原本只在Azure AI Foundry平臺開放的Phi-4模型,現在微軟在Hugging Face上以寬鬆的MIT授權開源,這代表開發者已經可以自由使用、修改和散布該模型,包括LM Studio等語言模型執行工具已經能夠下載並且執行。Phi-4為微軟Phi系列的第四代模型,擁有140億參數,在多項基準測試中展現了與大型模型相匹敵的性能,特別是科學與數學領域。
不同於動輒數百億甚至數千億參數的大型語言模型,Phi-4的精簡架構使其對運算資源的需求大幅降低。微軟表示,Phi-4在1,920個Nvidia H100圖形處理器組成的叢集上進行訓練,耗時21天完成,其採用了廣泛使用的Transformer架構,並進一步精簡為僅包含解碼器(Decoder-only)的架構,藉此降低模型進行推論時的運算負擔。
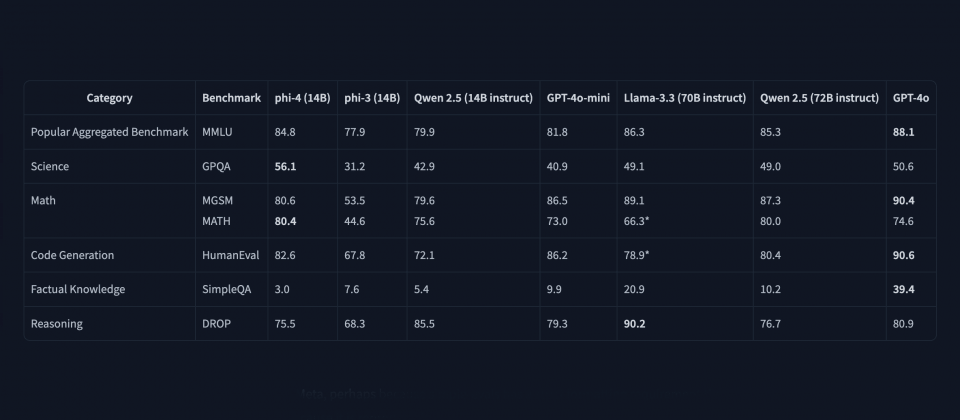
根據微軟在Hugging Face上公開的資料,Phi-4在GPQA科學問答及MATH數學題庫兩項基準測試中,超越了Meta具有700億參數的Llama 3.3 70B模型,甚至也比GPT-4o表現更好。微軟也將Phi-4與其他相近規模的模型進行比較,例如阿里巴巴的Qwen 2.5。Phi-4不僅超越了規模相近140億參數的Qwen 2.5,甚至與720億參數的Qwen 2.5版本旗鼓相當。雖然各模型在不同測試中互有領先,但Phi-4展現了小型模型也能達到甚至超越大型模型性能的潛力。
Phi-4僅含解碼器的架構影響了其運作模式。相較於標準Transformer模型能分析前後文脈絡來理解詞彙意義,唯解碼器架構模型僅關注當前詞彙之前的文本。這種設計雖能降低運算量,但也可能在需要依賴後文資訊才能準確理解的情境下影響其表現。
另一方面,微軟透過直接偏好最佳化(DPO)和監督式微調(SFT)等後訓練技術,對模型進行了強化,提升模型包括遵循指令的能力、生成內容的品質,以及降低產生有害或不安全輸出的風險。
Phi-4的開源使小型語言模型生態更加豐富,近年來,Google的Gemma系列與Meta的Llama 3,以及阿里巴巴的Qwen等模型相繼開源,顯示各大科技公司皆積極投入小型語言模型的研發。相較於大型模型,小型語言模型在部署成本、能源效率及執行速度都更具優勢,特別適合應用於邊緣運算、行動裝置等資源受限的情境。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-06

2026-02-09

2026-02-09