
Meta
Meta周四(4/18)釋出新一代的開源大型語言模型Meta Llama 3,目前具備Llama 3 8B及Llama 3 70B兩種版本,即將透過AWS、Databricks、Google Cloud、Hugging Face、Kaggle、IBM WatsonX、Microsoft Azure、NVIDIA NIM與Snowflake等平臺供應。
Meta表示,該公司對Llama 3的目標是可與現今最好的專有模型媲美,並提高Llama 3的整體實用性,由於改善了預訓練與後訓練,大幅減少錯誤拒絕率,改善一致性,強化了模型反應的多樣性,且不管是在推論、程式碼生成或指令遵循上都有所進步。
於是,若相較於Gemma 7B-it及Mistral 7B Instruct這兩個分別由Google及Mistral AI所發表的開源模型,Llama 3 8B不管是在MMLU、GPQA、HumanEval、GSM-8K或MATH等基準測試上都大幅勝出。若以Llama 3 70B來比較商用的Gemini Pro 1.5及Claude 3 Sonnet,那麼,Llama 3 70B全面贏過了Claude 3 Sonnet,也在MMLU、HumanEval與GSM-8K上超越Gemini Pro 1.5。
.png)
圖片來源_Meta
Llama 3不僅追求基準測試上的效能,也希望能最佳化其真實場景的應用,因而打造出一個新的人類評估集,涵蓋了12個關鍵應用的1,800個提示,包括尋求建議、腦力激盪、分類、封閉式問答、撰寫程式碼、創意寫作、萃取、塑造角色、開放式問答、推論、改寫與概要等,結果發現Llama 3 70B在大多數情況下的表現,都凌駕了Claude Sonnet、Mistral Medium及GPT-3.5。
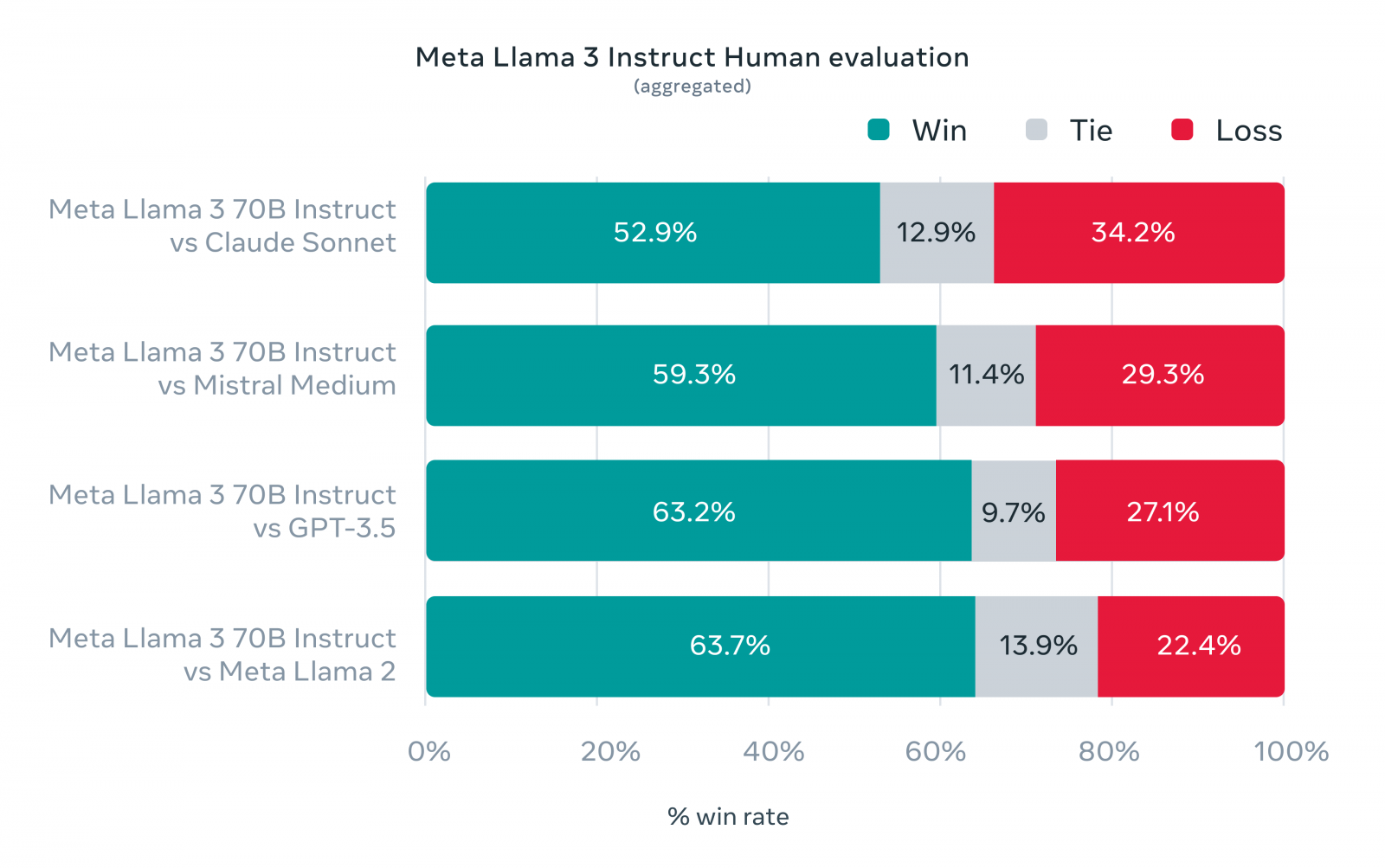
圖片來源_Meta
Llama 3使用了一個具備12.8萬個Token詞彙的標記器,可更有效地將語言編碼,以提高模型對文本的理解,另也藉由分組查詢注意力(Grouped Query Attention,GQA),以長達8,192個Token的序列來訓練模型,同時使用Mask來確保模型的注意力不越界,以改善推論成效。
此外,Llama 3是在超過15T個Token的資料上進行預訓練,用來訓練的資料集是Llama 2所使用的7倍大,當中所包含的程式碼是之前的4倍多,而且有超過5%的訓練內容來自於非英文的資料,這些資料是由逾30種語言組成。Meta也坦承,其它語言在Llama 3上的表現無法與英文一致。
為了訓練最大的Llama 3模型,Meta結合了3種平行化策略,包括資料平行化、模型平行化與管道平行化,有助於將模型訓練的運算分散到不同的運算設備上,因而在1.6萬個GPU上進行訓練時,每個GPU的利用率超過400 TFLOPS,亦於兩個客製化、具備2.4萬個GPU的叢集上進行訓練,也為了最大化GPU的利用率,打造先進的訓練堆疊以自動化錯誤的偵測、處理與維護。
再加上改善了硬體可靠性與偵測機制,發展更具彈性的儲存系統,而令Llama 3模型的訓練效率比Llama 2提高了3倍。
Llama 3模型很快就會登上各大雲端平臺,或是透過模型API供應商釋出,Meta將會繼續改善Llama 3,也正在開發最大的、具備4,000億個參數的Llama 3模型,儘管現在的Llama 3 400B還未完成,但Meta已公布它現有的基準測試成績供外界一睹為快。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09

2026-02-06


2026-02-09

2026-02-09