")
開發物件偵測模型YOLOv7的關鍵人物中研院資訊所助研究員王建堯點出3大技術突破,一是更有效率的網路架構ELAN,二是多任務類神經網路YOLOR,以及使模型具備泛化能力的訓練策略。(攝影/洪政偉)
去年7月7日,YOLOv7問世,一舉打敗各大SOTA物件偵測模型。問起YOLOv7為何能做到這一點,核心開發者中研院資訊所所長廖弘源與中研院資訊所助研究員王建堯親自揭露,關鍵在於更好的類神經網路架構、具備多任務的能力,以及更有效率的訓練策略。
這些突破,始於世界第一物件偵測模型YOLOv4。2020年,他們與YOLO Darknet框架維護者Alexey Bochkovskiy共同打造這個模型,拿下MSCOCO資料集物件偵測大賽第一,無論速度、準確度,都完勝Google、微軟等科技巨頭開發的模型。
但廖弘源與王建堯並未停下腳步,而是繼續朝2方向精進,一是開發更有效率的網路架構,也就是ELAN,二是打造能執行多任務的模型,也就是YOLOR(You Only Learn One Representation)。這兩項突破,構成了YOLOv7的主體,由輕巧高效的ELAN執行影像辨識分析工作,YOLOR則統一整合特徵,兩相加成之下,賦予YOLOv7執行多任務的能力。
關鍵1:輕巧有效率的網路架構ELAN
ELAN是一款特別優化的類神經網路架構,最大特色是省時省力,能更有效率執行物件偵測任務,還能讓模型在硬體資源受限的低階設備或是邊緣裝置上執行。
一般來說,模型要準確辨識出物件,通常得使用複雜的網路架構,比如非常多層的卷積(Convolution),來處理影像特徵,但這就得消耗更多運算資源,因此要在資源有限的低階設備,執行這種高準確度的模型,也就更加困難。
但是,中研院所設計的ELAN架構,只用了1X1卷積和3X3卷積,以及連結(Concatenate)來整合卷積層特徵。這個架構不僅精簡,也只使用最簡單通用的運算單元,能更進一步好好分配運算資源,善用硬體既有資源。這是因為,許多頂尖電腦視覺模型,經常使用數種到數十種不同的運算單元,增加專屬硬體的設計難度和成本,甚至,這些運算單元所需的硬體資源,也不盡相同,反而導致硬體使用率低下。而ELAN架構精簡,解決了這個問題。
不只如此,ELAN架構還改善了前一代模型中耗費記憶體頻寬的設計,比如殘差(Residual)。王建堯指出,電腦視覺模型中的殘差,所需的運算量低、只有卷積的數十萬分之一,但它在邊緣運算設備所需的運算時間,卻是卷積的幾十分之一,浪費了有限的硬體資源。於是,團隊設計ELAN時,就排除殘差,讓類神經網路架構更精簡、更有效率。
不僅去蕪存菁,ELAN還展現王建堯的設計巧思,也就是梯度路徑分析(Gradient path analysis)方法,來提高類神經網路效能。傳統常見的模型優化方法,不外乎是從運算單元設計下手,或是設計一套方法,來讓模型提取符合任務需求的特徵,再整合這些特徵來取得最終結果,但這就偏向傳統機器學習特徵工程思維。梯度路徑分析方法跳脫這個思維,從特徵學習下手,直接「告訴」模型如何學習特徵,並從層(Layer)、階段(Stage)和網路(Network)三層面,來優化模型學習方法。而ELAN,正是網路層級的梯度路徑分析實作。
這些特點,使ELAN成為高效率網路架構,一如其名:高效率層聚合網路(Efficient Layer Aggregation Networks)。團隊也在2020年11月完成開發。
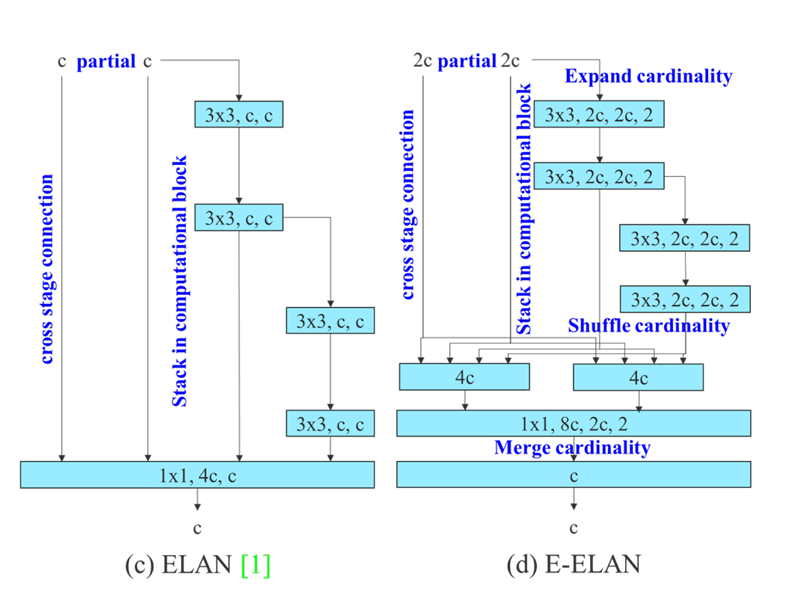
中研院團隊在YOLOv7論文中,解釋他們如何設計擴展版架構E-ELAN的梯度路徑分析方法。這個方法是提高模型學習效率的訓練策略,圖中,E-ELAN並未改變原有架構的梯度傳遞路徑,而是利用分組卷積,來增加特徵基數,並用隨機洗牌與合併等方式來整合特徵組,強化模型學習表徵的能力。圖片來源/王建堯
關鍵2:執行多任務的外掛YOLOR
與前幾代YOLO模型不同,YOLOv7最大特色是一心多用,看一眼就能執行3種任務,包括物件偵測任務、實例分割(Instance segmentation)以及關節點偵測(Keypoint estimation)。
也就是說,YOLOv7可在畫面中用框框框出特定物件,像是行人、建築、交通號誌,也能更細緻地用顏色表示特定物件,就像是替這些物件著色般(這個上色動作也稱為遮罩),此外還能定位畫面中人體的關節點,如頭部、手肘、膝蓋,並將這些關節點連線,就像火柴人一樣,可用來辨識動作和姿態。
YOLOv7為何如此強大?原來它加入了YOLOR。YOLOR是王建堯在2021年5月發表的模型,可以保存所有輸入資料的特徵;它就像一個外掛,能用來提取模型中的隱性知識(Implicit knowledge),讓原本專精單一任務的模型,透過保存起來的特徵,來學習其他任務,而不必針對其他新任務,一一重新訓練。
廖弘源比喻,就像是受過專業訓練的諜報員,被賦予一個任務,要找出照片中的車輛,他會專心記住照片中每輛車,這就是顯性知識(Explicit knowledge),但若突然換個題目,改問照片中有幾位行人,他也能憑記憶正確回答,即便一開始並未被賦予這個任務;這就是隱性知識。對電腦來說,「它就像經專業訓練的諜報員,看一眼就記住所有資訊,就能用這些資訊來執行各種任務,」他說。只不過,目前大多數物件偵測模型,仍仰賴給定的顯性知識來學習任務,很少善用隱性知識執行多任務。
了解YOLOR概念,再從模型架構角度來談,如何實現一心多用的能力。物件偵測模型通常由骨幹(Backbone)、頸(Neck)和頭(Head)三部分組成,其中,骨幹是將任務所需特徵,從不同隱藏層(Hidden layers)抽取出來,編碼至骨幹裡,再由頸部進行特徵組織(Feature organization),最後交給頭部下決策。
假設模型要偵測物件,骨幹得從第1、3、5層提取特徵,再由頸部整合處理;若模型要執行影像分割任務,骨幹可能得提取第2、4、5層特徵。但是,藉由YOLOR這個統一的網路(Unified network),就能在骨幹一次處理不同任務所需的特徵,賦予模型執行多任務的能力。YOLOv7成功問世,也反過來證實了YOLOR外掛模式的可行性。
甚至,YOLOR這種善用模型隱性知識的技術,還能用於近期爆紅的生成式AI。王建堯指出,一些文字轉圖像的生成式AI,會產出6隻手指頭的人像,但若加上類似YOLOR的技術,將已存在於模型的隱性知識提取出來,就能避免產出不合邏輯的圖像。他甚至點出,這類技術研究,也許是臺灣最適合投入發展的領域。
關鍵3:自動學習和具備泛化能力的訓練策略
YOLOv7打敗其他SOTA模型的第3個關鍵,是更好的訓練策略,也就是YOLOv7論文標題強調的Trainable bag-of-freebies。
這個名詞看似複雜,但拆分來看,Bag-of-freebies泛指用來提高模型準確度的訓練方法,亦即模型訓練時常用的技術或策略,這些技術或策略雖會增加訓練成本,但不會增加模型推論時的運算成本,還能提高模型表現,因此稱為免費禮品或贈品(Freebies)。常見的BoF有幾種,如資料增強、正規化(Regularization)、權重初始化等,開發者可用來訓練模型,讓模型更容易調整和優化,達到更好的表現。
但,一般的BoF仍有其局限。舉例來說,資料增強是用來增加訓練資料的多樣性,比如用於物件偵測時,可針對一些小物件來設計資料增強,讓特定物件的訓練資料更多,進而提高模型辨識力。「但這就有所局限,」王建堯解釋,若模型任務與小物件偵測無關,這樣的BoF就無法發揮作用,還可能引起反效果。
於是,團隊設計YOLOv7的BoF時,決定讓它更靈活,讓訓練策略也可以「受訓練」,能根據任務需求自動學習、自動調試,而非生硬地只適用於特定目的。
進一步來說,YOLOv7的BoF包含模型重參數(Model re-parameterization)和動態標籤分配(Dynamic label assignment)兩種,其中,動態標籤分配是近期物件偵測模型的主流優化趨勢,能提高模型對圖像特徵的學習能力,讓模型更準確分辨物件偵測框(Bounding box)中的像素,是否屬於該物件。
有了這個能力,模型就能進一步泛化(Generalize),運用已知知識來解決新任務。也就是說,一個已經由Trainable BoF訓練過的物件偵測模型,不必再透過新資料重新訓練,也可用來執行其他新任務,比如影像分割。
這種泛化能力,也在YOLOR中展現過。王建堯解釋,其實,Trainable BoF最初就用於YOLOR,而YOLOR的成功,證實了這個優化策略可行,能用來改善物件偵測任務表現。這次的YOLOv7,則更進一步證明,Trainable BoF不只能優化模型在物件偵測任務的表現,還能優化實例分割、關節點偵測等不同任務的表現,是發展多任務AI的基石。
兼具這些技術突破的YOLOv7,不論是速度還是準確度,一問世就勝過所有主流物件偵測模型,在每秒5幀到每秒160幀範圍內,表現優於YOLO系列模型和Transformer系列模型。而且,在使用GPU V100、每秒30幀或更多的條件下,YOLOv7平均精度(AP)達到56.8%,是當時所有物件偵測器中,準確度最高的模型。
下一步瞄準多模態多任務,也要用GNN提高解釋性
儘管YOLOv7已經拿下亮眼成績、突破許多瓶頸,中研院團隊的目光,並不止於此。因為,YOLOv7的成功,證實YOLOR單一模型執行多任務的可行性,王建堯甚至直言,YOLOv7和YOLOR就是為多模態、多任務的統一模型鋪路。這句話揭示團隊接下來的研究方向,他們將以YOLOR為基礎,發展更通用的電腦視覺模型,物件追蹤就是其一。
與此同時,廖弘源透露,團隊也瞄準知識圖譜和圖神經網路(GNN)兩種技術,一方面要用擅長處理關聯性的圖學,來提高模型處理多任務的能力,一方面也要透過知識圖譜,來強化模型的可解釋性。
他解釋,一般類神經網路就像黑盒子,當網路出現問題時,開發者通常難以找出原因,但透過知識圖譜或GNN,可將原本的大黑盒子拆解為好幾個小黑盒子,更容易推導出問題所在。
從YOLOR統一網路和GNN雙管齊下發展多任務AI,就是廖弘源與王建堯眼中的下一個目標。
YOLOv7單一模型可執行3大任務

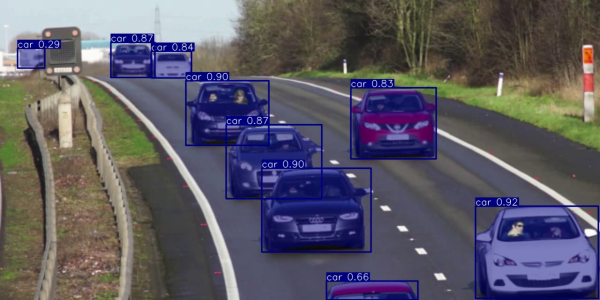
任務1:物件偵測 YOLOv7可執行3種任務,一種是物件偵測(Object detection),能將畫面中辨識到的物件,以邊界框(Bounding box)框出,並在框上顯示預測的物件名稱與機率。圖片來源/viso.ai
任務2:實例分割 YOLOv7可執行的任務還有實例分割(Instance segmentation),也就是將辨識到的物件著色,這個動作也稱為遮罩(Mask),比物件偵測只以邊界框框出物件還要細緻。圖片來源/Rizwan Munawar
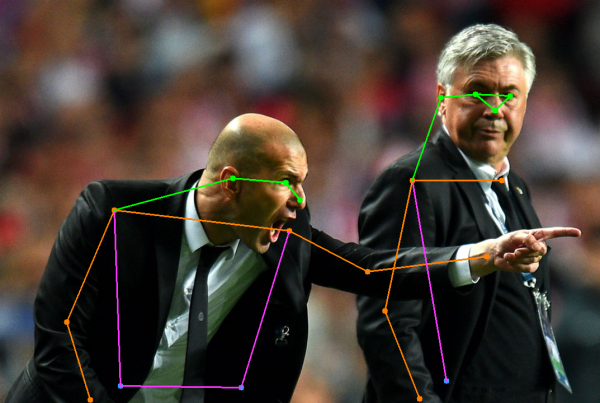
任務3:關節點偵測 YOLOv7可執行的另一種任務是關節點偵測(Keypoint estimation)。以人來說,模型可將畫面中辨識到的關節點標示並連線,就像個火柴人,可用來預測動作和姿態,如跌倒偵測。圖片來源/Aleskandr Snorkin
精簡的模型設計大力推進AIoT應用
物件偵測模型YOLOv7的成功,不只證實新技術可行,更能推動AIoT發展。YOLOv7共同開發者中研院資訊所所長廖弘源指出,YOLOv7模型速度快又準,架構還很精簡,只採用3x3卷積、1x1卷積和連結(Concatenation),因此耗電量低,只有約30瓦,非常適合部署在運算資源有限的邊緣裝置上,來發展AIoT應用。他認為,從AI模型下手改良,使用者不必受限於晶片設計,等於企業不必客製化或採用小奈米晶片來執行特定AI模型,用低成本的硬體設備也能享有高準確度的模型效果。
YOLOv7核心開發者中研院助研究員王建堯進一步解釋,YOLOv7因為架構精簡,採用非常少的運算單元,因此可直接在硬體上取樣,不需額外的運算單元。而越少運算單元,就能使用更簡單的架構來設計晶片;因為,晶片8、9成的電路面積,都屬於控制單元,這些控制單元專門連接所有運算單元,讓這些運算單元能互相溝通,所以,只要運算單元越簡單,控制電路也就越簡單,晶片設計也就越單純。再加上,模型使用運算密度高的3x3卷積,能進一步減少硬體運算資源。
這說明,低階設備採用高準確度模型的門檻降低了,一般邊緣裝置更容易部署物件偵測模型,也更容易推廣到各種應用場景,比如疫情時的社交距離偵測、零售商場人流偵測、路況偵測、基礎設施損壞偵測等。這也意味著,設計精簡的AI模型,能更容易將AIoT更普及到生活中。

熱門新聞

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-23

2026-02-23