")
Nvidia執行長黃仁勳親手將第一臺DGX超級電腦提供給OpenAI,變成了大型語言模型技術突破背後的引擎。現在Nvidia要進一步推出DGX Cloud,將AI超級電腦變成雲端服務。(圖片來源/Nvidia)
「生成式AI不只展現強大能力,更讓企業產生重新思考產品和商業模式的急迫感,」Nvidia執行長黃仁勳在今年GTC大會開場演講時這樣強調,不分產業,企業都紛紛加快數位轉型,要變成軟體驅動的科技公司,「企業想要成為推動變革的一方,而不是被變革淘汰的另一方。」
黃仁勳講這一席話的時候,新一代GPT-4正式發表剛滿一周,全世界再一次感受到生成式AI的新威力,Nvidia趁勢發表了全新的雲端營運模式。
ChatGPT從去年底爆紅後,迅速累積破億人註冊使用。今年3月1日,OpenAI正式推出ChatGPT付費API後,這股浪潮更從個人使用,迅速蔓延到企業應用場域,各種ChatGPT相關應用紛紛出爐,兩大科技巨頭也大秀AI軍火。微軟展示了用GPT-4打造的下一代Office,從文書處理、試算表到簡報都能輔助,全新AI助手Microsoft 365 Copilot讓人驚艷。追趕的Google則祭出5,400億參數訓練的PaLM模型迎戰,同樣展示了下一代WorkSpace將如何結合生成式AI,以及可以自動生成App程式的Generative AI App Builder工具。微軟不甘示弱,祭出全新GitHub Copilot X反擊,將GPT-4更深度整合到IDE開發工具中,成為開發人員的萬能AI助手,從自動寫程式、除錯到優化配置樣樣都行。
光是在3月,科技巨頭的AI競爭,就像拳擊場上你來我往的肉搏對打,讓企業主感受到一股非了解不可的焦慮感。尤其更強大、正確性更高、還能支援圖文輸入的GPT-4正式登場,讓企業主這股焦慮感更是火上添油。
調查160萬人,竟有3.1%員工上傳機敏資料到ChatGPT
但是,企業要使用ChatGPT或是GPT-4,並非是件馬上就能決定的事,需要考量的細節,遠遠和個人使用截然不同,尤其企業格外會擔心內部機敏資料的外洩風險。
根據國外一家提供企業級資料偵測與應變(DDR,Data Detection and Response )的新創Cyberhaven,在2月底到3月初時調查旗下企業用戶,統計超過了160萬名員工的資料上網情形,高達8.2%的員工會用ChatGPT,其中竟有3.1%的員工將企業機敏資料輸入到ChatGPT上。在調查那一周內,平均每10萬名員工,就出現199次機密文件上傳警告通報,以及173起顧客資料上傳警告通報。
最近一起引起眾人關注的則是韓國經濟學人媒體披露的三星半導體ChatGPT資料外洩事件,在開放半導體廠使用ChatGPT不到20天,就發生了3起機敏資料外洩事件,兩起是開發人員將設備量測與良率檢測特定用途的完整程式碼,輸入到ChatGPT上來尋求除錯,另一起則是助理將重要會議內容輸入ChatGPT來產生摘要。三星半導體緊急限縮ChatGPT的使用,並打算發展自製的GPT模型來替代。不過,早在三星發生資料外洩事件之前,就有很多企業都意識到自行訓練生成式AI模型的重要性,三星機敏資料外洩事件只是再次證實了這個考量的必要性。
看準模型客製化需求,將AI超級電腦產品線變成雲端服務
Nvidia正是看準了這一波ChatGPT爆紅背後的客製化AI模型訓練需求,宣布了全新的商業模式,不只是以硬體晶片生產和軟體技術提供為主的科技產品製造商,更進一步自己跳下來變成雲端服務供應商,要把自家AI超級電腦產品線,變成了雲端的AI超級電腦雲服務。
黃仁勳以「人工智慧的iPhone時刻」來形容這股ChatGPT帶動的生成式AI浪潮,以及可能帶來的重大變革,而新推出的雲端AI超級電腦服務,就是Nvidia因應這股變革的關鍵戰略。「要透過瀏覽器將Nvidia AI帶給每一家企業。」他強調。
DGX是Nvidia的AI超級電腦產品線,黃仁勳透露,他親手將第一臺DGX超級電腦提供給OpenAI,變成了大型語言模型技術突破背後的引擎。DGX最初的用途是為了AI研究,但現在已經進入了企業營運領域,需要支援全天候的運作,甚至,得有能力擴充到數十萬節點的龐大規模。至今,超過半數財富100大企業導入了這套要價不菲的設備。
早在去年GTC大會上,Nvidia就先發表了第四代DGX H100超級電腦,採用了以COBAL發明人Grace Hopper 命名的Hopper架構,以及用這個架構打造的H100 GPU。這款AI超級電腦也在2023年初正式出貨。
在第四代DGX超級電腦,搭載了8個H100模組,而H100 GPU還搭載了一個前一代A100 GPU所沒有的新加速引擎Transformer Engine,這是一個專門為NPL知名Transformer模型所打造的加速引擎,可以用來加速BERT、GPT-3模型的訓練。
Nvidia透露,和前一代A100相比,H100在神經網路運算上,可以達到6倍的速度,也能兼顧精準度。甚至可以利用16位元精度與H100新增的8位元浮點資料格式(FP8),結合進階軟體演算法,還能進一步提高AI訓練速度,在同一款大型語言模型上,H100速度提升可以達到A100的9倍之多,推論速度甚至是前一代GPU的30倍。
另外,H100也採用了第二代MIG技術,更容易支援雲端多租戶服務的組態方式,可以同時承載7個更小且隔離的實例,而A100只能承載1個。換句話說,H100是更適合發展成雲端服務型態的GPU。另外,Hopper新架構也開始能支援GPU機密運算,可以用來保護用戶AI模型、演算法機密性和完整性,因此,採用此架構的H100,可以讓企業在第三方業者提供的雲端基礎架構環境中,更安心散布和部署自家的AI模型。
過去,多家公雲巨頭原本就推出採用A100的雲端VM服務,也紛紛宣布將跟進推出搭載新款H100 GPU的VM服務。例如甲骨文OCI率先推出搭載8顆H100 GPU的VM,甚至最大可以擴充到16,384個H100 GPU的超大規模叢集。AWS則宣布推出可以擴充到2萬個互連的H100 GPU的P5執行個體,Azure則是先推出H100 v5預覽版,Google Cloud後續也會推出。各大伺服器製造商也開始提供搭載H100 GPU的伺服器和系統。
不只是出租AI超級電腦硬體,更有整套基礎架構軟體
不過,今年Nvidia更進一步,不只是賣超級電腦硬體給公雲業者,還自己下海,變成了雲端服務供應商,黃仁勳宣布要推出AI超級電腦雲服務DGX Cloud,可以提供按月租用的超級電腦叢集,而且可以提供到H100等級的GPU。
目前Nvidia將與三家公雲業者合作,在微軟Azure、Google Cloud和甲骨文OCI上提供DGX Cloud託管服務。將先在OCI上推出,最大可以提供到超過32,000個GPU的超級電腦叢集服務,Azure預計今年第二季推出,Google Cloud則在今年更晚時上線。
DGX Cloud不只是提供超級電腦硬體出租,而是包含了一整套的超級電腦基礎架構,從最底層提供了高效能的儲存空間(單實例有10TB容量,每月輸出流量10TB),再上一層則是可以提供單一執行個體內建8個H100或A100 80GB Tensor核心GPU,每個節點共有640GB的GPU記憶體。
這兩層是硬體體層基礎架構,再往上是超級電腦的基礎架構軟體層,包括了用於調度基礎架構軟體的Nvidia Base Command管理軟體,以及開發人員管理AI應用開發流程的Base Command Platform雲端SaaS服務,再加上最上一層的AI Enterprise軟體套件(包括了AI和資料科學工具和常用AI框架等)。
從技術架構圖來看,雲端業者負責雲端服務的支援,而Nvidia則提供了AI技術客服窗口和AI專家的技術支援服務。
這座超級電腦雲採取按月訂閱制,月租費是每個執行個體最低36,999美元起跳(約臺幣113萬元),遠低於一臺DGX A100在2020年中剛推出時的買斷報價19.9萬美元(約臺幣600萬元)。
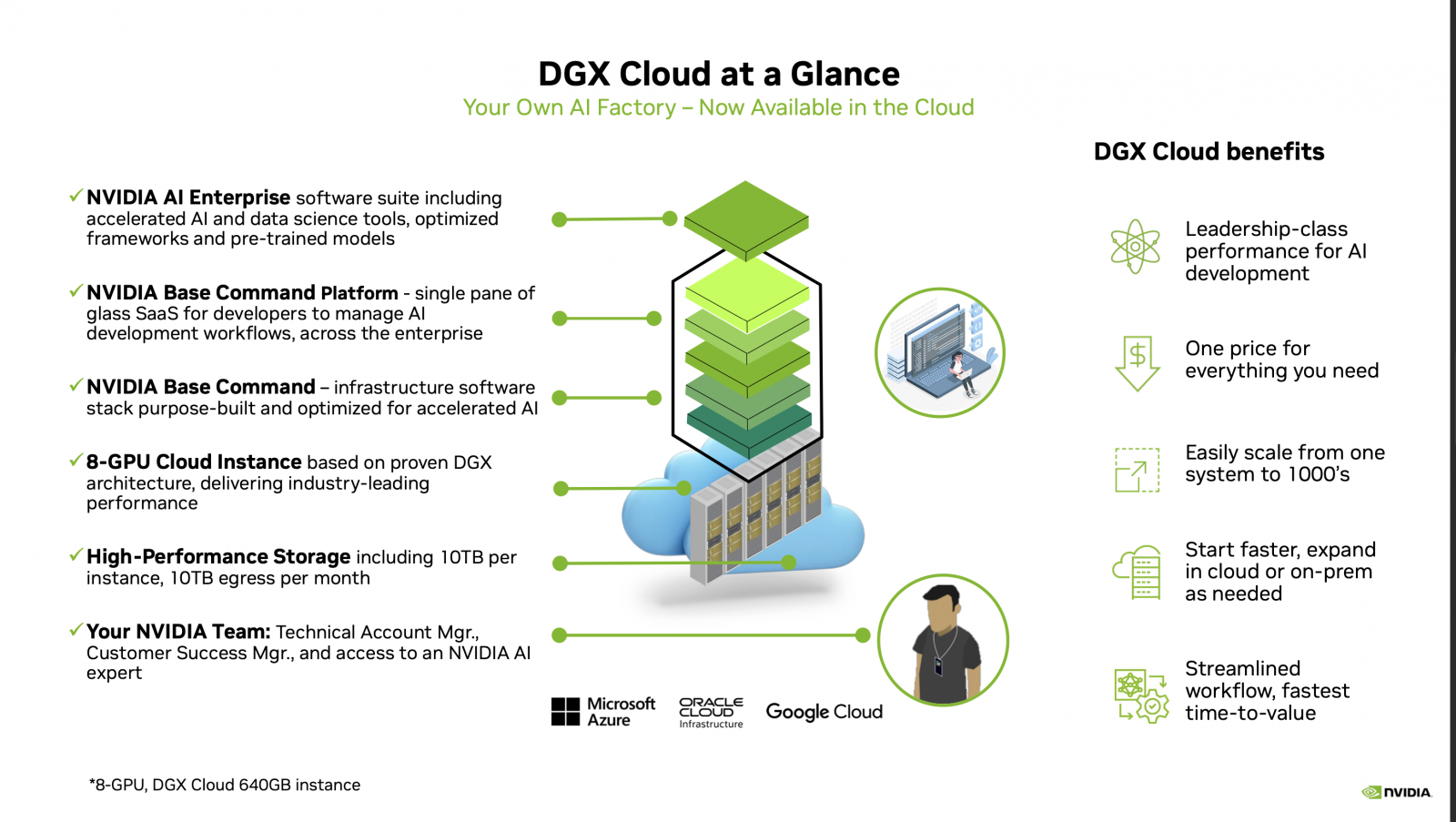
DGX Cloud包含了整套超級電腦基礎架構,最底層是高效能儲存,再上一層是H100或A100硬體VM,再往上是超級電腦的基礎架構軟體層,包括了運算資源調度的Nvidia Base Command管理軟體、管理AI應用和開發流程的Base Command Platform雲端SaaS服務,以及AI Enterprise軟體套件。雲端業者負責雲端服務支援,而Nvidia則提供了AI技術客服窗口和AI專家支援。圖片來源/Nvidia
重頭訓練1,750億參數的GPT-3模型要多少億?
根據Nvidia測試,過去要用一個3,000億個Token的公開網路資料集,來訓練出1,750參數的GPT-3模型,若採用1,024張A100 GPU,還是要花上24天。換句話說,企業若要想在一個月內訓練出參數量和ChatGPT相當的自有GPT-3模型,得採購128臺DGX A100超級電腦(單臺8個GPU),光硬體費用就超過7.68億元,就算願意等上一年訓練一次,也至少要投資5千多萬元採購9套。若換成按月租用的超級電腦服務,以月租費113萬元X128個超級電腦VM,則約臺幣1.4億元。雖然遠比7.6億元低得多,但仍是一筆巨額投資,甚至遠遠超過許多臺灣2千大規模企業一整年度的IT投資規模。只有少數大型高科技製造業或金控,才負擔得起自己從頭訓練出一套GPT-3模型的硬體費用,這還不包括人事費、軟體和資料集蒐集費用。生成式AI帶來的創新競爭,無疑是一項龐大財力的競賽。
提供更低成本的預訓練模型服務,不用重頭訓練超大模型
所以,為了搶攻全球企業瘋ChatGPT的浪潮,Nvidia還鎖定了那一群沒有足夠資源從頭訓練,但又想要打造專屬客製化模型的企業,推出了一套AI超級電腦軟體服務AI Foundations,提供預訓練的GPT-3模型,讓租用企業不用重新訓練,而是進行微調優化就可以打造出使用,可以讓企業用自己的資料,快速訓練出專屬的生成式模型,如此一來,不只可以大幅降低所需的運算量,訓練用資料集也不用準備到3,000億個Token之多,更能大幅縮短訓練時間。這正是Nvidia用來瞄準企業自建專屬生成式AI模型的殺手級服務,也能發揮按月租用模式的特性,用更低成本來打造出企業專屬的GPT-3模型。
3種生成式模型服務,瞄準文字、影音和藥物開發3大類需求
在這套AI Foundations服務中,提供了三種生成式模型,包括了文字NLP生成模型服務NeMo,圖像生成模型服務Picasso,以及可以生成藥物分子結構的藥物生成模型BioNeMo服務。
NeMo就是可以用來訓練出專屬GPT-3的模型服務,類似微軟Auzre的OpenAI API服務,可以讓企業訓練自己專屬的GPT-3模型。
目前NeMo可以提供80億參數、430億參數和5,300億參數三種GPT-3預訓練模型,企業不用從頭開始訓練,而是可以直接使用這些預訓練模型來進行微(finetune)就可以客製化。NeMo還提供了一個Inform模型服務,內建向量資料庫,可供企業上傳自家企業資料轉換成嵌入向量儲存到Inform模型服務上,來限制客製化GPT-3模型推論的輸出,盡量侷限在企業提供的資料範圍內。
不只是預訓練模型,NeMo還提供了兩種微調功能,一種是P-Tuning提示微調功能,透過模型訓練來優化提示問題,改用一個提示工程的嵌入向量(Prompt Vector)來取代提示問題,來提高提示工程的效果,提高GPT-3的準確度,另外,NeMo也支援真人回饋的強化學習優化提示工程做法,透過真人標記來設計獎勵模型,讓模型回答出更接近企業想要的答案。這個強化學習做法,也是借鏡了OpenAI用真人強化學習來打造出ChatGPT效果的做法。
如同Azure OpenAI的GPT模型服務的推論內容過濾機制,Nvidia也在Nemo服務設計了內容護欄服務(Guardrail Service),企業可以監控每一次模型推論的輸出內容,檢查不適當的內容,也能設定偏差閥值或是指定領域來控管內容,避免模型意外輸出了不適合提供的內容。Picasso則是視覺的大型語言模型服務,可以透過簡單的文字或影像提示,來產生自訂的影像內容,還能生成影片,甚至是用於生成3D素材。而BioNeMo服務則可設計用來探索疾病成因的生物學小分子、蛋白質或抗體新分子結構,也能用來作為分子相互作用的最後篩選參考之用。
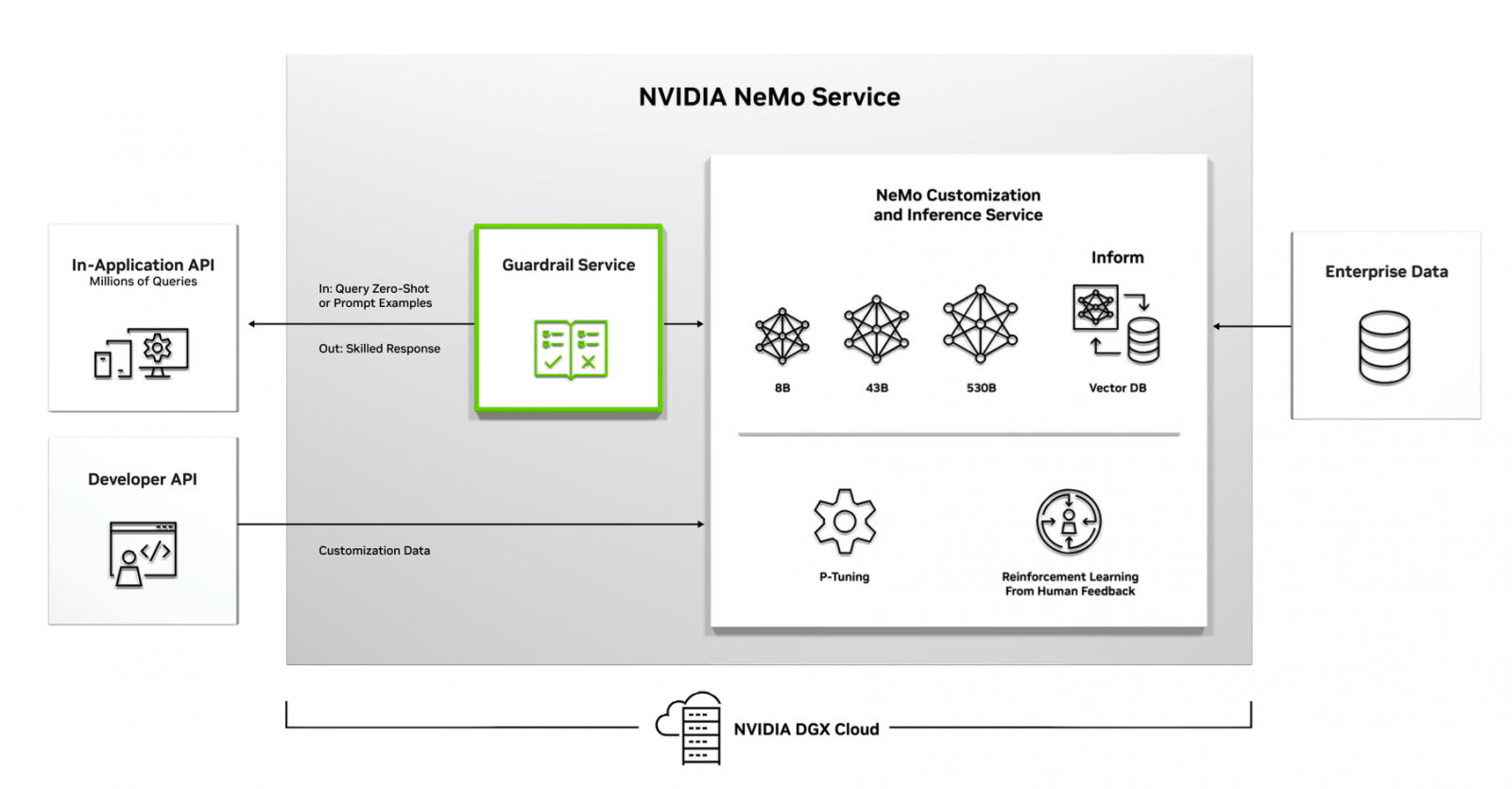
Nvidia在AI Foundations服務中,提供了文字NLP生成模型服務NeMo,可以提供80億參數、430億參數和5,300億參數三種GPT-3預訓練模型,企業不用從頭開始訓練,而是可以直接使用這些預訓練模型來進行微調。圖片來源/Nvidia
DGX Cloud就是雲端AI工廠
Nvidia不單是出租超級電腦硬體,還將原本搭配DGX超級電腦的軟體產品,不論是Base Command管理軟體,或是可用於開發和部署AI應用的Ai Enterprise軟體,轉為變成在雲端提供的託管服務,而且可以支援混合雲架構,企業也可以和本地端DGX超級電腦混用。
黃仁勳如此形容這個超級電腦雲服務的特性,DGX Cloud就像是一間在雲端的AI工廠一樣。 而AI Foundations服務就像是工廠中的鑄造廠,可以快速鑄造出一個又一個客製化的專屬生成式模型,這正是Nvidia搶攻龐大ChatGPT浪潮下的AI新戰略。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09

2026-02-06


2026-02-09

2026-02-09