,可以從更抽象化的層次來設計、執行和管理資料處理流程。圖片來源/Netfllix")
Netflix有一套資料處理平臺Data Mesh(資料網格平臺),可以從更抽象化的層次來設計、執行和管理資料處理流程。圖片來源/Netfllix
除了批次流程以外,另一個Netflix資料工程架構中的重要流程是即時資料的處理流程,包括了串流資料和資料服務產生的資料處理。
這個即時資料平臺的核心是Apache Flink,這是Netflix用了多年的串流主要技術,在這個即時資料平臺上,提供了大規模執行Flink任務和打造Flink應用的工具,也可以與底層基礎架構系統溝通,來部署需要的容器叢集資源,例如透過Spinnaker派送平臺,將串流任務派送到不同公雲上的運算叢集來部署。另外也內建了可觀察性、警報機制、配置機制和效能矩陣等工具。透過一個網頁介面的控制平臺(Control Plane),資料工程師可以很容易管理在這個即時資料平臺上的Flink應用。
除了自己開發Flink的應用來處理串流服務之外,這個即時資料平臺也提供一個串流處理即服務(Streaming Platform as a Service),稱為Keystone,提供了一個現成、能自行客製和管理的串流服務平臺,可以用來組合出一隻大規模串流處理的應用服務,而不用從頭開始打造所有的串流服務元件,讓資料使用者專心處理串流資料處理的業務邏輯,其他非功能性的串流服務需求,則直接使用這個平臺提供的元件服務來組合。
換句話說,多數串流處理任務都可以直接用Keystone上的串流處理服務提供的元件來組合出一隻專用的串流處理應用,Netflix也會利用Keystone可以設計一個專門回補資料(Backfilling)的串流處理程序,例如有時會因為網路延遲而晚到,來不及寫入原本串流處理程序的資料,可改用這個回補處理程序,來將缺漏的資料,寫回到原本的串流處理應用中。
在即時資料處理流程的可觀察性上,主要透過另一套串流應用監控服務Mantis,來觀察不同資料處理階段的狀態,可以追蹤這些串流處理任務的部署和管理,像是這些任務的資源調度或是彼此之間的溝通,也提供了可視化介面來呈現透過Mantis蒐集到的可觀察性數據。
Netflix會將常用或成熟的即時資料處理程序,透過Spring boot框架和gRPC,打包成一個套裝的即時資料服務(Real-time Data Services),對外提供給其他資料消費者。例如他們有一個抽取使用者互動資料特徵的處理作業,稱為 PLUID,會打包成一隻PLUID即時資料服務,能夠提供行為特徵資料,來給模型訓練,或其他服務之用。這是他們現在越來越常用的模式,將即時資料處理程序,打包成雲端的資料服務,來串接其他應用。
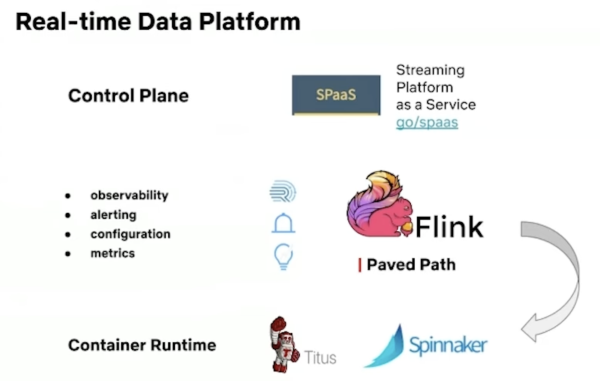
串流處理是Netflix資料工程技術架構中最典型的兩大資料流程之一。這個即時資料平臺提供了大規模執行Flink任務和打造Flink應用的工具,也可透過Spinnaker與底層基礎架構系統溝通,來部署需要的容器叢集資源。還內建了可觀察性、警報機制、配置機制和效能矩陣等工具。更提供了網頁介面的控制平臺(Control Plane),資料工程師可以很容易管理在這個即時資料平臺上的Flink應用。圖片來源/Netfllix
最新一代資料處理平臺是資料網格平臺
Netflix的串流處理方式,除了用低階的Flink API來打造出一隻客製化的Flink,也可以用剛提到的Keystone來組合出一隻串流處理應用,但是,Keystone擅長ETL類的資料處理,遇到更複雜的資料處理邏輯,還要擴大規模,Keystone就顯得不夠用。
這幾年,Netflix發展出了一套新的資料處理平臺,稱為Data Mesh(資料網格平臺),可以從更抽象化的層次來設計、執行和管理資料處理流程。
資料網格平臺是一個通用型的資料移動和處理平臺。一開始,在2021年時,Netflix製片工作室為了將龐大的影片資料,在不同的電影製作階段中,需要一有影片內容異動,就得將異動段落內容,更新派送到不同的製作公司的資料工作流程管理平臺,當時的資料網格平臺還不是通用型的平臺,主要用來處理以異動資料更新模式為主的資料移動作業需求。
後來,資料網格平臺所支援的資料來源和資料類型越來越多,也可以支援更多形式的資料處理作業,甚至是一般資料移動的模式,或是更複雜的資料處理模式,例如過濾、聯集處理、JOIN連結等。
資料網格平臺主要功能區分為控制平臺(控制器)和資料平臺(工作流程),工作流程是實際的資料處理作業過程,而控制器則是用來接收使用者的需求,對定義好的工作流程,來進行部署和調度。控制器也會負責配置每一個工作流程需要的各種資源。一個工作流程,則包括了從不同資料源讀取資料,進行各種轉換處理,再存入資料儲存空間。
在資料網格平臺上,資料使用者,可以從更抽象層的角度,來操作不同資料處理作業的功能區塊,組合成一個完整的資料處理流程,這些區塊包括了資料源區塊(存取內部資料源)、資料源連結器區塊(連結外部資料源)、處理器區塊(負責資料處理邏輯的Flink任務)、用Kafka打造的資料搬運層區塊。
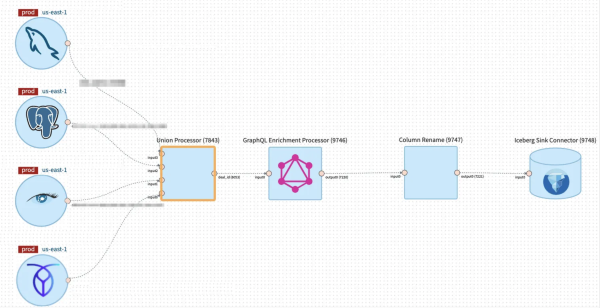
Netflix近3年又發展出了一套新的資料處理平臺,稱為Data Mesh(資料網格平臺),可以從更抽象化的層次來設計、執行和管理資料處理流程。資料使用者可以從更抽象層的角度,來操作不同資料處理作業的功能區塊。資料工程師只需控制滑鼠,拖拉UI介面上不同功能區塊元件,建立區塊間的連結關係,就可以完成這個工作流程,完全不用處理底層不同元件、服務、API之間的串接程式碼撰寫和配置細節。圖中為一個彙整不同公雲上不同資料來源,進行聯集處理、GraphQL處理、欄位更名再存入Iceberg資料表的工作流程。圖片來源/Netfllix
所有工作流程都要定義資料結構,以便清楚追蹤資料血統
另外Netflix還規定,所有工作流程都要定義出資料Schema(資料結構),採用源自Hadoop專案的Avro資料格式,用JSON來訂定各自需要的資料架構格式。有了共同的資料架構格式,不只可以控管資料品質,能清楚追蹤資料血統(Data Lineage),也讓資料使用者更容易進行各種資料的探索。
每當建立一個工作流程時,都須要同步定義出這個流程所用資料的資料結構,資料網格平臺會自動依據資料結構,對這個工作流程中所有資料進行驗證和相容檢查。也會有自動化機制處理資料結構的變化,如果資料源的資料結構改變了,資料網格平臺會自動更新哪些用到這個資料源的所有工作流程,不用人工比對和更新這些資料架構的異動,大大減少資料維護的例行工作。
用滑鼠拖拉功能區塊元件,就能快速設計出一條工作流程
不只如此,資料工程師可以透過宣告式API,或是容易操作的UI介面,快速設計出一項資料處理程序的完整工作流程。資料工程師只需控制滑鼠,拖拉UI介面上的區塊元件,建立區塊間的連結關係,就可以完成這個工作流程,完全不用處理底層不同元件、服務、API之間的串接程式碼撰寫和配置細節。有了預先訂定的各種資料處理工作流程,當資料使用者提出請求,資料網格平臺會自動依據流程上的每一個步驟、區塊的功能,自動執行一連串的作業。
還有一群處理器區塊的工程師,專門開發和改善更多不同用途的Flink任務,來提供更多用途的處理器區塊。
Netflix也提供了不少常見資料處理作業的最佳工作流程範本,稱為最佳上路範本(The Paved Path),讓資料工程師快速套用,不用從頭開始構思,只要從範本開始修改客製即可,來縮短資料處理流程的設計時間。資料網格平臺正是Netflix資料工程架構中,最新一代的資料工作流程解決方案,可以提供非常高層次的抽像化,讓資料使用者更直覺,也更能聚焦在業務邏輯上,來設計他所需要的資料處理流程。
從零到2億名會員的過程中,為了支援各種資料工程的實踐,Netflix自己打造了各式各樣的工具和技術。Chris Stephens指出,資料工程技術架構最大的目的,就是要讓資料工程團隊最常做的事情,變得更簡單。
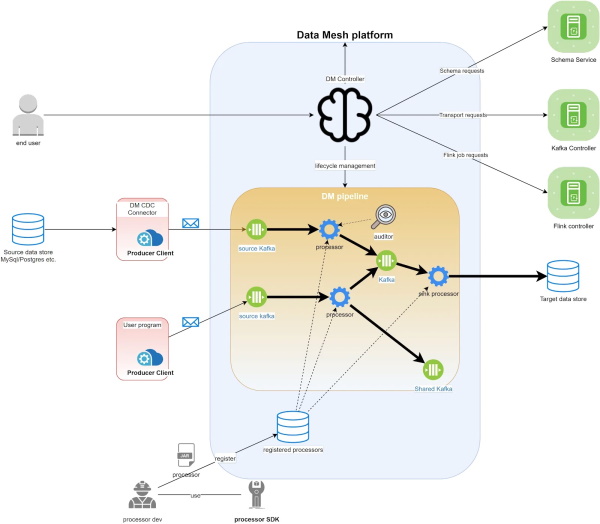
有了預先訂定的各種資料處理工作流程,當資料使用者提出請求,資料網格平臺會自動依據流程上的每一個步驟、區塊的功能,自動執行一連串的作業。還有一群處理器區塊的工程師,專門開發和改善更多不同用途的Flink任務,來提供更多用途的處理器區塊。Netflix也提供了常見資料處理作業的最佳工作流程範本(The Paved Path),讓資料工程師快速套用,不用從頭開始構思,只要從範本開始修改客製即可,來縮短資料處理流程的設計時間。圖片來源/Netfllix

熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10


2026-02-06

2026-02-10