或環境的狀態下,效能表現高出上一代RT-1模型近2倍。(圖片來源/Google)")
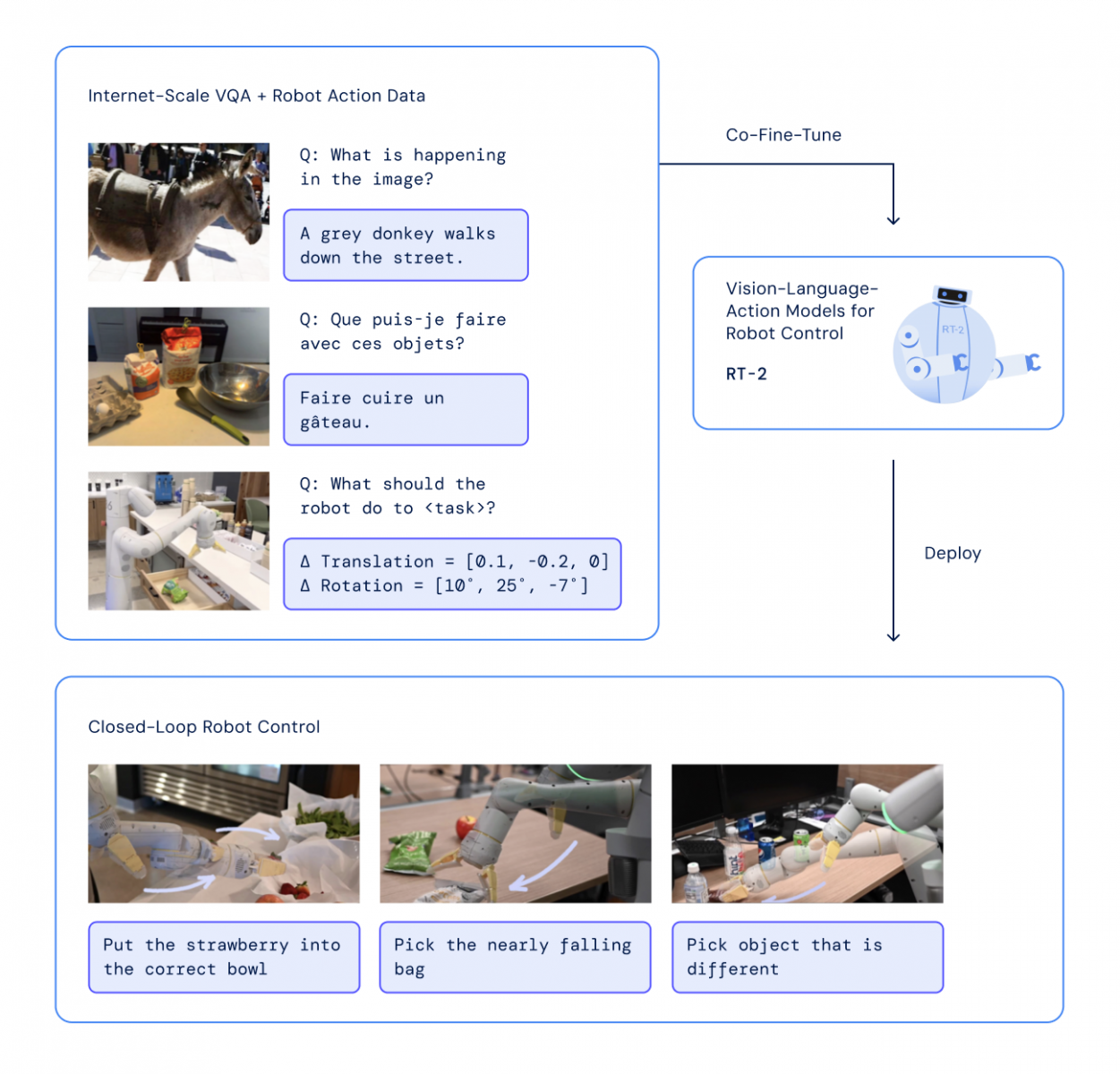
Google DeepMind強調新一代機器人模型RT-2透過大量來自網路的文字與影像來學習真實世界,再輔以機器人訓練資料,不僅能理解複雜的推理,還能直接輸出動作,在那些機器人未曾見過的背景、物件(如上圖的番茄醬等三種醬料瓶)或環境的狀態下,效能表現高出上一代RT-1模型近2倍。(圖片來源/Google)
Google在上周五(7/28)發表了新一代的AI機器人模型Robotic Transformer 2(RT-2),它以來自網路的文字與圖像(visual-language model,VLM) 進行訓練,再結合上一代Robotic Transformer 1(RT-1)機器人的訓練資料,成為全球第一個視覺-語言-行動(vision-language-action,VLA)模型,讓機器人更能理解與執行人類所要求的任務。
Google在去年12月發表的RT-1模型主要是仰賴於實體世界操作的機器人資料進行訓練,所蒐集的資料是13個機器人在17個月之間,於13萬個場景中所執行的逾700種任務。
而RT-2最大的改變就是引進了VLM,讓機器人模型得以透過大量來自網路的文字與影像來學習真實世界,再輔以上述的機器人訓練資料來執行各種行動。
圖片來源_Google
Google DeepMind負責機器人的科學家Vincent Vanhoucke表示,過去的機器人都是一個口號一個動作,想像人們想執行一件事時,必須拆解每一個動作並指使身體移動,但RT-2不僅能理解複雜的推理,還能直接輸出動作,只要輸入少量的機器人訓練資料,系統就能把蘊藏於語言與視覺訓練資料中的概念,轉成直接的機器人行動,包括未曾接受過訓練的任務。
舉例來說,過去若想要機器人系統丟棄某個垃圾,那麼必須先明確地訓練機器人辨識垃圾,再訓練它們撿起垃圾,以及將垃圾丟棄,但被餵入大量網路資料的RT-2,已經知道什麼是垃圾,而且就算未經特別訓練也知道該如何把垃圾丟掉,例如RT-2可以辨識香蕉皮與吃光的零食袋是垃圾。
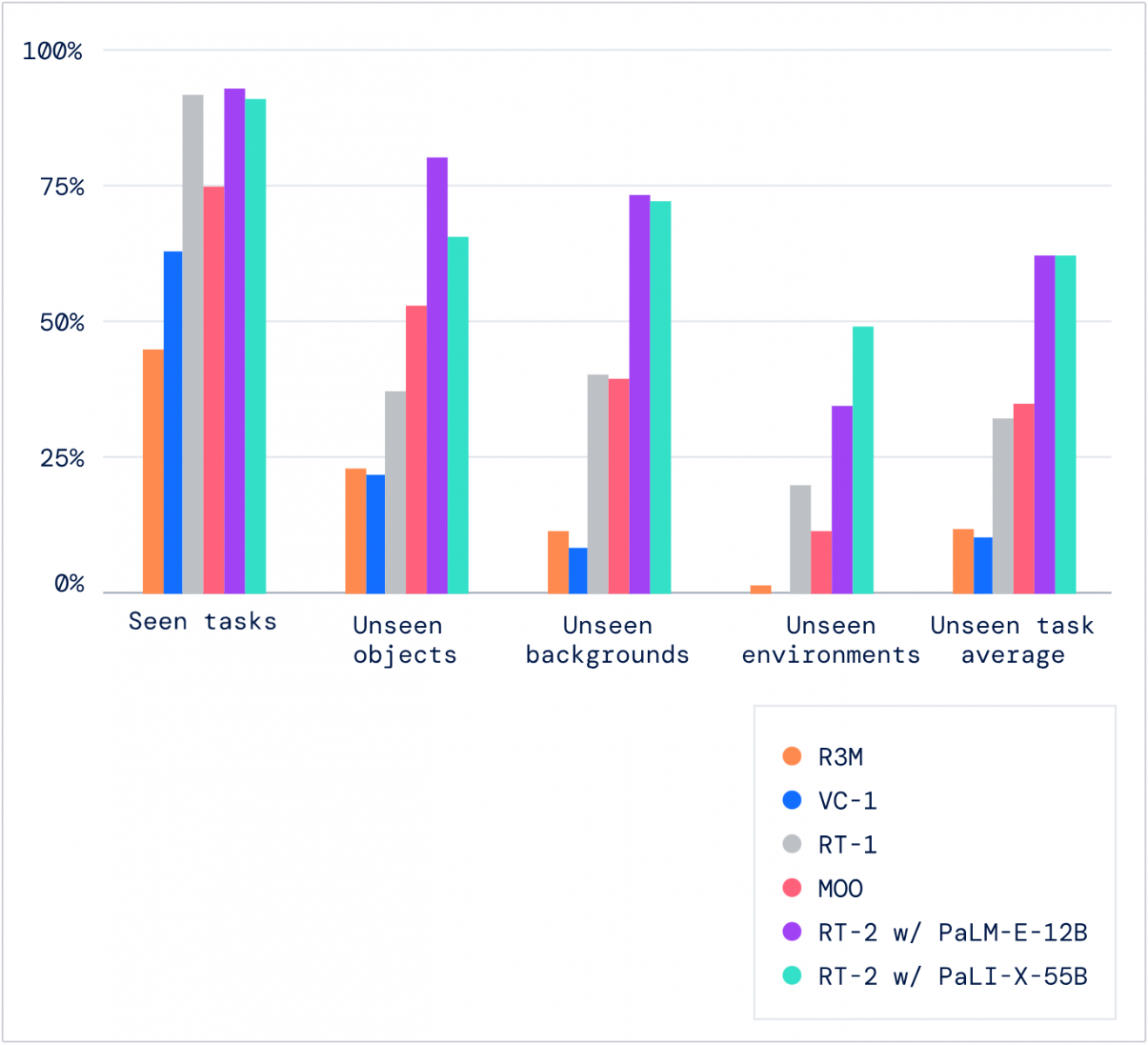
Google DeepMind比較了RT-2與自家的RT-1、Reusable Representations for Robotic Manipulation(R3M),以及來自Meta的Manipulation of Open-World Objects(MOO)在曾訓練與不曾訓練上的任務表現,顯示RT-2與RT-1於前者的表現相當,成功率都有90%左右,而在那些機器人未曾見過的背景、物件或環境的狀態下,RT-2具備明顯的優勢,效能達62%,遠高於RT-1的32%。至於Meta的MOO在已知場景的效能則有75%,未知則略高於RT-1。
圖片來源_Google
熱門新聞

2026-02-11

2026-02-09
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10