
Liquid AI
去年才成立的Liquid AI周一(9/30)發表了3個Liquid基礎模型(Liquid Foundation Models,LFMs),分別是LFM-1.3B、LFM-3.1B 及LFM-40.3B。Liquid AI利用非Transformer架構來建置模型,並宣稱旗下模型在基準測試上,已凌駕那些規模相同的Transformer模型。
Liquid AI的4名創辦人都來自麻省理工學院(MIT)的計算機科學與人工智慧實驗室(CSAIL),致力於從第一原則(First principles)出發來建立新一代的基礎模型。
目前深度學習與自然語言處理的主流架構為Transformer,它採用自我注意力機制,來補捉序列中單字之間的關係,而不仰賴傳統的循環神經網絡(RNN)或卷積神經網絡(CNN),包括OpenAI GPT,Meta BART,或是Google T5等模型都是基於Transformer。
至於第一代的Liquid AI LFMs則是深受動力系統、訊號處理,以及數值線性代數的影響所打造的大型神經網路,且它們是通用的AI模型,能針對特定類型的資料進行建模,涵蓋影片、音訊、文字、時間序列及訊號等。Liquid AI表示,該公司的名字即是在向動態與自適應學習系統的根源致敬。
Liquid AI解釋,相較於Transformer架構,LFMs所占用的記憶體更少,特別是在更大量的輸入時。這是因為Transformer模型在處理長輸入時,需要保存鍵值(KV)快取,且這個快取會隨著序列長度而增加,使得愈長的輸入就會讓Transformer模型占用更多記憶體;而LFMs則能有效地壓縮輸入資料,而降低對硬體資源的要求。因此,在同樣的硬體上,LFMs能夠處理更長的序列。
在首波釋出的3種模型中,LFM-1.3B專為資源高度受限的環境所設計,LFM-3.1B 則是針對邊緣部署執行了最佳化,LFM-40.3B屬於專家混合(MoE)模型,是替相對複雜的任務所設計,同時Liquid AI也強調,其目標是開發能與現階段最好的LLM較勁的創新模型。
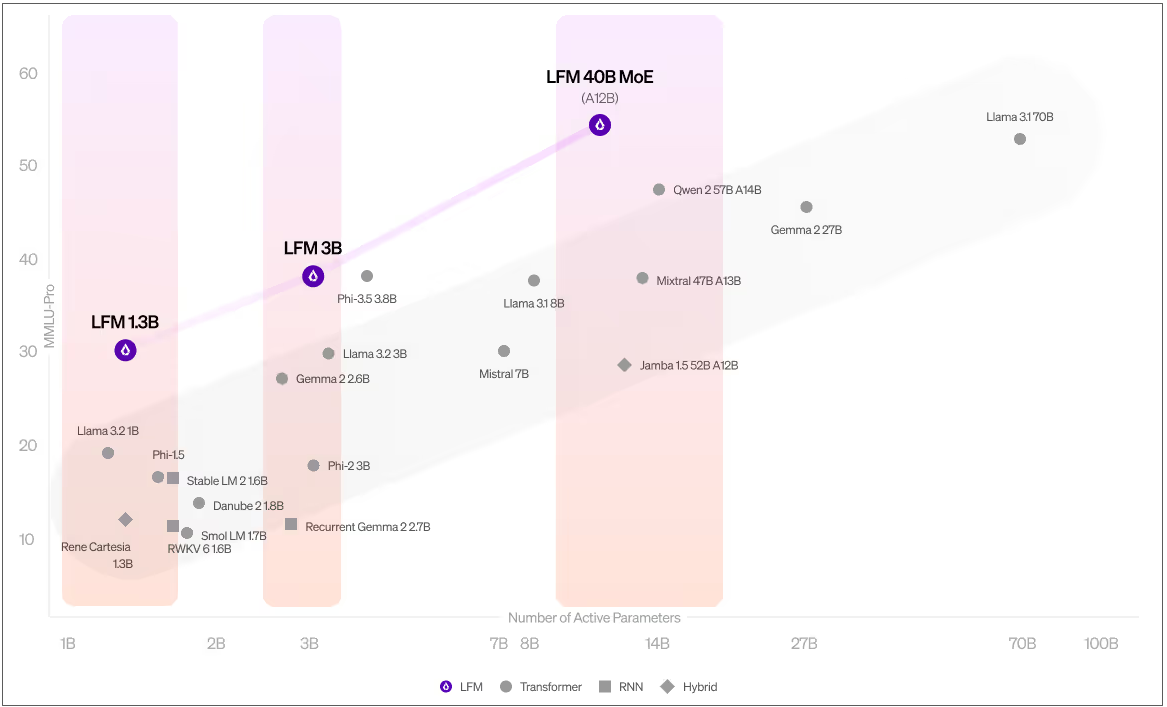
圖片來源/Liquid AI
其中,LFM-1.3B在許多基準測試中擊敗了1B領域的眾多好手,包括蘋果的OpenELM、Meta的Llama 3.2、微軟的Phi 1.5或是Stability的Stable LM 2,Liquid AI說,這是首次有非GPT架構的模型明顯超越Transformer模型。
而LFM-3.1B不僅超越了3B領域的各種Transformer模型、混合模型與RNN模型,甚至超越了前一代的7B與13B模型,不管是Google的Gemma 2,蘋果的AFM Edge AFM,Meta的Llama 3.2,微軟的Phi-3.5都屈居下風。
LFM-40.3B則強調模型規模與輸出品質之間的平衡,儘管擁有400億個參數,但執行時啟用120億個參數來推論,能比美比自己還大的模型,此外,其MoE架構能實現更高的吞吐量,也能部署在更具成本效益的硬體上。
現階段的LFMs擅長一般知識及專業知識,也能處理數學及邏輯推理,並可有效率地處理長文任務,主要支援英文,也支援中文、法文、德文、西班牙文、日文、韓文與阿拉伯文。較不擅長的則有零樣本的程式碼任務,精確的數值計算,具時效性的資訊,也無法計算Strawberry這個字中有多少個R,以及尚未部署人類偏好的優化。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09

2026-02-10


2026-02-10

2026-02-10