,再將這個查詢發送到檢索系統,最後得出了參考結果。1990年代的AltaVista搜尋引擎就是如此,現在的Google搜尋亦是如此。")
Google DeepMind傑出研究科學家Marc Najork表示,過去70年來,檢索系統始終遵循相同典範,都是先將資訊需求轉換為一個查詢句子(Query),再將這個查詢發送到檢索系統,最後得出了參考結果。1990年代的AltaVista搜尋引擎就是如此,現在的Google搜尋亦是如此。
生成式AI不只衝擊各產業,也激起傳統技術變革,包括我們常用但陌生的資訊檢索(Information retrieval,簡稱IR)領域。
每天,我們用瀏覽器搜尋資料,在網購App上挖寶,上圖書館和學術期刊網站找文獻,或是企業存取資料庫、行銷個人化推薦、銷售排名評比等,這些搜尋動作背後的關鍵技術,就是資訊檢索,更是各種排序、推薦不可或缺的核心技術。
網路搜尋核心技術:發展70年的IR
IR並不新奇,是個「發展70年的成熟領域,」Google DeepMind傑出研究科學家Marc Najork日前來臺時說道。他專攻IR、網路搜尋和排名數十年,曾在微軟研究院研發個人化社群搜尋(Social search),也在Google研究院帶領近70人團隊、打造各種IR應用,現在專心聚焦生成式AI。放下了所屬公司的身分,他從個人學術研究的角度,更全面地剖析IR這個老技術領域的最新進展。
他解釋,二戰後,大量文件開始解禁,圖書管理員開始運用電腦程式,協助研究人員查找所需的龐大文獻和書本。電腦科學家Herbert F. Mitchell在1953年發表一篇論文,說明通用圖書文獻查找系統的運作方法,是早期IR系統的典型樣貌。
此後70年,檢索系統始終遵循相同典範,都是先將資訊需求轉換為一個查詢句子(Query),再將這個查詢發送到檢索系統,最後得出了參考結果。這些結果可能按相關性遞減排序,也可能包含簡短摘要。這種查詢典範,到了際網路興起時繼續沿用,成為大家熟悉的搜尋模式:輸入關鍵字、按下Enter鍵,搜尋服務給出10幾條藍色字體連結。1990年代的AltaVista搜尋引擎就是如此,現在的Google搜尋亦是如此。
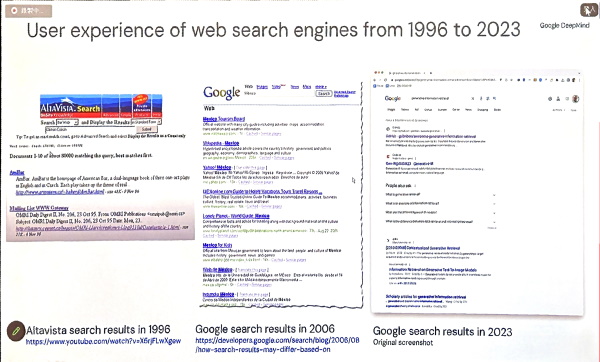
Google DeepMind傑出研究科學家Marc Najork指出,70年來的資料檢索(IR)系統一直維持同樣的典範,先將資訊需求轉換成查詢句子,再將這個句子送到檢索系統,再回傳可供參考的結果。這些結果可能按相關性遞減排序,也可能包含簡短摘要。網路興起時,搜尋引擎繼續沿用這個資訊檢索典範,發展成大家熟悉的搜尋模式:輸入關鍵字、按下Enter鍵,搜尋服務給出10幾條藍色連結。1996年的AltaVista搜尋引擎就是如此,現在的Google搜尋亦是如此。攝影/王若樸
搜尋資訊的難度一直是IR痛點
在IR圈,降低搜尋難度一直是專家們想克服的痛點。
Marc Najork引用Google一篇網路搜尋研究,搜尋資訊的代價,其實要付出不少非金錢的成本,如時間成本、認知成本和互動成本,在學術研究上,將這些成本統稱為Delphic Costs。回顧檢索系統70年來的發展,「所有技術改良都是為了降低Delphic Costs。」
他舉例,同義字擴展(Synonym expansion)可以降低如何構思查詢的認知成本,排名(Ranking)作法則有助於降低人眼瀏覽一條條搜尋結果的時間成本,資訊摘要也能減少時間成本,讓使用者可直接跳過排名靠前但不相關的搜尋結果。
這些例子也不乏里程碑等級的技術,像是以單字為索引基礎的Uniterm系統,可快速查找主題關鍵字內容、提高相關性排名,又或是能加速全文搜尋的反向索引(Inverted index),不僅容易更新、擴充,還具備同義字擴展和更有效率的布林條件搜尋。它們的出現,都是要降低搜尋難度。
但要是搜尋資訊時,系統不是跳出一條條參考結果,而是以問答形式,直接給出整理過、圖文並茂的摘要和參考資訊,是否更能降低Delphic Costs?
NLP技術突破,為生成式AI用於資訊檢索鋪路
答案是肯定的。Marc Najork說明,這種問答式系統,降低了搜尋時間和心力成本,而且「比檢索系統更直接!」即便這種系統有其風險,也未嘗不是個新解方。
不只他,IR界許多專家也看好這種直接問答式系統的潛力。這是因為,早幾年自然語言處理(NLP)的技術突破,奠定了問答系統用於資訊檢索的基礎。
比如2013年,詞嵌入(Word embedding)技術有了重大進展。Google發布word2vec詞嵌入工具,將文本處理簡化為數學向量問題,能學習大量上下文,把每個字轉換為向量,並計算字與字在向量空間中的距離,來判斷這些字的語義相似度。
這個工具,大幅提高多種NLP任務表現,如翻譯、文本分類、情感分析以及資訊檢索。word2vec演算法的出現,還催生更多類似工具,像是史丹佛大學的GloVe、Meta的fastText等演算法,更進一步優化IR。
這個詞嵌入技術,後來還延伸為文件嵌入(Document embedding)技術,等於不同長度的句子、段落甚至是整個文件,都能一一對應到固定長度的向量,透過計算空間中向量的距離,來判斷文件相似度。其中的代表工具為2014年發布的Doc2vec,能用來解決文本分類、情感分析、資訊檢索和推薦等任務。
語言模型興起,不只儲存語言還儲備基礎知識
不過,這種文件嵌入模型表現越好,訓練成本也就越高。於是,專家開始把目光轉向預訓練語言模型,用大量資料訓練一個模型、先學習幾個關鍵任務,之後再根據需求微調。這種預訓練模型方法,比建置單一任務模型還要划算。
於是,2018年,NLP界迎來另一項技術突破——BERT,一個能處理雙向序列的預訓練語言模型,採Transformer架構,不僅準確率更高,還比過往方法(如LSTM)更有效擴展,成為許多任務的SOTA標竿,就連資訊檢索常用的排名,也是BERT的擅長項目。BERT的出現,催生出更多類似模型,如GPT系列模型、PaLM等,開啟生成式語言模型時代。
至此,NLP的技術進展大大改變傳統IR效能。詞嵌入、文件嵌入再到BERT這類模型擁有更好的語義判斷能力,不只大幅提高搜尋結果相關性、給出更符合需求的答案,就連推薦、排名也一併改善。
就在這類模型百花齊放的同時,專家們也觀察到,「模型本身不只儲存語言,還儲備基本知識。」對Marc Najork來說,這是一個很重要的轉捩點,有位Google研究人員將自家預訓練模型T5當作一個知識庫,也就是不對外查詢資料、只使用模型已知知識,來作為封閉式問答系統,並以不同的問答任務,來比較T5與其他開放式問答系統的表現。
雖然,「T5最終表現沒有開放式問答系統好,但也不差!」他表示,正是那篇研究,讓他開始相信,生成式模型能直接用來回答問題。
這個研究發現,也是Marc Najork開始投入生成式IR研究的起點。
生成式AI終於走進IR
於是,2年半前,Marc Najork與團隊開始鑽研生成式模型在IR的應用。他們先是在頂級資訊檢索學術盛會ACM SIGIR 2021上,發表一篇重思搜尋的論文,提出將生成式模型用於資訊檢索的可能。
簡單來說,他們把傳統IR系統比擬為圖書管理員,這些系統不會直接給你答案,而是給出多個參考來源,你要的答案可能就在其中。而生成式模型能針對問題,直接給出答案,這些答案可來自語言模型本身,也可來自外部工具。
他們還定義,理想的生成式問答系統應具備5大要點,包括生成式模型得根據權威來源產生答案,以確保「可靠性」;模型產出答案後,要附上引用來源,來保障「透明度」,並避免撈取偏見資料,來實現「無偏見」。對於爭議性問題,模型要公平提供各觀點的答案,以達到「多樣性」,而且,模型還要用淺顯易懂的話語來與使用者溝通,並具備多語言能力,用使用者的語言對話,以確保「可用性」。
這些論述,勾勒出生成式IR的大致輪廓。即便生成式模型仍有成本高、產生幻覺等缺點,但有不少專家認為,這種問答系統有機會實現IR的最終目標。
生成式IR好處:導流和旅程體驗
現在,隨著新一波生成式模型一一出現,特別是ChatGPT的問世,進一步把生成式IR推向大眾,成為科技巨頭爭相押寶的對象。不論是在今年Google I/O大會,還是微軟全球Build年會上,兩大巨頭都發表了如何運用生成式AI技術,來優化資料搜尋的新體驗。
比如,你喜歡慢跑,想在夏季結束前養成長跑10公里的能力,但不知道怎麼規畫。於是,你在瀏覽器輸入一句「幫我制定在夏末前養成10公里長跑能力的訓練計畫」,下一秒,瀏覽器就直接給出計畫摘要,告訴你每周的訓練內容、相應訓練影片和參考來源,不需你手動一一尋找。這就是未來會普及的生成式IR用例。
這種生成式IR應用,不僅能降低使用者的搜尋成本,還能提供品質更好的導流與旅程體驗。例如可以根據使用者需求,給出精準的摘要資訊和推薦,因此,摘要小卡提供的參考來源,會比原本使用者一一手動查詢搜尋結果的體驗要好,也就是說,生成式AI優化後的搜尋,更容易幫助使用者找到想要的資料,對搜尋目標網站的導流效果更好。
特別是,生成式IR還能提供更好的決策制定體驗,比如透過2件商品的比較摘要等方式,來提供消費者更深度的購物旅程。

熱門新聞

2026-02-11

2026-02-09

2026-02-10
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-06

2026-02-10

2026-02-10

2026-02-10