
Stability AI發表新的文字轉圖像模型Stable Cascade,其建立在Würstchen架構上,可以簡單地在消費級硬體上訓練和微調。經過官方的測試,Stable Cascade不只效能較好,產生的結果也比SDXL更好。Stable Cascade模型的相關資料已經在GitHub頁面上公開,不過僅採用非商用授權,僅允許非商業用途使用。
Stable Cascade將文字轉換成為圖像,會經過三個步驟A、B與C流程,分別是潛在生成階段的步驟C,以及潛在解碼階段的步驟A與步驟B。潛在生成階段中,用戶的輸入會被轉換成為壓縮的24x24潛在表示,也就是小型圖像資料,這些小型圖像資料會被傳遞給潛在解碼階段。潛在解碼階段的工作則是類似Stable Diffusion變分自編碼器(VAE)的角色,將壓縮的潛在表示解碼成高解析度圖像。
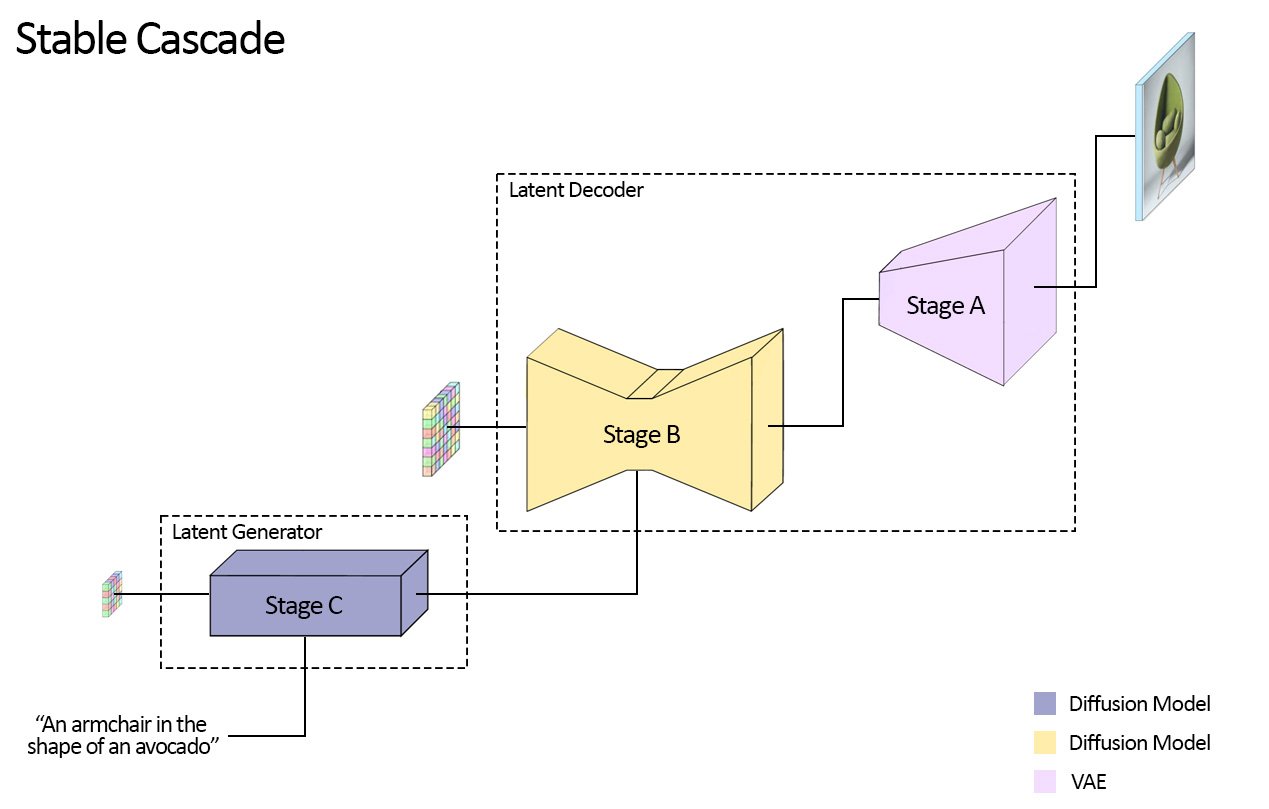
簡單來說,Stable Cascade步驟C就是將用戶的指令,轉換成一張小型且簡化的圖像草稿,草稿僅包含重要的資訊,接著草稿被輸入到步驟A與步驟B,並被加入更多細節並且放大,形成一張詳細且高解析度的圖片。由於將文字條件生成的步驟C,以及解碼到高解析度畫素空間的步驟A、B分離,因此便可以單獨對步驟C進行額外的訓練和微調,包括ControlNets和LoRAs的訓練。
官方解釋,這與訓練一個類似大小的Stable Diffusion模型相比,節省的成本可達16倍。雖然步驟A與步驟B也可以選擇性進行微調以獲得更多控制,但對大多數用途來說,其帶來的額外好處有限,因此用戶只要訓練步驟C,並且使用原始狀態的步驟A和步驟B即可達到良好的成果。
Stability AI發布步驟C和步驟B各兩種模型,步驟C具有10億參數與36億參數模型,而步驟B有7億與15億參數兩種模型。官方建議用戶使用步驟C的36億參數模型,以擁有最高品質的輸出,而對於追從低硬體要求的用戶則可以選擇10億參數版本的模型。至於步驟B的兩個模型,都能提供良好的結果,只是15億參數的模型更擅長重建細節。
由於Stable Cascade的模組化方法,推理使用的顯示卡記憶體約只需要20 GB,而使用更小的模型則需要的記憶體量也會降低。
Stable Cascade在與Playground v2、SDXL、SDXL Turbo、Würstchen v2文字轉圖形生成模型比較,無論是提示詞對齊(Prompt Alignment)和美學品質上,Stable Cascade幾乎都是表現最佳的模型。而且在推理速度的比較上,即便Stable Cascade最大的模型比Stable Diffusion XL多出14億參數,仍然具有更快的推理速度。
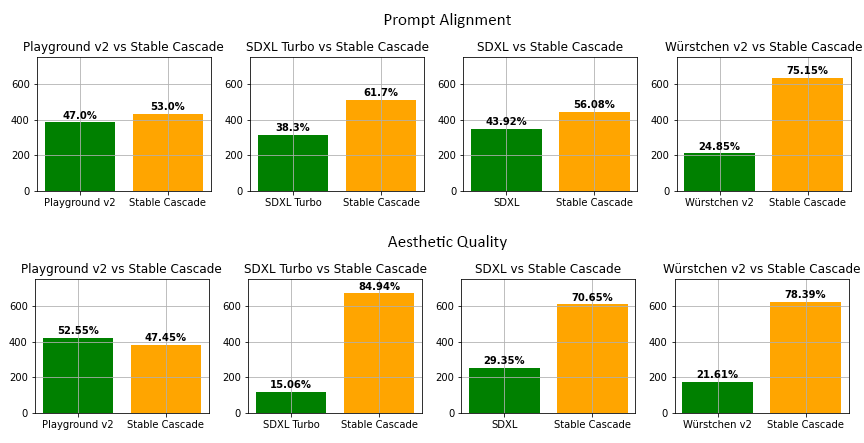
官方提到,這代表Stable Cascade在架構設計和高度壓縮的潛在空間上,都有較好的效率,可以在保持高品質輸出的同時,又能維持高效的推理速度。而除了標準文字轉圖像生成之外,Stable Cascade也具有生成圖像變體,還有以圖像生成圖像的能力。
Stability AI不只發布Stable Cascade,也同時將用於訓練、微調、ControlNet和LoRA的所有程式碼一併公開,以降低研究人員實驗此架構的障礙。
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
")
2026-02-09
")
2026-02-09

2026-02-09