
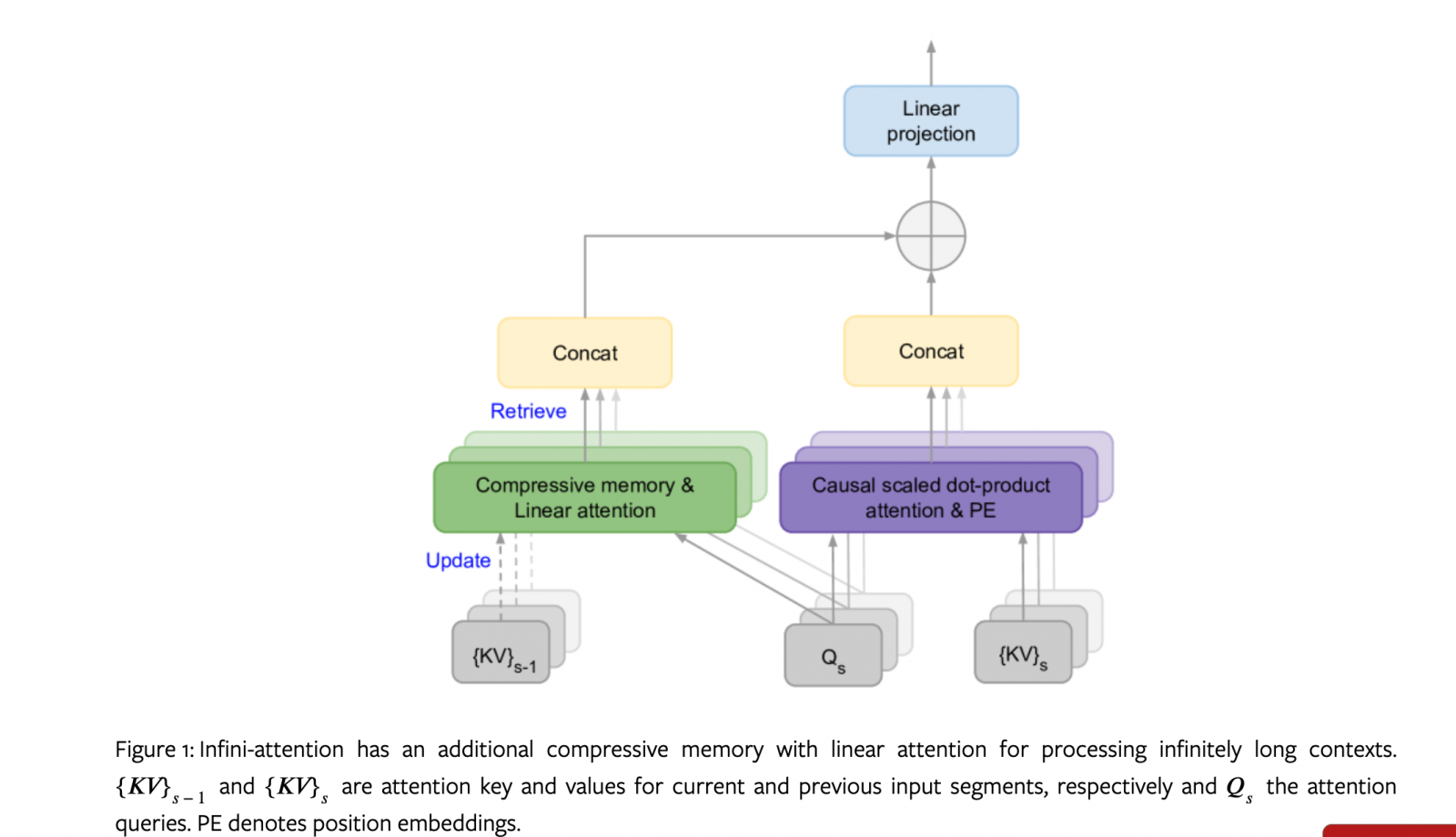
Google團隊設計一種無限注意力機制,能將壓縮的記憶納入普通注意力機制中,並將遮罩的局部注意力和長期線性注意力機制,結合在單一個Transformer區塊。
螢幕截圖
重點新聞(0405~0411)
LLM Google 文長
Google一篇論文揭示LLM如何處理無限長文字輸入
Google最近揭露一種Transformer大型語言模型(LLM)的新擴展方法,可利用有限的記憶體和運算資源,來處理無限長的文字輸入。Google在《Leave No Context Behind》論文中說明這項新方法,他們設計一種無限注意力(Infini-attention)機制,將壓縮的記憶納入普通注意力機制中,並將遮罩的局部注意力和長期線性注意力機制,結合在單一個Transformer區塊,能讓模型具備完整的上下文知識。
這個無限注意力機制,可重複使用標準注意力的鍵、值和查詢狀態,來進行長期記憶整合與檢索。有別於丟棄舊的鍵值(KV),無限注意力方法將舊鍵值儲存在壓縮的記憶體,並用注意力查詢狀態來檢索值,以便處理之後的序列。這個修改Transformer注意力層的作法,能支援模型的連續預訓練和微調,進而讓LLM可以處理無限長度的文字。
經測試,使用這個方法的模型,在長文語言模型測試基準中,表現都比基準模型要好,甚至可實現114倍的理解率。他們也發現,10億參數的LLM採用該方法,可將輸入值長度擴展至100萬個序列,還能實現密鑰檢索任務。最後,他們實驗顯示,採用無限注意力機制的80億參數模型,在文長50萬的書籍摘要任務中能達到SOTA表現。(詳全文)
LLM 蘋果 UI
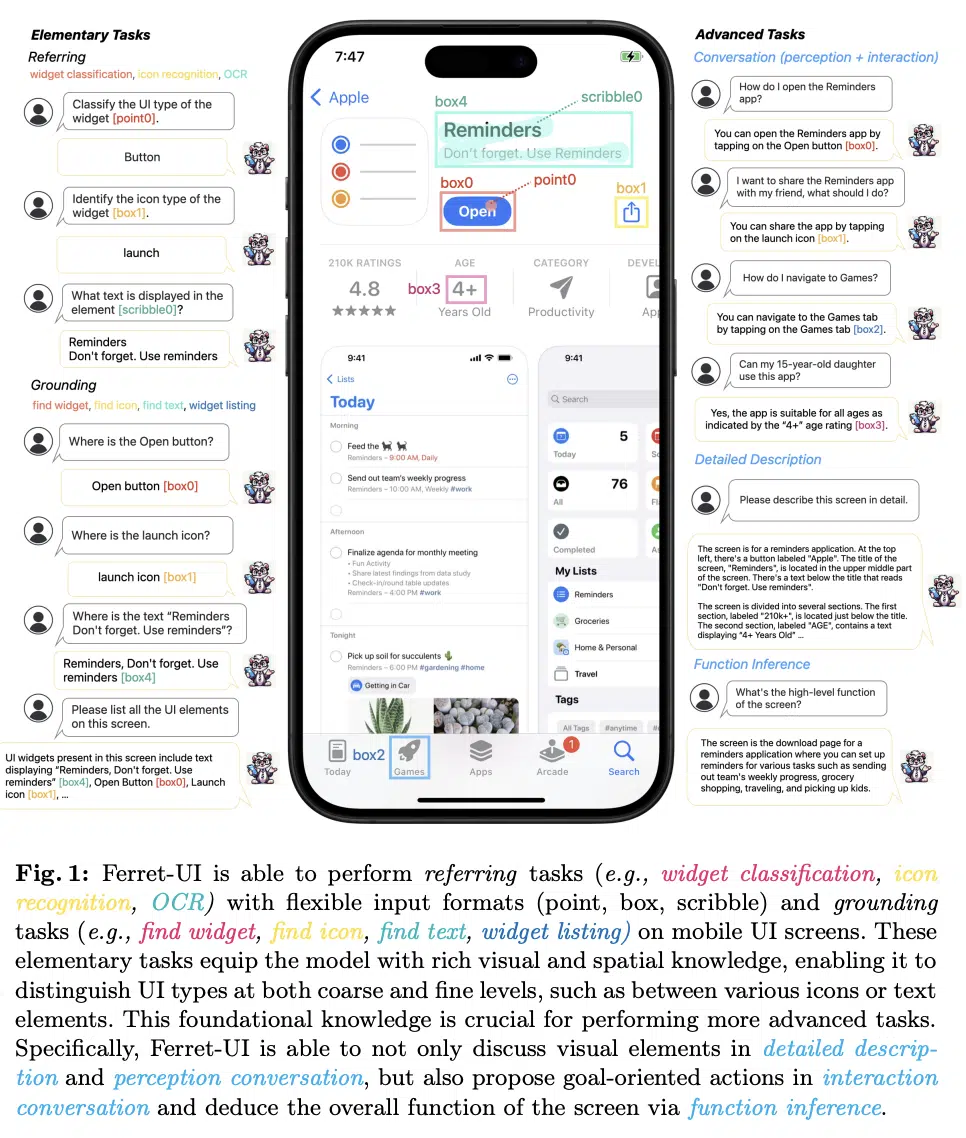
讓LLM更懂螢幕內容!蘋果揭新模型Ferret-UI
就在6月份的年度技術大會WWDC 2024前,蘋果發表一項大型語言模型(LLM)最新研究成果,自建一套Ferret-UI大語言模型,更懂行動裝置使用者介面(UI)的互動和細膩需求。蘋果團隊在論文中表示,雖然GPT-3這類LLM可執行多種任務,但仍難以理解UI互動,特別是行動裝置領域。
這是因為,行動裝置UI畫面和自然圖像很不一樣,UI畫面具有特定長寬比例,畫面上的物件也較小,比如icon圖示和文字,這些特性在自然圖像上很難見到。為解決這些挑戰,Ferret-UI採用了任意解析度的機制,能處理不同長寬比的螢幕,還能放大細節、增強提取的視覺特徵。Ferret-UI接著對每個子圖像分別編碼,來避免丟失關鍵的視覺資訊。
此外,Ferret-UI還採用一種新的資料管理方法,從各種UI任務中收集訓練樣本,這些任務包括圖示辨識、尋找文字和小工具列表。這些任務讓Ferret-UI學會認識UI元素的語義和空間定位,因此能進行更廣泛的任務。除了基礎任務,Ferret-UI也進行特定任務訓練,如生成詳細描述、感知對話理解和功能推理。為評估Ferret-UI,團隊還建立一個涵蓋各種UI任務的基準測試,與其他開源LLM和GPT-4V相比,Ferret-UI表現更好,尤其是在基礎UI任務和高階推理能力上。若蘋果將Ferret UI整合到智慧助理Siri中,可實現無縫的應用程式整合、推進自然語言導航等。(詳全文)
Gemini Google 生成式AI
Google生成式AI助理Gemini for Google Cloud正式亮相
在本周舉行的Google Cloud Next '24上,Google正式發表Gemini for Google Cloud,是一款以大型語言模型Gemini驅動的生成式AI助理,按不同功能分為不同助理,包括Gemini Code Assist、Gemini Cloud Assist、Gemini in Security Operations、Gemini in BigQuery、Gemini in Looker和Gemini in Databases等。Google將Gemini打造成統一的AI品牌,不只於今年2月將聊天機器人Bard更名為Gemini,還以Gemini品牌全面取代先前發表的AI助理Duet AI。
其中,Gemini Code Assist是先前的Duet AI for Developers,可協助開發者在VS Code和JetBrains等熱門程式編輯器中建置應用程式。Gemini Cloud Assist則是應用程式生命周期管理工具,能提供有關應用程式的設計、部署、管理和排除故障的個人化建議。Gemini in Security Operations則是繼承Duet AI in Security Operations,新版已將Gemini整合至Chronicle安全營運平臺,能更輕鬆偵測、調查與回應威脅。
Gemini in BigQuery可協助資料工程師和分析師,用自然語言從海量資料中分析或找出有價值的資訊。Gemini in Looker則是商業智慧工具,可以聊天方式與資料庫對話,或用來建立圖表和報告。Gemini in Databases則讓Database Studio具備生成、摘錄SQL的能力,也允許使用者從Database Center中管理所有資料庫或資料庫遷移。(詳全文)
生成式AI 外掛 Google Workspace
Google Workspace新添多種生成式AI外掛
Google Workspace是生產力工具,現有30多億名用戶和1,000多萬名付費用戶。去年Google大舉投入AI,也為Workspace的Gmail、Docs、Sheets等應用內建Gemini。這次在今年度Next'24開發者大會上,Google宣布新添更多AI加持的應用,如Google Vids是款商務AI影片製作App,可製作行銷、客服或業務訓練等影片,還能協助用戶配音。Vids預計今年6月提供Workspace Labs更多人測試,之後由Gemini for Google Workspace方案開放訂閱。
再來,Google Workspace也加入AI會議與訊息、AI安全等2項付費AI外掛功能。AI會議和訊息外掛可用於Meet用戶會議,像是專業攝影棚等級的攝影、打燈、音效、預覽版的「會議筆記」、聊天重點摘要和即時翻譯字幕功能。AI安全外掛可自動為公司Google Drive上的檔案與文件自動分類和加入防護,Google表示,該功能是以企業組織獨有資料訓練出AI模型後,用這些模型持續偵測和評估Drive的現有與新檔案。AI會議和訊息、以及AI安全收費皆為每人每月10美元。(詳全文)
LLM 聯發科 生成式AI
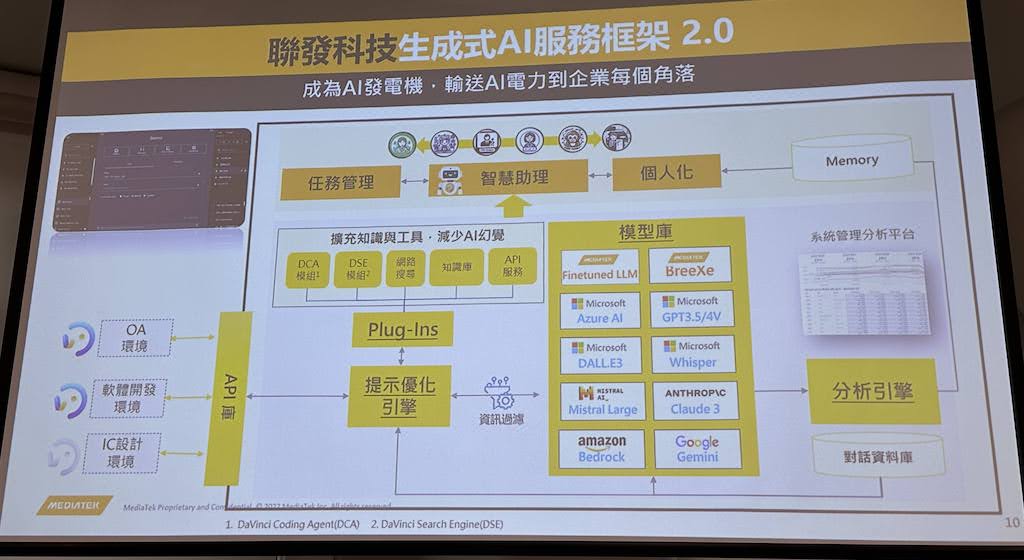
聯發科推出生成式AI服務平臺、最新繁中LLM
聯發科技日前一口氣發表生成式AI服務平臺MediaTek DaVinci(又稱達哥)和繁中大型語言模型MR BreeXe。首先,達哥最初是為集團內部開發,目的是要提高生產力,平臺內建API庫、提示優化引擎、擴充外掛庫、模型庫和分析引擎等重要元件。其中,外掛庫可用來擴充生成式AI模型知識、減少AI幻覺,模型庫則包含常見的大型語言模型(LLM),如Google Gemini、GPT-3.5/4V、Whisper、Claude 3和AWS Bedrock服務等,聯發科技自己最新打造的模型BreeXe也納入其中。
今年,聯發科技優化該平臺,新添智慧助理架構,能讓使用者不必寫任何程式碼,就能打造自己的智能秘書。這個版本的平臺就是達哥2.0,還具備4個主要商店,包括AI模型、擴充外掛、提示範本、知識庫(DVCs)等,另也配備許多功能,包括DocChat、VideoChat、WebChat和Plug-ins。另一方面,這次揭露的繁中模型MR BreeXe是以Mixtral 8x7B模型為基礎,以大量繁中資料預訓練而成,在繁體中文基準測試TMMLU+和MT Bench TW上超越GPT-3.5。該模型也對臺灣常見的地端應用特別優化,要提高產業界使用生成式AI和檢索增強生成(RAG)的體驗。使用者可透過達哥平臺使用MR BreeXe,它還支援全地端與部分地端場景,也能依需求進行少樣本學習和微調客製化。(詳全文)
LLM Mistral AI Mixtral 8x22B
Mistral AI開源1,760億參數模型Mixtral 8x22B
去年4月才成立的AI業者Mistral AI最近就釋出新版的開源模型Mixtral 8x22B,採稀疏混合專家(SMoE)架構、支援1,760億個參數和6.5萬個Token的脈絡長度,已由Mistral AI的官方X帳號、Together API和Hugging Face發布,成為目前最大的開源模型之一。
迄今Mistral AI已釋出3款開源模型,包括去年9月發表的Mistral 7B(Mistral-tiny),去年12月發表的Mixtral 8x7B(Mistral-small)和這次推出的Mixtral 8x22B,它們皆採Apache 2.0授權,允許開發者免費下載,並在自己的設備或伺服器上執行。Mixtral 8x22B的基準測試表現不錯,在大規模多工語言理解MMLU的成績為77.3,勝過前一代Mixtral 8x7B的71.88,也超越GPT-3.5、Claude 3低階版Haiku、Gemini 1.0 Pro,但仍不及GPT-4和Claude 3 Sonet/Opus。在基礎常識推論HellaSwag測試中,Mixtral 8x22B得分為88.9,僅不及GPT-4、Claude 3 Sonet/Opus和Gemini 1.5 Pro;但它在GSM8K數學測試中的得分為76.5,明顯不及GPT-4、Claude 3和Gemini的各種模型。不過,使用者可下載微調模型,打造為適合自己任務需求的模型。(詳全文)
GPT-4 Turbo with Vision 視覺 OpenAI
OpenAI GPT-4 Turbo with Vision上線
OpenAI最近加入視覺能力的基礎模型GPT-4 Turbo with Vision已正式上線,供付費用戶存取。現在,付費客戶可透過API存取,也能用JSON模式或函式呼叫方式發出請求。
GPT-4 Turbo with Vision是OpenAI的大型多模態模型,整合自然語言處理和視覺理解能力,可分析用戶上傳的圖片並以文字回應。最新模型和GPT-4 Turbo同樣具有128K個Token脈絡,且訓練資料已更新到2023年12月。GPT-4 Turbo with Vision去年12月已先行整合到微軟Azure AI服務。(詳全文)
OpenAI 模型微調 延遲
OpenAI擴大AI模型微調功能
日前,OpenAI公布AI模型微調功能,讓企業或開發者自行微調AI模型,同時也提供企業輔助微調或從頭打造AI模型的服務。進一步來說,OpenAI在去年8月就推出GPT-3.5模型的微調API,已有數千家企業和開發商用來訓練上萬個模型。這個微調API不只能讓模型更理解訓練內容,還比普通ChatGPT單一提示支援更多範例,可提高回應結果品質,同時降低成本與延遲性。
在這個基礎上,OpenAI再增加微調功能,包括周期(epoch-based)為基礎檢查點,減少過度擬合必須再訓練的困擾;比較性Playground UI,可同時比較多個模型輸出結果,或檢視在單一提示下的微調效果;整合第三方平臺,第一批包括Weights和Bias,方便開發者將微調的資料分享到其他軟體;大量參數配置,允許從Dashboard設定,以及微調能力的改善,支援輸入超大量參數、檢視詳細訓練量測值等。若企業需要幫忙微調,OpenAI也推出自訂模型方案,由一組OpenAI技術人員協助企業訓練與優化特定領域的模型。(詳全文)

圖片來源/Google、蘋果、OpenAI
攝影/王若樸
AI近期新聞
1. Meta揭露最新一代AI晶片MTIA
2. 吳恩達開設LLM非結構化資料處理課程
3. Google新推2款Gemma系列模型,分別用於程式開發和研究
資料來源:iThome整理,2024年4月
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-09

2026-02-10


2026-02-10

2026-02-06