")
微軟公布一項AI模型Kosmos-1,除了能理解文字,也能看懂圖片及影像。(圖片來源/微軟)
微軟上周公布一項AI模型Kosmos-1,除了能理解文字,也能看懂圖片及影像,可用於更多任務,像是為影片加字幕說明、看圖片回答文字問題、正確蒐集網頁資訊等等。
微軟在一篇名為《Language Is Not All You Need: Aligning Perception with Language Models》的論文中指出,雖然現行大型語言模型在自然語言處理有很成功的應用,但對於多模態(包括文字、聲音及圖像)資料,仍然很難原生使用大型語言模型。微軟指出,「多模感知」(multimodal perception)能力是通用AI「智能」(intelligence)的必要條件,像是獲取知識並運用於現實生活。而若能增加多模輸入能力,將能大幅拓展語言模型用於高價值任務的可能性,像是多模態機器學習、文件AI智慧以及機器人等。
因此微軟提出多模大型語言模型(Multimodal Large Language Model,MLLM)KOSMOS-1,希望它具備常見多模態(如圖像、文字、聲音)資料、依循指令(即零樣本學習)並在特定條件中學習(少樣本學習)的能力。
.png)
圖片來源/微軟
為了訓練一個能「看」和「說話」的模型,微軟倣效METALM HSD+22的訓練方法來訓練KOSMOS-1。他們使用Transformer模型作為通用介面,再接上感知模組。之後,研究人員以網路上蒐集的多模資料,包括純文字資料、圖文摻雜的任意資訊,及具有文字說明的圖片等來訓練,之後再輸入純語言資料,以校正各模態遵循指令的能力。
微軟以多種任務來評估訓練完成的KOSMOS-1模型,包括語言理解、常識理解、非口語推理(如IQ測驗)、為圖片加文字說明或回答視覺相關的提問,以及零樣本(zero-shot)視覺資料的分類及描述等。其中,實驗結果顯示,16億參數的小型KOSMOS-1模型在零樣本的圖像加文字說明的任務表現尤其優異,而在回答視覺問題方面,只要少量樣本訓練過,KOSMOS-1表現可優於其他模型(包括MetaLM)。
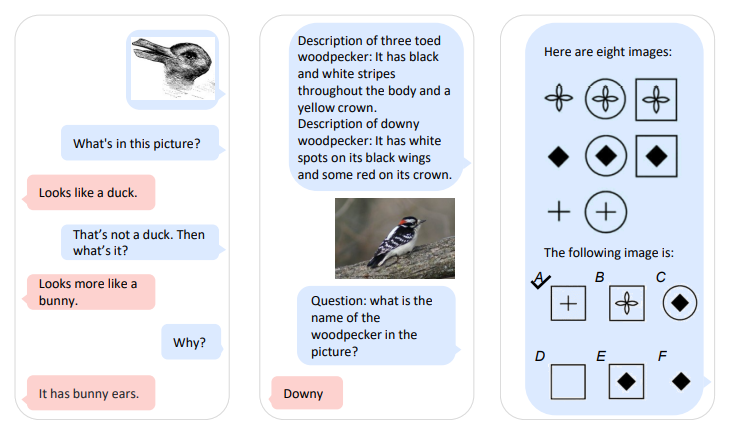
圖片來源/微軟
而在常用的IQ測驗(Raven IQ test)中,KOSMOS-1展現出能理解題目中非口語(如圖片)資料的概念規則,還能自行推論、預測接下來出現的元素(如圖片)。研究人員表示,這是第一個能作答零樣本Raven IQ test的模型。雖然該模型和普通成人推論能力相比還差一截,但展現出零樣本語言模型的非口語理解能力具有相當潛力。另外,KOSMOS-1也可在沒有OCR技術的協助下,讀取及理解圖片中挾雜的文字。若提供文字描述,更能大幅提升這個模型的圖像辨識能力。
Bing二月上線時,在從網頁蒐集公司財報資料出現許多錯誤,這是因為LLM模型並不擅長蒐集資料。為此,研究人員測試了KOSMOS-1依網頁回答問題的能力。實驗顯示,KOSMOS能根據網頁版型及Style資訊理解網頁圖片,又不犠牲語言能力。
此外,研究人員指出,傳統LLM必須仰賴文字資訊和線索來回答視覺常識問題,使其較無法理解物件屬性。相較之下,KOSMOS-1還具備模態轉移力,能將從視覺獲得的知識/資訊轉移到語言任務。
研究人員表示,未來計畫將KOSMOS-1再加以擴大,並整合語言能力。他們相信這多模態大型語言模型處理多型態資料的能力,能用作整合介面,提供多模學習,協助使用指令和範例來控制以語言生成圖像的AI 工具。
熱門新聞

2026-02-11

2026-02-12
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-09

2026-02-13


2026-02-10