分散式發布與訂閱系統Apache Kafka在即將發布的2.8版本,使用Kafka內部的仲裁(Quorum)控制器來取代ZooKeeper,因此用戶第一次可在完全不需要ZooKeeper的情況下執行Kafka,這不只節省運算資源,並且也使得Kafka效能更好,還可支援規模更大的叢集。
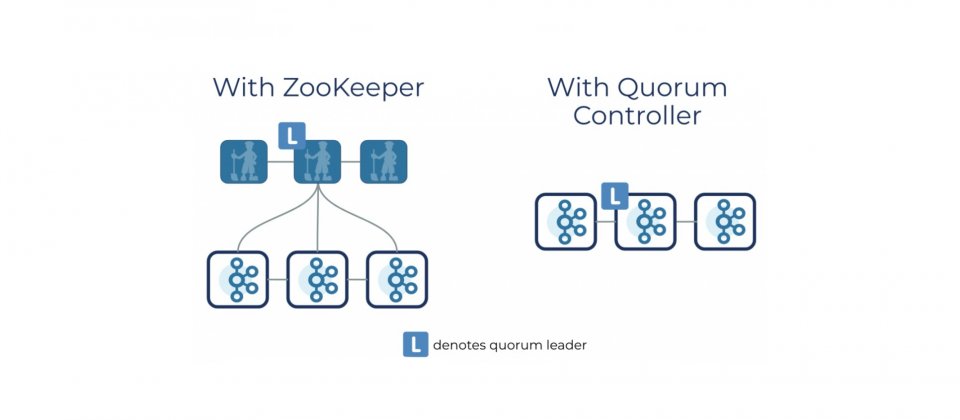
過去Apache ZooKeeper是Kafka這類分散式系統的關鍵,因為ZooKeeper管理元資料,儲存著資料分割的位置,以及主要副本等資訊,ZooKeeper扮演協調代理的角色,所有代理伺服器啟動時,都會連接到Zookeeper進行註冊,當代理狀態發生變化時,Zookeeper也會儲存這些資料,在過去,ZooKeeper是一個強大的工具,但是畢竟ZooKeeper是一個獨立的軟體,使得Kafka整個系統變得複雜,因此官方決定使用內部仲裁控制器來取代ZooKeeper。
這項工作從去年4月開始,而現在這項工作取得部分成果,用戶將可以在2.8版本,在沒有ZooKeeper的情況下執行Kafka,官方稱這項功能為Kafka Raft元資料模式(KRaft)。在KRaft模式,過去由Kafka控制器和ZooKeeper所操作的元資料,將合併到這個新的Quorum控制器,並且在Kafka叢集內部執行,當然,如果使用者有特殊使用情境,Quorum控制器也可以在專用的硬體上執行。
在Kafka內部執行的Quorum控制器,會使用新的KRaft協定來確保仲裁間能精確地複製元資料副本,並使用事件來源儲存模型來儲存狀態,以確保內部狀態機可以精確地被重新創建,官方提到,KRaft協定具有的事件驅動特性,和基於ZooKeeper控制器不同,不會在啟動之前從ZooKeeper載入裝態,當領導節點變更的時候,新啟用的控制器記憶體早已紀錄所有提交的元資料。
另外,KRaft協定使用事件驅動機制來追蹤整個叢集的元資料,過去必須仰賴RPC來處理的任務,現在受益於事件驅動以及實際的日誌傳輸,這些改變所帶來的好處,便是讓Kafka仍夠支援更多的分割。
新的仲裁控制器是專門設計在單個叢集中,處理大量的分割,在過去的實作中,受限於重要的元資料,必須要在外部共識機制ZooKeeper,以及內部領導控制器Kafka間移動,Kafka僅能達到20萬個分割,而在新的仲裁控制器中,過去外部共識與領導管理的角色,都由同一個元件扮演,因此現在於單個叢集中,分割數可以達到過去10倍,約是2百萬個分割。
過去Kafka因為帶著ZooKeeper,因此被認為擁有沈重的基礎設施,而在移除ZooKeeper之後,Kafka更輕巧更適用於小規模工作負載,輕量級單體程式適合用於邊緣以及輕量級硬體解決方案。
值得注意的是,在搶先體驗版中,有部分像是ACL、安全以及交易等功能都尚未支援,而且在KRaft模式下,也還不支援重新分配分割和JBOD,官方提到,這些功能會在今年稍晚的版本中提供,而且因為仲裁控制器還在實驗階段,也不建議將其用於生產環境中。
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
2026-02-09
")
")
2026-02-09

2026-02-09