
AMD釋出最新的Instinct MI100加速器,該加速器是目前最快的HPC GPU,其採用AMD CDNA架構,並使用AMD Matrix Cores技術,與第二代AMD EPYC處理器搭配使用,可提供超過10 TFLOPS的FP64效能,而在FP32矩陣巔峰效能則達46.1 TFLOPS,可大幅加速人工智慧與機器學習工作負載,而在FP16的理論巔峰效能,是前一代的7倍。
MI100加速器專為超級電腦設計,超級電腦可用來執行天氣預測,或是物理模擬等運算密集的工作,過去這些工作主要由CPU負擔運算,但隨著科學運算應用越來越多機器學習技術,GPU逐漸變得重要,超級電腦也開始大量採用GPU,透過大規模平行化運算,來加速機器學習運算。
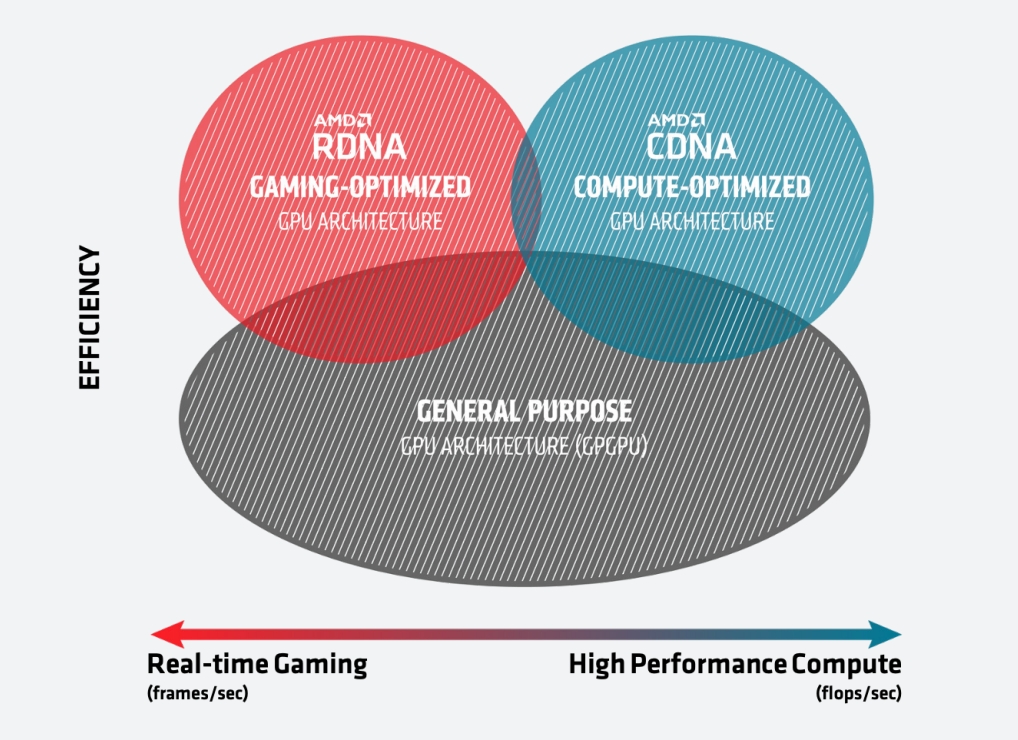
7奈米的MI100 GPU採用最新的CDNA架構,CDNA架構是專為HPC與人工智慧工作負載設計,能夠強化運算的需求,CDNA架構與繪圖用的AMD RDNA架構不同,因為HPC與人工智慧運算不需要圖形加速運算,因此CDNA架構移除了光柵化、圖形快取以及顯示引擎等功能硬體,但保留了HEVC、H.264和VP9解碼的專用邏輯,因此CDNA架構GPU仍可以用來處理多媒體運算,像是物體偵測等機器學習應用,而刪除圖形加速用硬體的CDNA架構,剛好也能釋放更多的空間,以投資其他運算單元,增加效能與效率。
MI100 GPU應用了全新Matrix Cores技術,可以極大程度的增加人工智慧的運算效能,該技術可以提高像是FP32、FP16或是INT8等,各種精度和混合精度矩陣的運算效能,甚至可以將FP32矩陣運算效能,提高到46.1 TFLOPS,在人工智慧訓練工作負載,FP16理論峰值浮點數效能,還可以提升到將近上一代的7倍。
AMD提到,MI100 GPU由幾個主要模塊構成,這些模塊以晶圓級的互連晶片陣列(On-die Fabric)捆綁在一起,並使用PCIe 4.0介面將GPU連接到CPU,可以支援GPU到CPU間連接頻寬16 GT/s,雙向的速度皆可達32 GB/s。另外,MI100加速器使用32 GB超快速第二代高頻寬記憶體(HBM2),提供超高1.23 TB/s記憶體頻寬,能滿足超大型資料集流入流出的需求,而不會產生資料瓶頸。
超級電腦會由數臺伺服器組合而成,每臺伺服器都可以搭載多顆GPU,為了支援這種多顆GPU架構,MI100整合了一項稱為Infinity Fabric的技術,可在PCIe 4.0提供2倍點對點高峰I/O頻寬,當存在3個Infinity Fabric連結,就可讓每張加速卡頻寬高達340 GB/s。

MI100 GPU受到注目,是因為MI100是同類產品中最快的晶片,目前唯一在FP64,突破10 TFLOPS的x86伺服器GPU,可達11.5 TFLOPS高峰效能,而FP32工作負載,則提供23.1 TFLOPS的峰值效能,根據AMD的實驗,無論是在FP64還是FP32,都比起競爭對手NVidia A100 GPU效能更好。

熱門新聞

2026-02-13

2026-02-13

2026-02-13

2026-02-13

2026-02-13

2026-02-13


2026-02-13