
Xtreme基準中所支援的多項語言任務
Google發布自然語言處理系統基準測試Xtreme,其提供9項任務,涵蓋40種語言12個語系,多語言模型通過對各種語言,與不同等級的語法以及語意推理等任務後,便能依得分評估其效能。Xtreme可以評估人工智慧模型跨語言擷取共享知識的能力,而這有助於推動自然語言應用的發展。
自然語言處理主要的挑戰,在於要能夠建立一個可使用全世界6,900種語言的系統,Google提到,雖然大多數的語言都缺乏資料,並不足以單獨訓練出夠強健的模型,但幸運的是,這其中有不少語言,都共享大量的基礎結構,且在詞彙上,也有不少來自於同一來源,像是英文的Desk和德文的Tisch,都來自於拉丁文Discus,另外,也有不少語言的語意角色(Semantic Role)相似,像是土耳其語和中文都使用後置介詞,描述字詞之間的時間和空間關係。
因此,在自然語言處理中,仍有許多方法可以在訓練中,利用多語言共享結構,來克服資料稀疏的問題,Google提到,深度學習過去幾年的發展,學習通用多語言表示的方法數量已經有所成長,不過,這些方法都還是有所限制,只能處理少量的任務,以及聚焦在相似的語言上。
為了推動多語言學習的研究,Google發布了XTREME,這是一個評估跨語言泛化的大規模多語言多任務基準,XTREME中涵蓋許多未被充分研究的語言,目的是要最大程度提高語言多樣性,增加現有語言任務覆蓋範圍以及訓練資料的可用性;像是XTREME包含還在印度南部、斯里蘭卡和新加坡使用的達羅毗荼語系泰米爾語,以及受非洲地區民眾使用的尼日剛果語系中的史瓦希利語和約魯巴語。
Xtreme中的9項任務,包括了語句分類、結構預測、語句檢索和問答等,要使用XTREME評估模型效能,模型必須要使用可促進跨語言學習的多語言文字進行預訓練,而Xtreme會利用零樣本評估方法,來評估這些模型跨語言的轉換效能,也就是要求模型對未曾訓練過的語言資料進行預測,計算所有Xtreme任務的綜合得分。
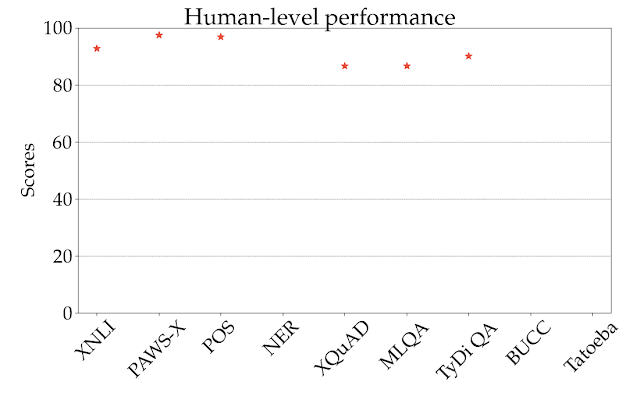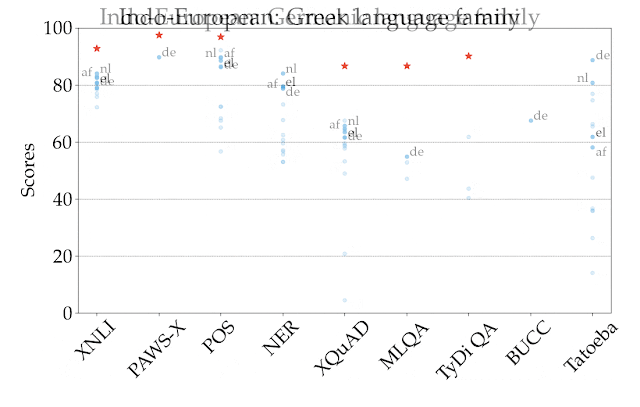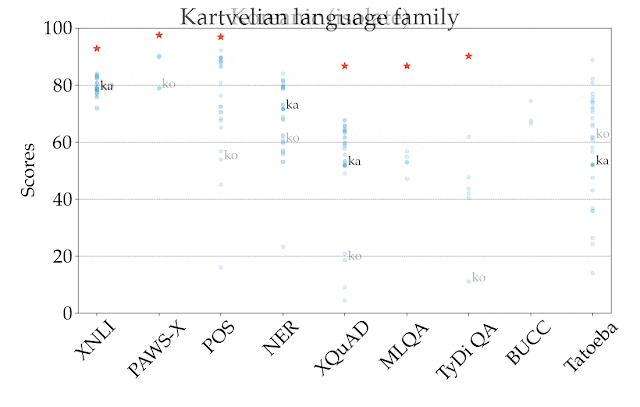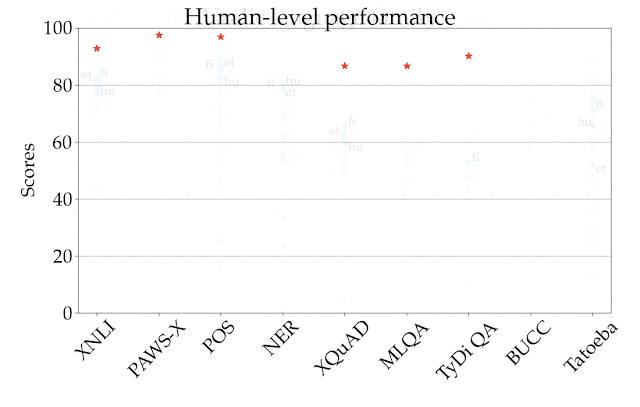
Google在Xtreme中進行初步的實驗,發現即便是目前最先進的多語言預訓練模型,包括mBERT、XLM、XLM-R與M4都表現不佳,即便這些模型都已經使用大量多語言資料進行訓練,也能在英文的表現接近人類,但是在其他語言上的表現,效能明顯較英文表現低落。
這些模型仍然很難把知識轉移到非拉丁語系,這個結果在各模型於部分語音標記任務上的表現可以很清楚看到,mBERT在西班牙零樣本評估的準確度達到86.9,但是日語只有49.2;且所有模型都難以在距英語遙遠的語言,預測沒有在英文訓練資料中看過的實體,相較於葡萄牙語和法語的準確度有82.3和80.1,印尼文和史瓦希利語的精確度只有58.0和66.6。
實驗結果顯示,所有模型在英語和其他語言之間的效能差距仍然非常大,這代表在跨語言轉換上,還有很大的研究潛力,Google提到,說英文的人口僅占全世界的15%,但是英文卻一直是自然語言處理的重點,他們希望XTREME能夠促進多語言遷移學習的發展。
熱門新聞

2026-02-09

2026-02-10

2026-02-06

2026-02-09

2026-02-10

2026-02-10

2026-02-09
