
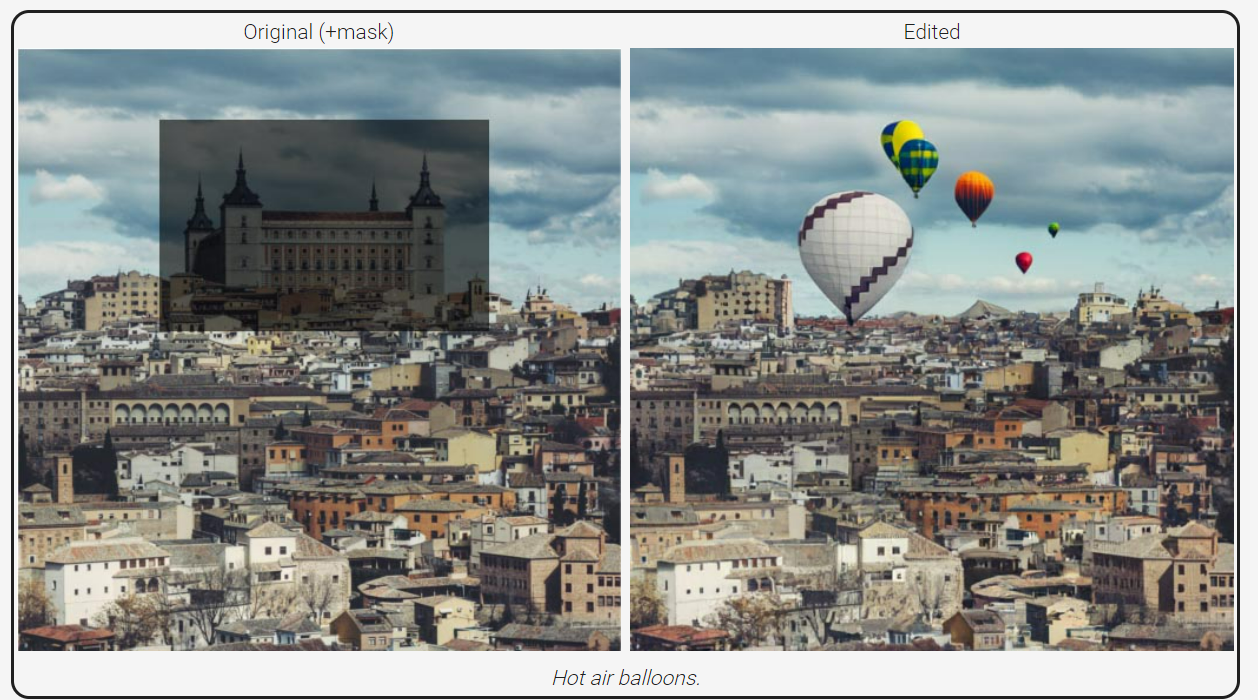
微軟打造文字生成語音模型VALL-E,只要輸入目標文字和3秒目標聲音,模型就能產出高相似度的目標語音,就像是語音版的DALL-E一樣。
微軟
重點新聞(1230~0105)
微軟 VALL-E 文字轉語音
語音版DALL-E!微軟文字轉語音AI給3秒樣本就能準確生成
微軟近日發表一套文字轉語音模型VALL-E,可根據文字輸入和3秒的語音樣本,來合成、產出目標語音,就像是OpenAI的文字轉圖片模型DALL-E一樣。微軟表示,他們用現成神經音檔編解碼模型中的離散碼,來訓練VALL-E這套神經編解碼器語言模型,把文字轉語音視為條件式語言建模任務,而不是像一般研究,視為連續性的訊號迴歸任務。
在預訓練階段,團隊將文字轉語音的訓練資料,擴充到6萬小時的英語語音,是現有系統的幾百倍。VALL-E的工作流程是音素→離散碼→波形,先根據文字輸入和3秒語音提示(也就是想聽到的目標聲音),來產出與文字和目標聲音相應的離散音檔編解碼。
微軟測試發現,VALL-E在語音自然度和相似度部分,表現比現有SOTA文字轉語音模型要好,而且還能保有語音提示的情緒與聲音環境。團隊指出,VALL-E可直接用於各種語音合成應用,如零樣本文字轉語音、語音編輯,以及搭配GPT-3等生成式AI模型,來生成更多內容。(詳全文)

大型模型 BigScience PETALS
在家也能跑千億參數模型!BigScience開源PETALS分散式AI專案
對語言模型來說,參數越多、模型表現越好,開發者也只需微調大型預訓練模型,就能得到不錯的預測結果。不過,BLOOM、PaLM、GPT等這類大型語言模型,即便開源,還是會耗費大量運算資源,雖然目前有2種方法來解決該問題,如RAM卸載和託管API,但前者對交互推論來說太慢,後者則不夠靈活。
於是,由世界各地研究員組成的開源研究專案BigScience,日前開發一套系統PETALS,可在受信任的的條件下,集各使用者之力,來共同微調、推論千億參數的大模型。也就是說,每個使用者只需要載入一小部分的模型,就能和其他使用者一起協作,來共同執行模型推論和微調,就像是BT原理一樣。
團隊測試發現,PETALS比在單一系統的RAM卸載方法,還要快上許多倍,在消費型GPU上推論1,760億參數的BLOOM模型,完成1個token所需時間近1秒。透過平行推論,每秒則能完成數百個token。而且,有別於大多數的推論API,PETALS還能顯示模型隱藏狀態,讓使用者可用有效的微調方法,來訓練、分享客製模型的外掛。不過,在PETALS初始階段,使用者可能因安全、隱私考量,協作進展可能較慢,因此BigScience推出BLOOM點數,來獎勵貢獻GPU資源的使用者。(詳全文)
百度研究院 大模型 產業化
百度研究院預測2023年:大模型將產業化
百度研究院日前發布科技趨勢預測,直言大型模型在2023年將產業化發展,用於更廣泛的產業中。百度研究院指出,現今的AI不斷朝跨任務、跨模態(資料類型)發展,且隨著底層大模型技術的成熟,以及為特定產業發展的AI基礎建設,這種產業型的大模型,已漸漸在航太、金融、能源等領域應用,形成「AI+產業」的發展結構。百度認為,大模型產業化將催生產業大模型生態,實現普惠AI。
此外,百度研究院也預測,2023年的新型AI基礎設施需求將增長、更多產業講過應用AI機器人、AI將進入更多科學領域,以及隨著雲原生技術的成熟,將催生更多量子軟硬體合一的解決方案。此外,可解釋AI技術和科技永續發展,也在百度研究院預測的科技趨勢中。(詳全文)
Nvidia 機器人訓練 元宇宙
讓機器人更靈活!Nvidia更新模擬訓練平臺功能
Nvidia更新機器人模擬和訓練平臺Isaac Sim,使用者可從雲端存取Isaac Sim、使用新AI功能來加速機器人訓練了。Isaac Sim建立在元宇宙平臺Nvidia Omniverse上,使用者可在各種操作條件下模擬真實環境,建置和測試虛擬機器人,來加速物流、製造和零售等產業的自動化應用。
Isaac Sim新功能有人物模擬功能,能在倉庫和製造設施中增添人物角色,還能讓人物執行不同動作,如推手推車。這個功能可讓開發者觀察,人機互動設計是否順暢,也能讓機器人學習避障和潛在意外。另一個新功能是即時呈現感測器資料,並能用光線追蹤技術模擬光達,在各種照明或反射材質條件下,獲得更準確的感測器資料,來讓機器人模擬更貼近真實世界環境。Isaac Sim其他更新還包括模擬3D物件庫、強化學習工具Isaac Gym,以及協作機器人程式開發工具Isaac Cortex等。
OpenAI Bing ChatGPT
微軟計畫用ChatGPT強化Bing搜尋功能
根據外媒The Information報導,微軟打算用ChatGPT來強化自家搜尋引擎Bing、提供新搜尋功能,預計在3月底推出。此外,微軟還可能用ChatGPT來分析用戶在研究的主題,好提供進一步的搜尋建議。
微軟這一舉動,代表使用OpenAI技術的微軟產品數量持續增加。微軟在2019年10月與OpenAI展開合作,投資10億美元來發展通用AI。2020年,微軟購買GPT-3獨家授權,在自家產品中整合GPT-3。2021年,微軟就在Power Apps中嵌入GPT-3,使缺乏程式開發知識的人,也能利用自然語言開發程式。去年,微軟整合OpenAI DALL-E 2,發布圖像設計應用程式,能根據文字提示生成影像。(詳全文)
元宇宙 自然語言 3D
Nvidia新添元宇宙平臺協作功能和自然語言搜尋服務
Nvidia更新元宇宙平臺Omniverse Enterprise,支援最新GPU技術強化效能和可用性,同時增添新功能,達到即時又精確的模擬品質。此外,Nvidia也更新Omniverse平臺核心,讓使用者快速連接工具、共享虛擬空間中協作。
Omniverse Enterprise是個讓企業用來開發、營運元宇宙應用程式的平臺,新加入的Omniverse連接器,可連接不同3D應用程式,實現無縫工作流程,另也支援如Adobe Substance 3D Painter、Autodesk Alias等軟體。此外,Nvidia也正式推出AI服務Omniverse DeepSearch,使用者可用自然語言或2D參考圖,直覺搜尋大型且未標記的3D資料庫。在平臺核心更新部分,則在用來建置擴充應用程式和微服務的Omniverse Kit SDK中,加入新模板和開發者工作流程,簡化開發作業。(詳全文)
Google 文字轉圖像 Transformer
速度更快、畫面更細緻!Google發表新文字轉圖像模型Muse
Google日前發表一款文字轉圖像模型Muse,以Transformer架構為基礎,號稱產出速度更快、生成畫面更細緻,比擴散模型和自迴歸模型的表現還要好。進一步來說,Muse是以遮罩任務訓練而成,也就是先在大型語言預訓練模型中抽出文字嵌入,再訓練Muse來預測隨機被遮住的圖片Token。
與DALLE-2這類像素空間的模型相比,Muse因為用了離散token,只需少量採樣迭代,因此更有效率。與Parti這類自迴歸模型相比,Muse因為用了平行解碼,因此也更有效率。Google表示,由於採用預訓練大型語言模型,Muse的語言理解能力,以至於從文字轉換為高保真圖片的能力都更細緻,而且對視覺概念的理解力也更強。
團隊也進行測試,9億參數版本的Muse經CC3M資料集測試,達SOTA水準,且用來測量生成圖片和真實圖片相似度的FID分數,達6.06分(越低越相近)。而30億參數版本的Muse,在零樣本COCO資料集測試評估中,得到7.88的FID分數。此外,Muse不必微調模型,就能直接用於圖片編輯應用程式,像是圖片修復、圖片外擴/腦補、編輯等。(詳全文)
圖片來源/微軟、BigScience、Nvidia
AI近期新聞
1. Apple Books新添AI語音功能,電子書可轉為有聲讀物了
2. 前特斯拉AI長Andrej Karpathy開源nanoGPT可優化GPT模型開發
資料來源:iThome整理,2023年1月
熱門新聞

2026-02-11

2026-02-12
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-09


2026-02-10

2026-02-13