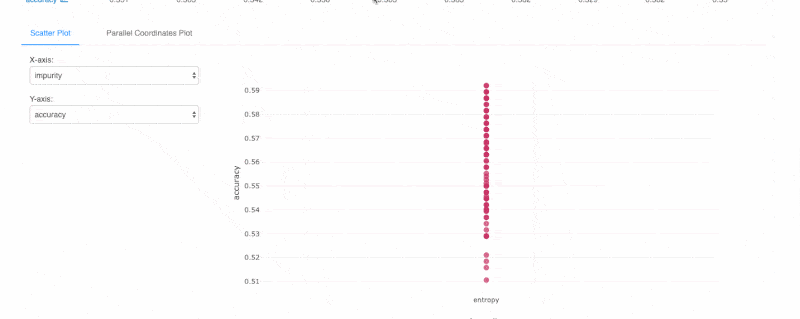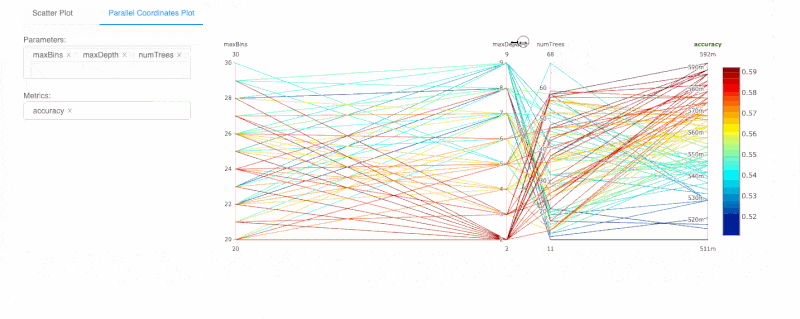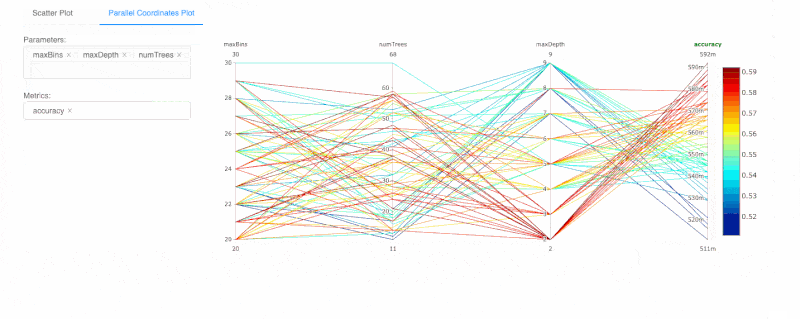
Databricks Runtime也整合了HyperOpt、MLlib以及MLflow,簡化分散式超參數調校(下圖)與模型搜尋工作,用戶能以強化的HyperOpt以及MLflow自動追蹤功能,搜尋最佳化和分散式條件的超參數,並獲得強化的資料視覺化功能。另外,Databricks Runtime還支援熱門開源機器學習框架,諸如TensorFlow、PyTorch與scikit-learn等,資料科學家經整合且最佳化過的工具,進行分散式深度學習訓練,也能以MLflow內建的實驗和視覺化追蹤,幫助調校超參數工作。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10

2026-02-06

2026-02-10
