
圖片來源/Netfllix
影音串流龍頭Netflix在去年12月,突然發布了一份史無前例的收視資料,吸引了全球影視產業的目光。16年來的第一次,Netflix公布了全球2.4億用戶的收看大數據。
從這份收視報告,可以看到幾個驚人的數據,Netflix在去年1月到6月期間播放的影片,高達1萬8千4百部多影片,包括了系列影集和單部的電影,統計時間從總收看時數,超過了1,000億小時,平均每個用戶在半年內看了420小時,平均一天2.3小時。
每一部影片的收看時數都超過了5萬小時,其中99%的影片,也就是有18,214部的播放時數都超過了10萬小時。
第一名「 暗夜情報員」第一季累計達到8.12億小時。臺劇第一名則是4,560萬小時的「模仿犯」,全球排名341。不只當時新上檔的劇集,連2021年播放的「華燈初上」,過了2年,播放時數仍超過150萬小時。甚至有一部12年前上映的老電視劇集「 無照律師」,在2023年重新上架到Netflix後,半年創下了1.29億小時觀看時間名列全球第73。
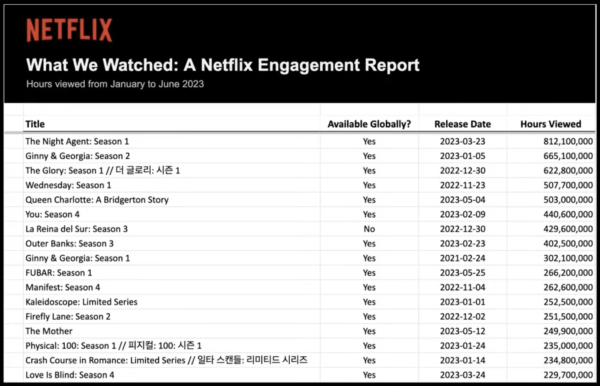
16年來的第一次,Netflix公布了全球2.4億用戶的收看大數據。高達1萬8千4百部多影片,去年1月到6月期間的總收看時數超過了1,000億小時,平均每個用戶在半年內看了420小時,平均一天2.3小時。99%的影片,播放時數都超過了10萬小時。第一名「暗夜情報員」第一季更累計達8.12億小時。
臺劇第一名則是4,560萬小時的「模仿犯」,全球排名341。不只當時新上檔的劇集,連2021年播放的「華燈初上」,過了2年,播放時數仍超過150萬小時。甚至有一部12年前上映的老電視劇集「 無照律師」,在2023年重新上架到Netflix後,半年創下了1.29億小時觀看時間,名列全球第73。圖片來源/Netfllix
首度公布全球收視大數據後,揭露背後資料工程技術架構
就在這份收視報告公布後2天,Netflix也舉辦了第一次資料工程大會(Netflix Data Engineering Summit 2023),首度公開了他們用來搜集影音大數據背後的資料工程技術架構。
Netflix為了支援全球影音串流,有一套龐大的資料工程基礎架構,為了追蹤上萬部影片的播放成效,Netflix設了一個內容資料工程團隊,專門負責將上千億串流時數的數據,轉換成各種分析洞察,讓Netflix可以決定怎麼推播影片給全球用戶。數億用戶透過數千種不同類型裝置上的Netflix軟體來收看這些影片,產生的事件資訊多達百萬種,Netflix設了一個綜合追蹤團隊(Consolidated Logging Team)專門搜集各種Netflix消費者產品和內部應用的事件資訊,將這些資訊彙整成容易理解的合理形式,來支援各種個人化應用和分析的需求。
早在2007年,Netflix在美國推出線上影片串流服務後不久,就開始打造自己的資料倉儲系統,從那時就陸續自行研發出許多資料技術和工具,來支持各種資料工程實務上的需求。
Netflix內容資料工程團隊資料工程師Chris Stephens在Netflix待了9年,參與了內容績效評估,觀眾理解分析、程式化發展戰略等領域的發展。回顧過去近10年的資料工程發展,他指出,Netflix資料工程技術架構的核心原則是,要讓常見需求更容易進行,而且可以兼顧到不同層級的客製化需求,但是,也因為這些高度客製化的需求,「Netflix有許多工具都得從無到有自己打造。」
Netflix批次處理流程的四大關鍵步驟
這個資料工程技術架構中最典型的兩大資料流程是,批次處理和串流處理,這也是企業常見的兩種資料流程。Netflix的批次處理流程中,包括了四個步驟,第一步是資料轉換和邏輯彙整(Transform & Agg Logic),Netflix的分析性資料倉儲中有數千個資料表,都是採用開源資料表格式Apache Iceberg的資料表,也儲存在雲端。Apache Iceberg是Netflix在2017年時,由2位工程師自己所開發的大數據技術,隔年開源釋出,捐給了Apache軟體基金會。
這些Iceberg資料表涵蓋了不同業務的需求,從影音串流資料,不同產品功能的互動及路,顧客服務,製片工作室日常運作,到行銷數據都有。
在Netflix,大多數批次處理都使用了Apache Spark大數據分析平臺,內部的資料工程師社群最常用的Spark綁定機制,包括了SQL、PySpark和Scala這三種,不同資料工程團多半偏好其中一種。但是,Netflix大數據分析平臺都會優先支援這三種綁定機制。
為了方便工程師設計各種不同需求的批次流程,Netflix自己設計了一個大數據資料入口網站的Query UI工具,這是他們的資料工程師最常用的工具。這個工具可以檢測所要查詢的資料表,也能找到這些資料表的相關紀錄。查詢輸入列也具備了自動完成機制,各種函數指令甚至是複雜的巢狀結構指令也能自動完成,工程師可以從這個單一入口查詢所有資料引擎,包括了Spark、Trino、 Druid、Snowflake上的資料。
另一個資料工程師常用的工具是叢集權重調整工具go/Boost,因為常有人來要求他們,能不能提高各自分析任務的優先程度,資料工程師就會用這個工具暫時調高所用叢集的資源額度。
資料彙整後,接著得檢查輸入資料的資料品質,Netflix有一套成熟的資料品質生態圈工具,來避免發生垃圾資料產生垃圾分析的窘況,一方面讓資料工程師擔起更多的資料責任,另一方面也可以讓後續的資料使用者,放心使用資料倉儲的內容。
Netflix在資料品質控管上,使用了單元測試結合資料稽核,來確保資料的品質,盡可能提供資料集更大的保護,避免浪費資源和時間。
在單元測試工具上,Netflix會採用原生的單元測試函式庫,包括了ScalaTest和PyTest,來測試使用者定義的功能。若是Spark的Data Frame API上的功能測試,則用了一套Netflix自己開發的Spark單元測試函式庫,還有一款資料流程工具,可以快速從資料倉儲拉出資料表,以便盡快重跑資料測試。
除了單元測試,另一個把關品質的重要手段是稽核。Netflix有許多稽核機制,每當資料來源出現異動時,這些稽核機制就會去檢查資料背後的各種上下文脈絡。
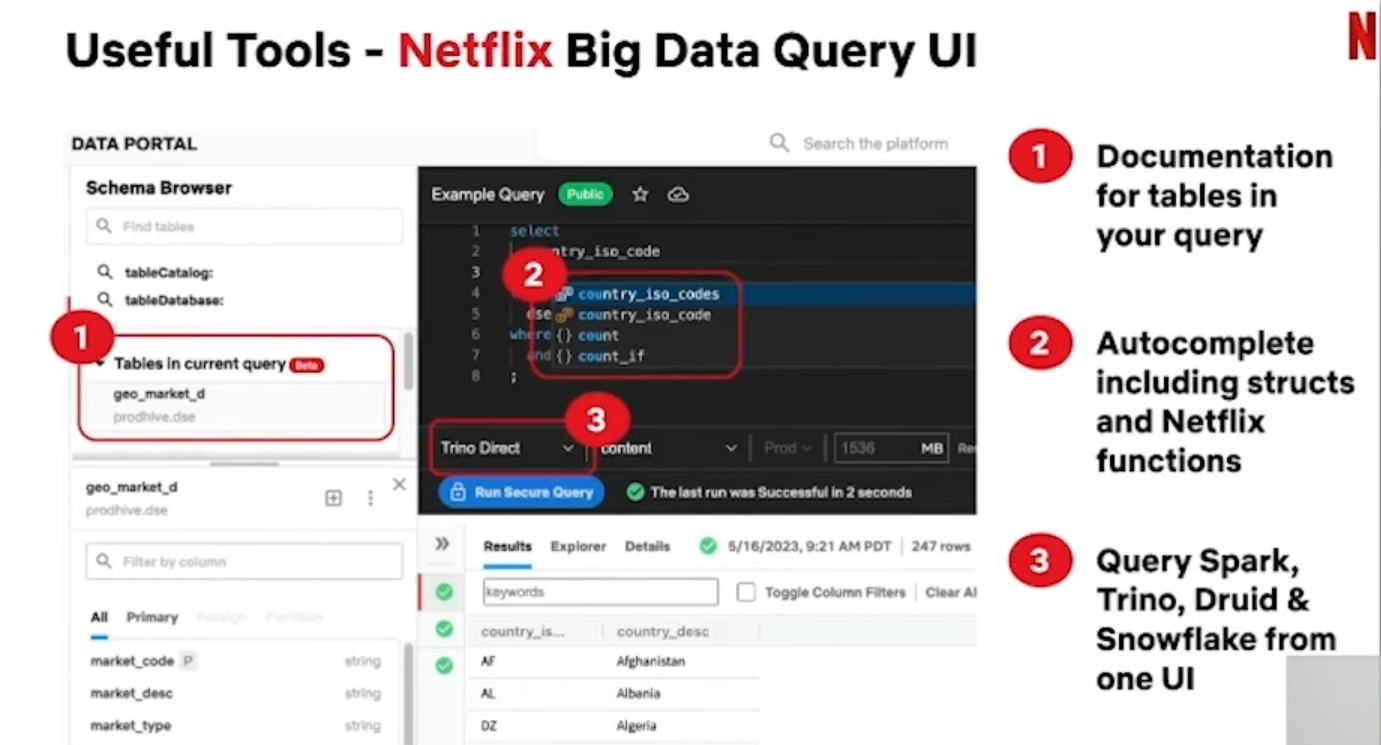
Netflix資料工程技術架構最大目標是,讓常見需求更容易進行,而且能兼顧各層級的客製化需求,Netflix自己打造了許多好用工具,例如大數據Query UI工具就是他們的資料工程師最常用的工具。圖片來源/Netfllix
建立WAP稽核模式,自製稽核工具確保資料品質
Netflix採取了一套稽核模式稱為WAP模式,當資料第一次寫入(Write)時,會先產生一個隱藏的資料表快照,在用Netflix資料稽核工具對寫入的資料進行檢查(Audit),只有通過所有稽核後,才會發布(Publish)這個Iceberg快照版本,作為當前所用的資料表快照版本。Netflix在發布快照時,不會進行資料複製,不將快照資料複製一份後再發布。一方面因為這些資料集都非常龐大,另一方面,Netflix更新資料的頻率很快,每天都會重建許多資料集,複製資料的代價是會拖慢了整個資料工作流程。
資料稽核工具還可以細分成兩類,一種是通用稽核工具,提供了資料工程師經常必做的資料稽核,包括了鍵值檢查(不重複或空值)、資料例外檢查、行數或欄位數檢查。另外一種是特定脈絡稽核工具,例如一部電影不能有多個片頭。十大熱門影集要有主打預告。要打造這類稽核工具,資料工程師也得對所擁有的資料有更深度的理解,以及了解資料的利害關係人在乎的點是什麼。
排程平臺每天執行7萬個工作流程
在Netflix批次處理流程中的第三步驟是任務排程和監控。Netflix自己打造了一套能支援超大規模任務的工作流程排程平臺Maestro。這個平臺現在每天會執行高達7萬個工作流程,累計超過了50萬個任務步驟。
資料工程師可以透過YAML DSL語法或Python DSL語法,很容易就可以定義工作流程,來組合不同資料工程處理或是機器學習的任務。甚至可以透過UI介面或只需撰寫很少量的程式,就能預先定義不同任務的處理流程,再透過Maestro指定排程時間,定期執行。
Maestro還支援事件驅動模式,可以指定驅動流程的事件,一旦出現了指定事件,才會啟動對應的工作流程。資料使用者得將想要執行的工作流程,註冊到訊號服務中,這個訊號服務會不斷偵測各種資料來源的變動事件資訊,一但出現某個資料事件,例如檔案上傳到S3了,就會驅動在登記清單中的工作流程所對應的任務,來展開批次處理作業。
在Netflix資料工程架構中的各種工具和系統,幾乎所有的事件都會留下Log紀錄,儲存到資料倉儲中,整合到一個隨時可用的Iceberg資料表中,包括了每一項批次處理的所有任務,所有的資料稽核結果,資料表的各種使用行為等。
批次處理流程的最後一項是資料管理。Netflix有一個成本分析儀表板工具dlmdash,用來計算每一個資料工作流程的運算成本,還有資料表的儲存成本,並且會按照團隊、部門、平臺來分類統計,也會列出成本特別高的排名清單。不只分析成本,資料管理上搭配了一個主動式的資料清潔工工具,會自動清除沒有使用的資料。
例如,不少工程師在開發階段常會建立了不少只有自己才會用到的資料欄位,等到將這隻程式部署到正式環境後,清潔工工具就會自動移除那些只給個人使用的資料欄位來節省資源。或是有資料工程師新建了一個資料表,經過一段時間都還沒開始使用,清潔工工具也會自動刪除這個資料表。這個資料清潔工工具,會強制執行Netflix的資料留存規則,不符者就會移除。

熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10


2026-02-06

2026-02-10