Google釋出了一個專為存儲和操作N維資料設計的C++、Python開源軟體函式庫TensorStore,其提供一個統一的API,讓用戶讀取各種陣列格式,像是zarr和N5,TensorStore原生支援多種儲存系統,並且具有強ACID保證,能夠以非同步API支援針對高延遲遠端儲存的高吞吐量存取。
TensorStore的出現,是要解決機器學習迅速發展,對大規模資料集的存取需求,許多先進的機器學習應用程式,皆需要用到多維資料集,像是在空間網格上測量大氣,並對天氣進行建模,或是醫學成像3D掃描等,而這些應用即便僅需要一個資料集,但規模也會屬於TB或是PB等級。
研究人員提到,要使用這類大型資料集極具挑戰,因為用戶可能以不規則區間,或是不同的規模讀取和寫入資料,並且還可能需要用到大量的機器。
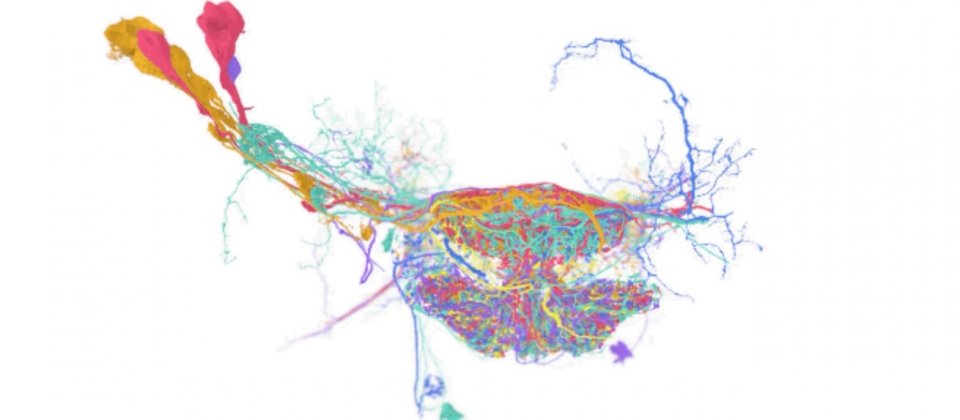
而Google所開發的TensorStore,可用於儲存像是具有數十億立體像素(Voxel)的蒼蠅大腦3D圖像,TensorStore提供使用者簡單Python API,能夠輕鬆載入和操作大型資料庫,並以NumPy陣列存取小批次資料。
在用戶真正請求特定資料切片之前,TensorStore不會存取或是在記憶體中儲存實際資料,所以能夠支援用戶載入和操作任意大小的基礎資料集,不需要將整個資料集搬到記憶體中,就能夠使用與標準NumPy操作相同的語法進行索引和操作。TensorStore針對進階索引功能提供廣泛的支援,包括轉換、對齊和產生虛擬檢視表等。
研究人員提到,處理和分析大型數值資料集,需要大量的運算資源,透過平行化GPU和加速器核心實作,這些資源通常分散在眾多機器上。TensorStore的基本目標,便是要能夠對單個資料集進行安全平行處理,使這些資料集不會因為平行存取模式,而產生損壞或是不一致,但又同時維持高效能。在Google資料中心的實驗,隨著CPU數量的增加,TensorStore的高效能特性使讀寫效能可以幾乎呈現線性成長。
另外,TensorStore可以透過配置記憶體快取和非同步API,允許程式在執行其他工作時,在後臺繼續進行讀取和寫入操作,而當多臺機器同時存取同一個資料集時,TensorStore藉由樂觀並行控制(Optimistic Concurrency)技術,保持並行操作的安全性,且不會明顯影響效能。TensorStore也對單個Runtime的所有個別操作提供強ACID執行。
由於TensorStore整合諸如Apache Beam和Dask等平行運算函式庫,因此TensorStore的分散式運算,與企業現有資料處理工作流程高度相容。TensorStore的用例包括語言模型,可在訓練過程高效讀取和寫入模型參數,另外也能用於大腦映射上,儲存用於描繪大腦神經的高解析度映射圖。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-09

2026-02-06

2026-02-09