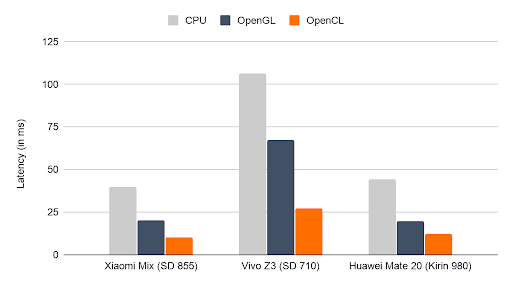
,拿來比較CPU、OpenGL和OpenCL的效能表現,無論是在MNASNet或MobileNet v3,新的OpenCL後端延遲都是最低的,約是OpenGL後端的2倍。(圖片來源/TFLite)")
TFLite開發團隊將常用的2個行動機器學習模型MNASNet和MobileNet v3(如上圖),拿來比較CPU、OpenGL和OpenCL的效能表現,無論是在MNASNet或MobileNet v3,新的OpenCL後端延遲都是最低的,約是OpenGL後端的2倍。(圖片來源/TFLite)
TensorFlow團隊以異構平臺開發框架OpenCL為基礎,在Android開發了新的行動GPU推理引擎,在適當大小的神經網路上,以及足夠的GPU工作負載,其執行的效率是現有OpenGL後端的2倍。
目前常用的GPU推理引擎是以OpenGL開發,是一種渲染圖形API,雖然在OpenGL ES 3.1版本加入了運算著色器(Compute Shader),可用來計算任意的資訊,但開發團隊提到,其為了要向後相容的API設計,限制了GPU的運算能力,因此TensorFlow Lite(TFLite) GPU團隊在繼續發展基於OpenGL行動CPU推理引擎的同時,也在尋求各種可能性。

Duo App中的AR效果,使用OpenCL後端處理
而同樣可用來發展機器學習應用的OpenCL(Open Computing Language),一開始就是為各種計算加速器設計,更適合用於行動GPU推理,所以TFLite開發團隊便也投入資源,研究基於OpenCL的推理引擎,發現其確實能用來最佳化GPU推理工作負載。TFLite開發團隊提到,與OpenGL相比,最佳化OpenCL後端要簡單許多,因為OpenCL提供良好的分析功能,利用概要分析API,開發團隊能夠精確地量測核心調度效能。
OpenCL能夠良好地支援用於高階Android行動裝置的高通Adreno GPU,但是Adreno GPU對於工作組大小非常敏感,配置適當大小的神經網路工作組可以提高效能,錯誤大小的工作組,卻會降低效能,雖然在具有複雜記憶體存取模式的複雜核心,要找出適當的工作組大小並不容易,但是因為OpenCL具有完整的效能分析功能,因此可被用來最佳化工作組大小,使平均運算速度提升50%。
而且OpenCL還原生支援16位元浮點數精度,即便是在2012年推出的Adreno 305老舊GPU,都夠完全發揮GPU的效能,另外,OpenCL具有常數記憶體(Constant Memory)的概念,高通在GPU加入的實體記憶體非常適合用於OpenCL的常數記憶體,這使得OpenCL在高通GPU的效能大幅超過OpenGL。
TFLite開發團隊將常用的2個行動機器學習模型MNASNet和MobileNet v3,拿來比較CPU、OpenGL和OpenCL的效能表現,無論是在MNASNet(如下圖)或MobileNet v3,新的OpenCL後端延遲都是最低的,約是OpenGL後端的2倍,而且在標有SD字樣使用Adreno GPU的裝置上,OpenCL後端效能表現特別好。
開發團隊提到,使用OpenCL推理引擎的主要障礙,是OpenCL不包含在標準Android發布版中,即便有一些Android裝置廠商在系統函式庫加入OpenCL,但是部分用戶還是可能因為缺乏OpenCL必要元件,則必須回退使用OpenGL後端。
為了簡化開發人員的工作,TFLite GPU一開始會檢查OpenCL Runtime的可用性,當不可用或無法載入時,便會切換使用OpenGL後端,開發團隊提到,從2019年中期開始,OpenCL後端就進到TensorFlow存儲庫中,並整合進TFLite GPU委託API裡,因此現有TFLite GPU程式可能已經透過委託回退機制,使用到了最新的OpenCL後端。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10


2026-02-06

2026-02-10