臉書發表最新的語音辨識技術Wav2vec-U,這是Wav2vec非監督式版本,可以讓研究人員不需要將語音轉錄成文字資料,就可以訓練模型的方法,Wav2vec-U的效能已經可媲美幾年前,使用1,000小時轉錄語音資料訓練的監督式模型。
無論是回答問題還是執行請求,語音辨識技術已經被廣泛地應用在各種情境,但現今的語音辨識系統,僅對少數語言友善,研究人員解釋,這是因為需要大量的轉錄音訊,才能夠訓練出高品質的語音辨識系統,但是每種語言、方言或是說話方式並無法輕易的取得這樣的資料。
因此臉書開發了Wav2vec-U,這是一種不需要轉錄資料的語音辨識系統方法,臉書已經在Swahili和Tatar等語言測試該模型,由於這些語言缺乏大量帶有標籤的訓練資料,因此一直沒有高品質的語音辨識模型。
Wav2vec-U能純粹從錄製的語音音訊和未配對的文字中學習,過程不需要進行任何轉錄的工作,與過去的自動語音辨識系統相比,臉書採用了一種新方法,能夠從未標記的音訊中學習語音結構,結合Wav2vec-U和k-平均演算法,就能將語音分割出各個對應的語音單元,像是把CAT這個詞分割成/K/、/AE/和/T/。
為了要學習辨識語音中的單詞,研究人員訓練了由生成網路(Generator)和判別網路(Discriminator)組成的生成對抗網路(GAN),其生成網路使用嵌入在自我監督表示中的每個音訊片段,並預測和語言中聲音相對符的音位(Phoneme),目的是要試圖欺騙判別網路來進行訓練,判別網路會評估預測的音位序列是否逼真。最初生成網路產生的結果很差,但是經過判別網路的回饋,生成網路產生的結果會更加準確。
研究人員提到,判別網路本身也是一個神經網路,透過將生成網路的輸出當做輸入,以及來自各種音元化的真實文本,能訓練判別網路學會區分由生成網路產生的輸出和真實文本。
研究人員將Wav2vec-U與其他模型比較,以評估Wav2vec-U的效能,在TIMIT基準測試中,與最佳的非監督式方法相比,Wav2vec-U錯誤率降低57%,而在更大型的Librispeech基準測試中,Wav2vec-U與基準中歷年最佳效能的監督式模型相比(下圖),Wav2vec-U在沒有任何轉錄資料訓練下,和2019年使用960小時轉錄資料訓練的模型效能不相上下。
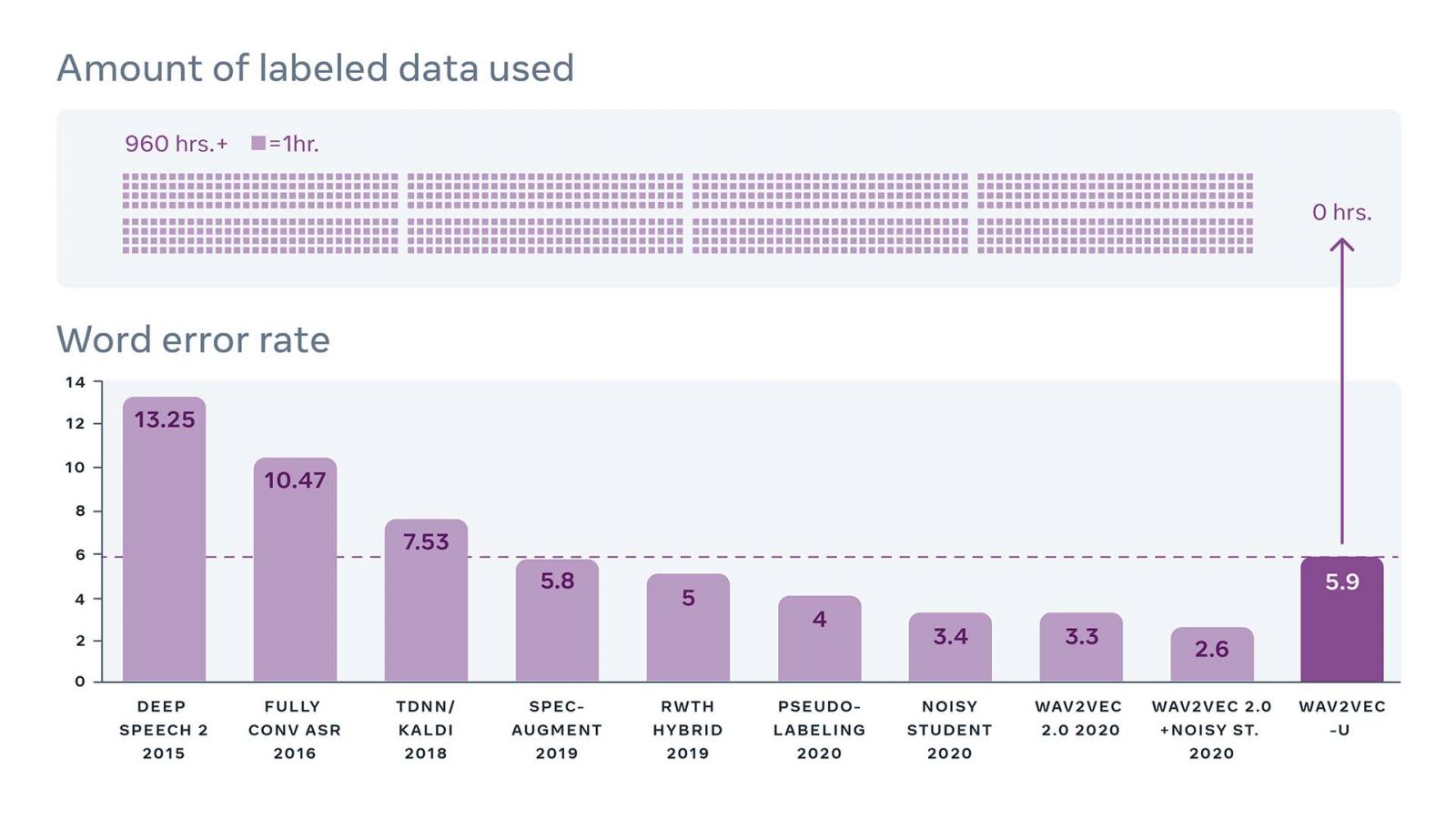
TIMIT和Librispeech都是用來評估英文系統的基準測試,但英文由於有大量的標籤資料集,已經存在極佳的語音辨識技術,而非監督式語音辨識,將對於缺乏標籤資料的語言,產生極大的影響。因此研究人員也開始在Swahili、Tatar和Kyrgyz等標籤資源匱乏的語言中,研究使用Wav2vec-U。
臉書提到,Wav2vec-U是他們在語音辨識、自我監督學習和非監督式機器翻譯上多年的成果,讓模型僅透過觀察就可以習得解決任務的能力,這項成果將使得語音技術為更多人所用。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10


2026-02-06

2026-02-10