
近日一篇Transformer匿名論文引起ML注目,它強調只以Transformer進行大規模預訓練,其影像分類表現比卷積網路要好,而且更省運算資源。
匿名作者
重點新聞(1009~1015)
卷積網路 Transformer 影像辨識
再見了卷積網路,一篇Transformer匿名論文激起ML社群關注
一直以來,卷積網路(CNN)是影像辨識的首選,但近日一篇匿名論文(An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale)引起ML社群關注,就連DeepMind研究科學家Oriol Vinyals、Tesla的AI總監Andrej Karpathy和發明AlexNet的OpenAI首席科學家Ilya Sutskever都表示期待。
該論文指出,在電腦視覺中,注意力機制不是與CNN共用,就是替代CNN中一些元件,來保持適當結構。然而,作者認為,這種對CNN的依賴是沒必要的,而且直接利用Transformer來處理影像Patch序列,其影像分類能力會比CNN出色。論文強調,Transformer以大量資料進行預訓練且遷移至多種影像辨識benchmark時(如ImageNet, CIFAR-100和VTAB等),其表現不僅能比高階CNN要好,所需的硬體資源還少了許多。
這篇論文目前正接受國際頂尖AI盛會ICLR 2021的評審,因此無法透露作者姓名。不過,外界推測是Google研究團隊,因為論文採用的資料集JFT-300M只限Google內部研究使用。該資料集擁有3億張影像、近兩千個類別,供Google用來改善電腦視覺演算法。(詳全文)
.JPG)
Performer 硬體資源 Google
比Transformer更經濟實惠!Google聯手推Performer架構
Google聯手DeepMind、劍橋大學、Alan Turing研究所,共同設計一款改良版Transformer架構Performer,解決Transformer耗費過多硬體資源的問題。
一般來說,Transformer的自我注意力機制解決了RNN梯度消失的問題,其注意力機制可學習分辨輸入值序列中的複雜依賴關係。然而,隨著輸入值增加,Transformer就會增長4倍,所需的硬體資源也就更多。為解決問題,團隊以快速注意力機制FAVOR+為骨幹,打造出Performer架構,能快速、準確地估算Softmax注意力排名,且不依賴稀疏性和低等級等先驗條件,可解決耗費硬體資源的問題。團隊也以Performer進行一系列測試,範圍涵蓋像素預測、蛋白質序列建模,結果證實Performer除能耗費較少資源,還比基準模型快上兩倍、準確率也有所提升。(詳全文)
手語偵測 即時辨識 光流
Google打造視訊會議手語辨識模型,助聾啞人士即時發聲
Google聯手以色列巴伊蘭大學、瑞士蘇黎世大學,開發一套即時手語偵測模型,可即時在視訊會議場合中辨識手語人士,並設置為主要發言人。該模型在瀏覽器上執行,輕量且容易上手,能從畫面中分離出人體動作和關節變化等訊息,大幅降低運算整幀HD影像的負擔。
進一步來說,模型除了從每幀影像擷取關節點,也會累積每幀的光流(Optical flow)變化,這些光流特徵會送至LSTM模型,來分類是否為手語姿勢。團隊利用德國手語資料庫(DGS)來測試,光只一層LSTM和一層線性層,模型準確率最高可達91.5%,且每幀處理時間只需3.5毫秒。(詳全文)
聯合學習 模型權重 氧氣照護
Nvidia揭露COVID-19聯合學習進展,模型AUC達0.94
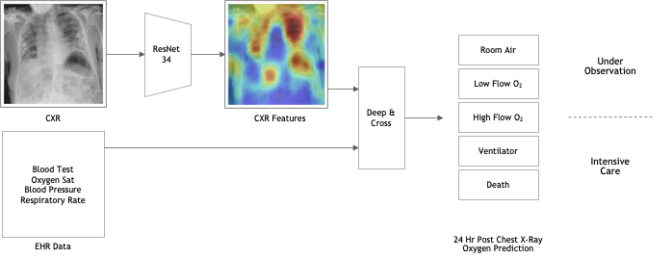
Nvidia發起COVID-19聯合學習計畫EXAM,在不侵犯資料隱私的前提下,跨國聯合20家醫療機構,打造一套病情惡化模型,能根據患者狀況來預測未來數小時至數天內,是否需要氧氣治療。
Nvidia聯手美國權威醫院麻省布萊根綜合醫院,邀集歐、美、亞等全球20個醫療相關機構,包括臺灣健保署、臺灣大學醫學影像與數據人工智慧(MeDA)實驗室、三軍總醫院在內,以Nvidia Clara和自家醫療數據如生理數值和胸部X光片等,來訓練本地模型,再將模型權重上傳至AWS託管的母模型,來優化母模型,而優化過的權重也會開放各醫院下載、進行另一輪訓練。Nvidia指出,目前該模型的AUC區域已達0.94(目標為1.0),數周後將對外公開模型相關內容。(詳全文)
Nvidia AI視訊 Maxine
用AI打造低頻寬高解析度體驗,Nvidia推出AI視訊串流平臺
Nvidia日前在GTC大會上,推出雲端GPU加持的AI視訊會議套件Maxine,只需H.264串流影像標準的十分之一頻寬,就能傳輸影像。這是因為,Maxine不會串流整張畫面的像素,而是以AI分析每個會議參與者的臉部關鍵點,並在雲端GPU上執行壓縮處理,因此需傳輸的資料比整個畫面少上許多。
此外,Maxine還應用GAN技術,來提供如臉部自動校正、視線校正,以及噪音消除和臉部打光等功能。此外,由於Maxine採用雲端原生架構,開發者還能利用Kubernetes的擴展性縮放服務規模。(詳全文)
arXiv 程式碼 機器學習
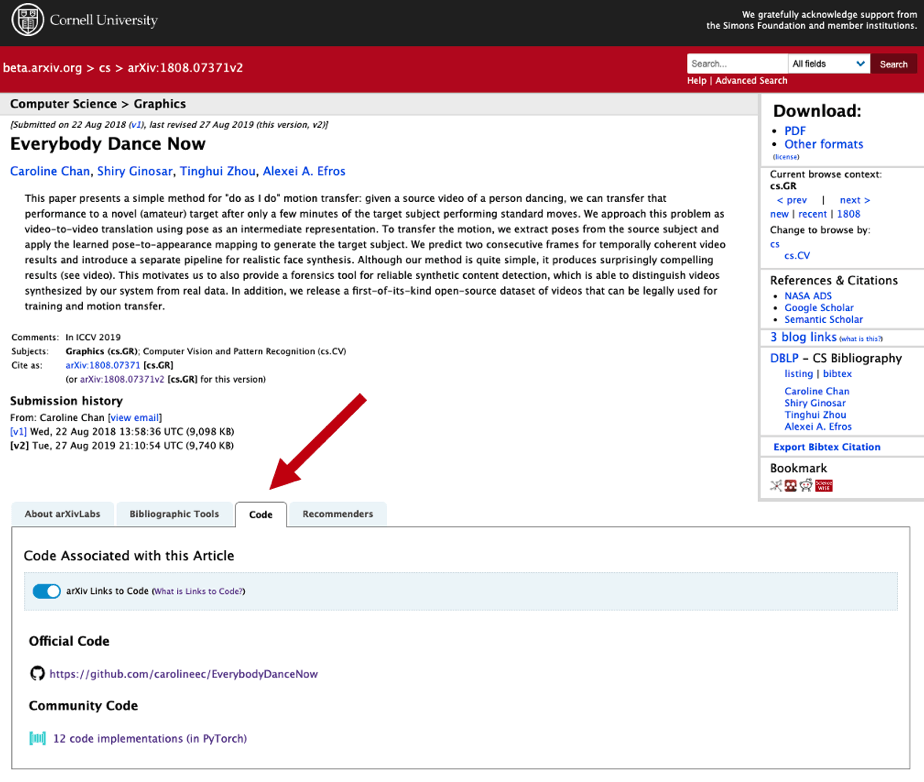
論文網站arXiv提供程式碼連結功能,可邊讀論文邊驗證
收集各領域論文的網站arXiv聯手機器學習論文平臺Papers with Code,在網頁添加程式碼頁籤,讓機器學習論文作者,可提供相關程式碼,連結機器學習論文與程式碼,方便讀者用來驗證。
作者可點擊論文標題旁的Papers with Code圖標,來提供相關程式碼。這時頁面會切換至Papers with Code,作者加入實作程式碼後,arXiv摘要頁面即顯示相關程式碼,方便讀者查詢存取。(詳全文)
物資交流 配對演算法 臉書
缺口罩嗎?臉書配對演算法強化物資交流
為解決武漢肺炎帶來的物資不足問題,臉書以配對演算法,連結不認識的使用者,來促進資源交流,像是當使用者在臉書發布需要口罩的貼文,AI就會推薦能提供口罩的鄰居,讓該使用者認識。
臉書以XLM-R模型來建置配對演算法,XLM-R是臉書跨語言理解模型XLM以及RoBERTa的擴展,能夠產生相關性分數,配對社群中需要幫助,以及能夠提供幫助的使用者。XLM-R能夠辨識含義相似的貼文,並且進行配對,即便貼文語意結構不同,XLM-R也能處理。(詳全文)
肺水腫 急性心臟病 胸部X光片
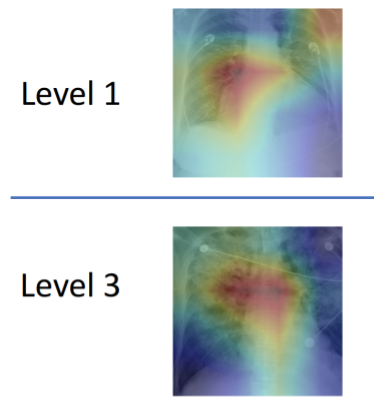
MIT打造肺水腫AI,助醫生在黃金時間搶救急性心臟病患
MIT團隊開發一套機器學習模型,能從肺部X光片中量化肺水腫嚴重程度,分為0到3級。團隊指出,肺水腫是急性心臟衰竭的常見症狀,其嚴重程度會影響治療決策。
為解決問題,MIT找來4位放射科醫師,在現有的X光片公開影像資料集中,加入嚴重程度註解。於是,團隊以30萬張X光片影像,以及放射科醫師寫下的相對應報告文本來訓練模型。不過,這些文本通常只有1至2個句子,且不同醫生的描述風格不同、使用廣泛術語,因此,為了讓系統能夠理解報告文本,團隊制定一套語言規則和字詞替代,以確保能一致分析報告文本。經測試,模型能正確判別50%案例的嚴重等級,而對於嚴重程度等級3的案例,90%都能正確預測結果。MIT已與醫院合作,將整合至急診室中。(詳全文)
圖片來源/Google、Nvidia、arXiv、MIT
AI趨勢近期新聞
1. 微軟更新ONNX Runtime支援行動平臺
2. 鎖定農業,Alphabet射月專案公開智慧農業AI機器人
3. Google雲端服務支援雲端原生容器映像檔技術Buildpacks
資料來源:iThome整理,2020年10月
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-09

2026-02-06

2026-02-09