
Google旗下人工智慧研究公司Deepmind最近發表了數篇關於語言模型的論文,其中重要的論文包括訓練具有2,800億參數的語言模型Gopher,還提出一個改進的語言模型架構,來降低訓練模型的能源成本。
之所以DeepMind團隊致力於研究人工智慧的語言處理和溝通,他們提到,語言是人類說明和促進理解的基本,能夠讓人們交流思想、表達想法、創造記憶並且相互理解,而這同時也是社交智慧的基礎部分。研究人員認為,開發更強大的語言模型,對於人工智慧系統的研究具有很大的潛力,能夠有效率地總結資訊、提供專家建議,並且以自然語言提供指引。
在DeepMind的新論文中,訓練了大大小小的Transformer語言模型,從4,400萬個參數到2,800億個參數的模型都有,最大的模型被命名為Gopher。研究人員透過調查這些不同大小模型的優勢和缺點,找出能夠藉由增加規模,繼續提高效能的領域,像是在閱讀理解、事實查核和有毒語言辨識上,而研究人員也發現,在邏輯推理和常識性任務中,模型的規模並無法明顯改善結果。
經過DeepMind的研究,他們發現Gopher的能力,在許多重要的任務上都超過現有的語言模型,例如大規模多任務語言理解(Massive Multitask Language Understanding,MMLU)基準測試,Gopher在許多方面都勝過當前先進的語言模型GPT-3和UnifiedQA,包括人性、社會科學和醫療等。
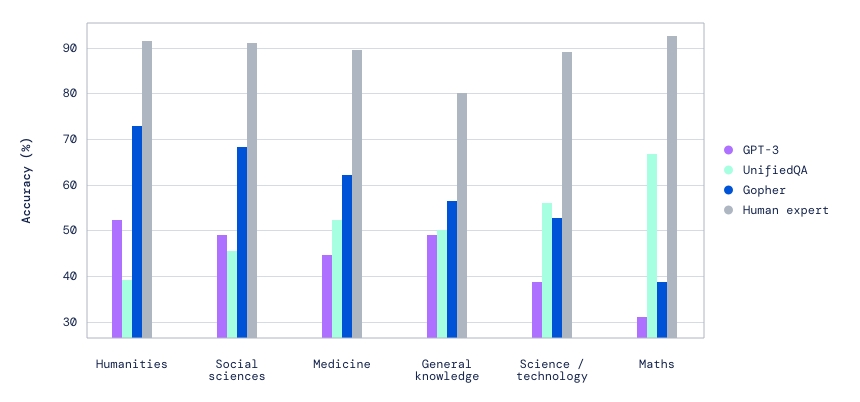
研究人員除了對Gopher進行定量評估之外,也透過實際互動探索模型,發現Gopher在被提示進行對話互動時,能夠提供良好的連貫性,即便開發人員沒有對特定對話微調,但是Gopher竟然可以討論細胞生物學,並且引用正確的文獻。
除了大模型帶來的優點之外,研究人員也探討了幾種在任何模型大小中,都持續存在的故障模式,諸如反覆傾向(Tendency for Repetition)、刻板印象和傳播不正確資訊。研究人員提到,這些研究之所以重要,是因為可以藉由理解和記錄故障模式,來進一步掌握大型語言模型對下游應用造成的危害,並且知道該朝哪個方向前進,來緩解這些問題。
除此之外,DeepMind還提出了一種改進的語言模型架構,該架構能夠降低訓練能源成本,並且使模型輸出更容易追溯至訓練語料庫中的來源。研究人員受大腦在學習時,仰賴專用記憶機制的啟發,開發出了RETRO(Retrieval-Enhanced Transformer),藉由使用網際網路規模的檢索機制,來預訓練模型,RETRO能夠有效地查詢文本段落來改進預測,並且透過將生成的文字和RETRO生成所仰賴的段落進行比較,研究人員可以解釋模型做出部分預測時的原因和來源。
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
2026-02-09
")
")
2026-02-09

2026-02-09