
目前是Kepler專案核心成員之一的IBM東京研究院研究科學家Marcelo Carneiro do Amaral指出, Kepler專案成立的目的是,建立一個開源工具,能夠跨平臺上統一執行並收集能耗相關指標數據。
隨著多雲混合雲架構成為主流,許多公司正在使用不同的雲端供應商的服務,但也增加雲原生碳排追蹤的挑戰。「這正是Kepler專案的目的,要建立一個開源工具,能夠跨平臺統一執行並收集能耗相關指標數據」。Kepler專案核心成員之一的IBM東京研究院研究科學家Marcelo Carneiro do Amaral說。
這位隸屬於IBM混合雲部門的研究員,長期專注於雲端運算工作負載、工作負載最佳化、資源管理、平行與分散式系統及系統效能評估的研究,尤其是微服務工作負載效能最佳化及混合雲可擴展性的改進。
邁向雲原生永續IT有四大階段
Marcelo歸納,企業發展雲原生永續IT,可分為4個階段,分別是量化、評估、優化、自動化四個階段。首先企業需進行量化,計算雲端應用程式的能耗,藉此了解各應用、每個工作負載、租用VM、容器及服務所消耗的能源與碳足跡數據。接著進入評估和分析階段,企業需識別出高耗能應用,並透過調度框架進行優化,以提高能源效率,最後階段是自動化,透過自動化控制改善應用程式和資料中心資源管理,達成更永續的營運效率與環境效益。
不過,Marcelo直言,目前企業要落實雲原生IT永續最大的挑戰是,缺乏統一的指標來監控雲原生環境的IT能耗與碳排放。
他解釋,不同雲端供應商在雲端服務能耗計算,經常採用不同的標準,尤其是碳足跡的計算,存在顯著差異,甚至在私有雲和公有雲環境中所使用的碳排放指標也可能不同,導致企業難以整合來自不同供應商或環境的能耗資訊,進行一致地追蹤與管理。Marcelo強調,這正是Kepler推出的目的,要來解決這個問題。
Marcelo指出:「Kepler專案的目標是打造一個雲原生永續監控工具的開源版本,能在多平臺上統一執行並收集能耗的指標,讓任何人都能在不同環境中使用相同的標準進行計算。」
Kepler工具在K8s叢集監控最小單位是Process
目前公雲巨頭的碳排放監控工具,大多以個別服務或產品為最小單位,如Google Cloud碳足跡儀表板工具,而且多採取每月更新,缺乏更即時的數據,甚至,多家工具僅提供碳排放數據,未涵蓋能源使用情況。此外,儀表板可查看的資訊,通常是所有應用程式和服務加總合計的整體碳排放資訊,較缺乏個別應用程式的詳細碳排數據,也就難以準確評估應用程式行為並做出有針對性的能源效率改進。
相較之下,他表示,Kepler的監控方式更為精細,最小管理單位是Process,能直接在Kubernetes平臺中監控到系統底層的Process的能耗變化,可提供小時甚至分鐘級別的能耗數據。
他解釋,Process是作業系統層級的基本運作單位。例如,在一個容器中可能同時執行多個Process,如網頁伺服器和資料庫等,每個這類小元件的執行都可以是一個Process;一個容器內可以有多個Process,多個容器再構成一個Pod。因此,用戶可藉由Kepler精細地監控到單一Pod、單一容器、單一Process能耗數據,無論這些工作負載部署在公有雲的虛擬環境(VM)或裸機環境(Bare Metal)的Kubernetes叢集上都能掌握。
Marcelo表示,數據顆粒度越細緻,代表更清楚地掌握應用程式中各元件的能耗情況,讓企業能針對性地調整和優化,例如針對高能耗的應用進行程式碼最佳化。此外,企業還可分析雲端應用程式的能耗隨季節變化或晝夜交替的趨勢,進一步提升能耗管理的效率。
取得雲原生應用的能耗數據後,企業可以將每個容器或運算節點所消耗的kWh能耗數據乘上碳排放因子,換算出相應的碳排放量。此外,還可以透過K8s軟體控制器工具SusQL和碳感知SDK工具來動態追蹤碳足跡,將這些能耗數據自動轉換成碳排放量,並匯出到Prometheus中彙整,最後再透過Gafana儀表板進行視覺化呈現。
甚至,時間顆粒度上,Marcelo強調,Kepler可以提供到以秒為單位的能耗指標,結合碳感知SDK使用,能實現更精細的碳排放追蹤。
不僅能追蹤K8s叢集的能耗變化,Kepler本身還可監控非K8s環境的設備能耗數據,例如邊緣運算設備。他指出,Kepler以Process作為最小監控單位,因此可監控作業系統中執行的所有資源,包括Docker容器等,提供靈活的監控解決方案。
因應GenAI的發展,Marcelo表示,這讓Kepler工具變得非常重要,企業可以使用Kepler來監控GenAI專案的工作負載,估算出推論與訓練過程中的能源消耗,作為優化LLM模型能耗的依據,不僅有助於降低模型的能耗,使其更具永續性,還能在環境友善的資料中心內完成模型訓練。
Marcelo提到,最近就有企業為了因應歐洲法規需求,要求IBM提供LLM模型的能耗報告。IBM團隊正使用Kepler工具來取得LLM模型在訓練和推理階段的能耗數據。
Kepler提供裸機和虛擬環境兩種部署途徑
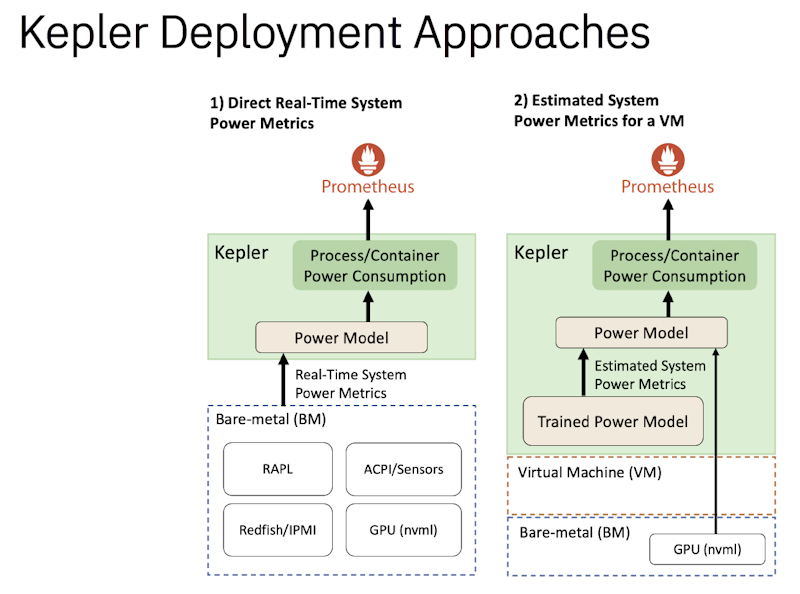
Kepler目前提供了兩種部署途徑,因應裸機環境(Bare Metal)與公有雲虛擬環境(VM)中 Kubernetes 叢集的能耗數據蒐集需求。在裸機環境中,企業可直接透過硬體感測器即時獲取系統功率指標;在公有雲虛擬機器環境中,由於雲端供應商未公開硬體感測器的數據,需依訓練好的功率模型來推論背後的功率數據,提供給Kepler使用,來推估能耗數據。 (圖片來源/IBM)
他指出,Kepler目前提供了裸機環境(Bare Metal)與公雲的虛擬環境(VM)兩種部署途徑,根據不同的部署方式,測量的能耗結果的準確度可能會有所差異。
在裸機環境中,由於可以直接存取硬體感測器上的數據,Kepler能夠直接獲取CPU使用率、記憶體和GPU操作等系統指標來估算能耗。例如,當一個Process使用了10%的CPU,也就占用了CPU功耗的10%,進而精確測量每個Process、容器或Pod的能耗數據。
相比之下,在公雲的虛擬環境上,因為雲端供應商未公開硬體感測器的數據,Kepler無法直接測量VM的功耗,只能依賴事先訓練的功率預測模型,來推估每個虛擬機器的功耗,因此,在公雲虛擬環境中的能耗測量準確度不及裸機環境。
在公雲環境中,Kepler推估VM的功率需要一個功率模型,這個功率模型必須在模型伺服器上完成訓練,先用裸機的數據訓練出一個功率模型之後,再把整套模型伺服器軟體裝到和Kepler相同的執行環境,來根據該環境提供的資訊來推論背後的功率數據,提供給Kepler使用,來推估能耗數據。
Marcelo強調,Kepler專案團隊正持續改進Kepler工具,以提升功率模型的準確性。例如針對亞馬遜AWS等公雲使用的硬體訓練專屬功率模型。此外,隨著新處理器的推出,團隊也會陸續增加更多功率模型。
Kepler近期新增VM功耗建模功能,開始支援蒐集EC2 Spot實例的能耗數據,也利用開放功耗資料庫SPECpower來訓練模型,此外,還能結合Kuberentes雲原生CI/CD工具Tekton,建立自動化模型訓練流程。
但他坦言,目前在公有雲虛擬機環境中,使用功率模型進行估算,雖已盡可能接近實際數據,但準確度仍難達到100%。他期盼未來雲端供應商能公開每臺虛擬機的能耗數據,以便更精確地計算雲端應用的能耗數據。
Kepler推出不到兩年,吸引越來越多的雲原生社群的重視,例如KubeCon的美洲和歐洲年在近兩年會均設有專場,專門介紹Kepler工的應用。不少國際重要組織將Kepler列入雲原生永續發展的重要參考工具。例如綠色軟體基金會(GSF)在其雲端供應商即時雲端能耗標準的參考中納入了這項工具。由歐洲電信商和網路供應商成立的電信雲和邊緣永續專案Sylva也在永續雲端基礎設施參考架構整合Kepler。此外,歐洲電信標準協會(ETSI)在其節能網路指南中進一步引用Kepler,推動綠色網路的發展。
近來,還有不少雲原生永續新專案與Kepler工具結合,逐漸形成生態系,像是Peaks專案可以感知功耗變化並調整工作負載排程,優化Kubernetes資源分配與調度。Clever專案則可利用ML模型預測和調整Pod資源使用進行調度等。

熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09

2026-02-06


2026-02-09

2026-02-09