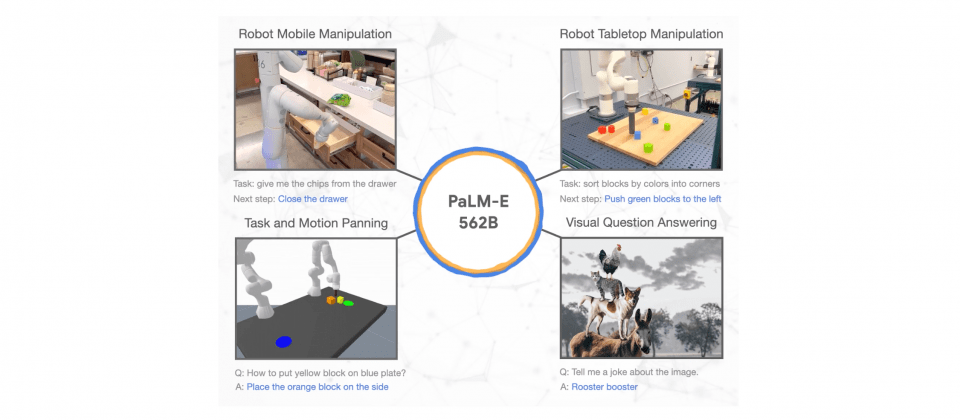
Google發表視覺語言模型PaLM-E,這是一個可用於機器人的嵌入式多模態語言模型,PaLM-E由視覺模型ViT以及語言模型PaLM相結合而成,綜合了語言、視覺和視覺語言的訓練,使機器人可以理解人類的指令,解決需要多種推理能力的長時間指令(Long-Horizon Instruction)。
雖然大型語言模型已被證明足夠強大,可以解決複雜的任務,但是要用於真實世界的一般性推理,像是要讓一個實體機器人聽懂人類語言並且完成任務,仍有一大段距離需要努力,Google提出了實體(Embodied)語言模型,使得語言模型能接受連續的感測器訊號,將文字和感知連結起來。
實體語言模型的輸入是多模態的語句,綜合視覺、連續狀態評估和文字輸入編碼,研究人員端到端訓練這些編碼,結合預訓練的大型語言模型,便能用來完成各種實體任務,諸如機器人操作、視覺問答和產生字幕等。
PaLM-E結合具220億參數的ViT視覺模型,以及5,400億參數的PaLM語言模型,因此PaLM-E總共擁有5,620億個參數。具220億參數的ViT視覺模型是Google在今年發表的大型視覺Transformer模型,ViT使用了在自然語言處理領域中,已經非常成功的視覺Transformer模型,影像訊號會被編碼成序列畫素或是影格,透過Transformer網路進行處理。
而PaLM則是Google研究院在2022年發表的模型,建立在Pathways人工智慧架構之上,運用分散式機器學習加速器,訓練出高達5,400億參數的PaLM語言模型,在語言、推理和程式碼任務都具有良好的表現。
PaLM-E可說是集語言模型技術大成的實體多模態模型,在多種實體裝置上以多種觀察模式,解決各式各樣推理任務,且由於PaLM-E的訓練資料集包括語言、視覺和視覺語言類型,該模型經多樣化資料聯合訓練,因此能夠表現出正遷移的特性,也就是在執行任務時,能夠因為不同的學習經驗而獲得正向影響。
研究人員解釋,Palm-E的主要架構思路是持續注入實體觀察,將圖像、狀態評估和各種感測器模式,輸入到語言模型的語言嵌入空間中。由於圖像、狀態和感測器等觀測資料,都會編碼成和語言權杖嵌入空間相同維度的向量序列,因此語言模型也能夠處理圖像、感測器數值等這類非語言資料,而這些連續資料也以類似語言權杖的方式,持續注入到語言模型中。
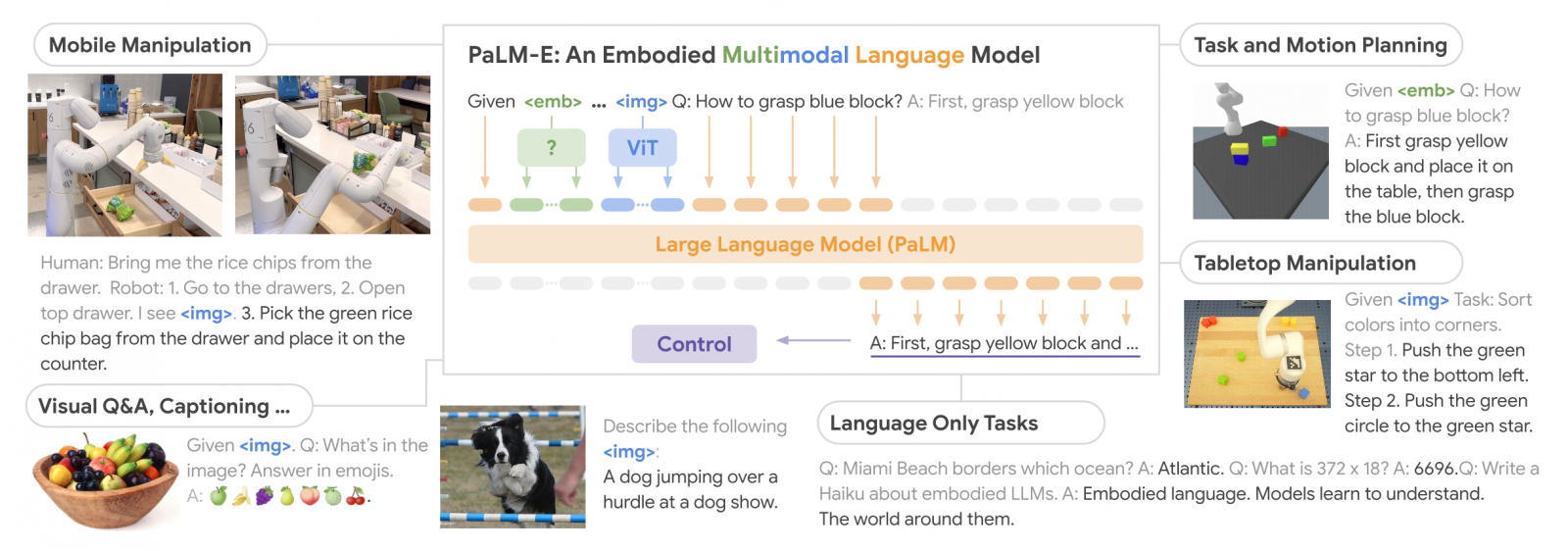
Google展示PaLM-E的範例之一是一個長時間指令「從抽屜拿玉米片給我」,在人工智慧領域的長時間指令,是要求機器人執行一個需要執行多個子任務,才能完成的長任務,而「從抽屜拿玉米片給我」的這項指令,機器人需要聽懂人類的指令,輔以電腦視覺的回饋,移動到櫃子前拿起玉米片,並克服其他研究人員的干擾,將玉米片取回給發出指令的人。
PaLM-E還表現出獨特的泛化能力,即便是指令中包含過去沒有見過的物體,PaLM-E也能驅動機器人完成任務,像是「將綠色積木推給烏龜」的這項範例指令,即便PaLM-E沒有看過烏龜,也能成功執行任務。
除了賦予機器人更強大的能力之外,PaLM-E本身就是一個優秀的視覺語言模型,可以看圖說故事,或是依據圖片內容回答提問。

熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10

2026-02-06


2026-02-10