
圖片來源:
Hugging Face
Meta周四(6/27)發表了LLM Compiler,此為奠基於程式碼生成模型Code Llama的新模型,額外強化了對編譯器中介語言(IR)、組合語言及最佳化技術的理解,可用來改善所生成的程式碼品質,目前已可透過Hugging face取得。
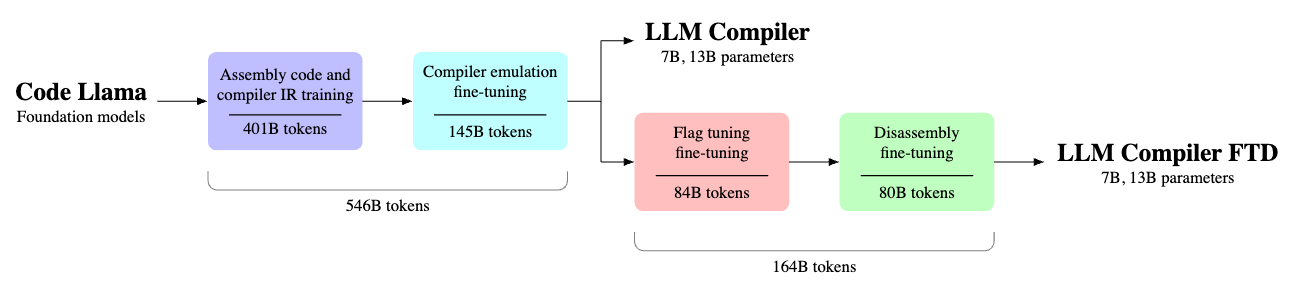
Meta表示,LLM Compiler模型能夠模擬編譯器的功能,得以預測哪些最佳化步驟能夠達到最佳的程式碼尺寸,或是將以已編譯的程式碼轉換回原本的語言,目前提供7B與13B兩種版本,透過相對寬鬆的授權允許研究及商業使用。
這是因為Meta認為,儘管大型語言模型(LLM)在各種軟體工程及程式碼任務中展現卓越的能力,但它們在程式碼及編譯器最佳化領域上的應用,卻未得到充分的探索,訓練LLM是個資源密集,需要大量GPU時間與大量資料收集、可能令人望之卻步的任務,而LLM Compiler即是個專為最佳化程式碼任務所設計的預訓練模型,並可供公開使用。
LLM Compiler已於5,460億個LLVM-IR與組合程式碼的Token上進行訓練,指令亦已經過微調以更好地理解編譯器的行為,開發者可透過客製化的商業授權以進行廣泛的運用,現有具備70億參數及130億參數的兩種模型可供選擇。
Meta還展示了經過微調的模型版本,這些版本在優化程式碼大小,以及將x86_64和ARM組合語言反組譯回LLVM-IR的能力方面取得了顯著的進展。具體來說,這些模型可達到77%的程式碼最佳化潛力,以及45%的反組譯回路,當中的14%是精確匹配的能力。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10
Advertisement