
Nvidia盤點3種影響AI表現的擴展法則,包括預訓練擴展、訓練後擴展和測試階段擴展,其中後者催生不少強大的推理模型,如OpenAI o系列、DeepSeek R1和Google Gemini 2.0 Flash Thinking等。
Nvidia
重點新聞(0207~0213)
Nvidia 運算資源 測試時間擴展
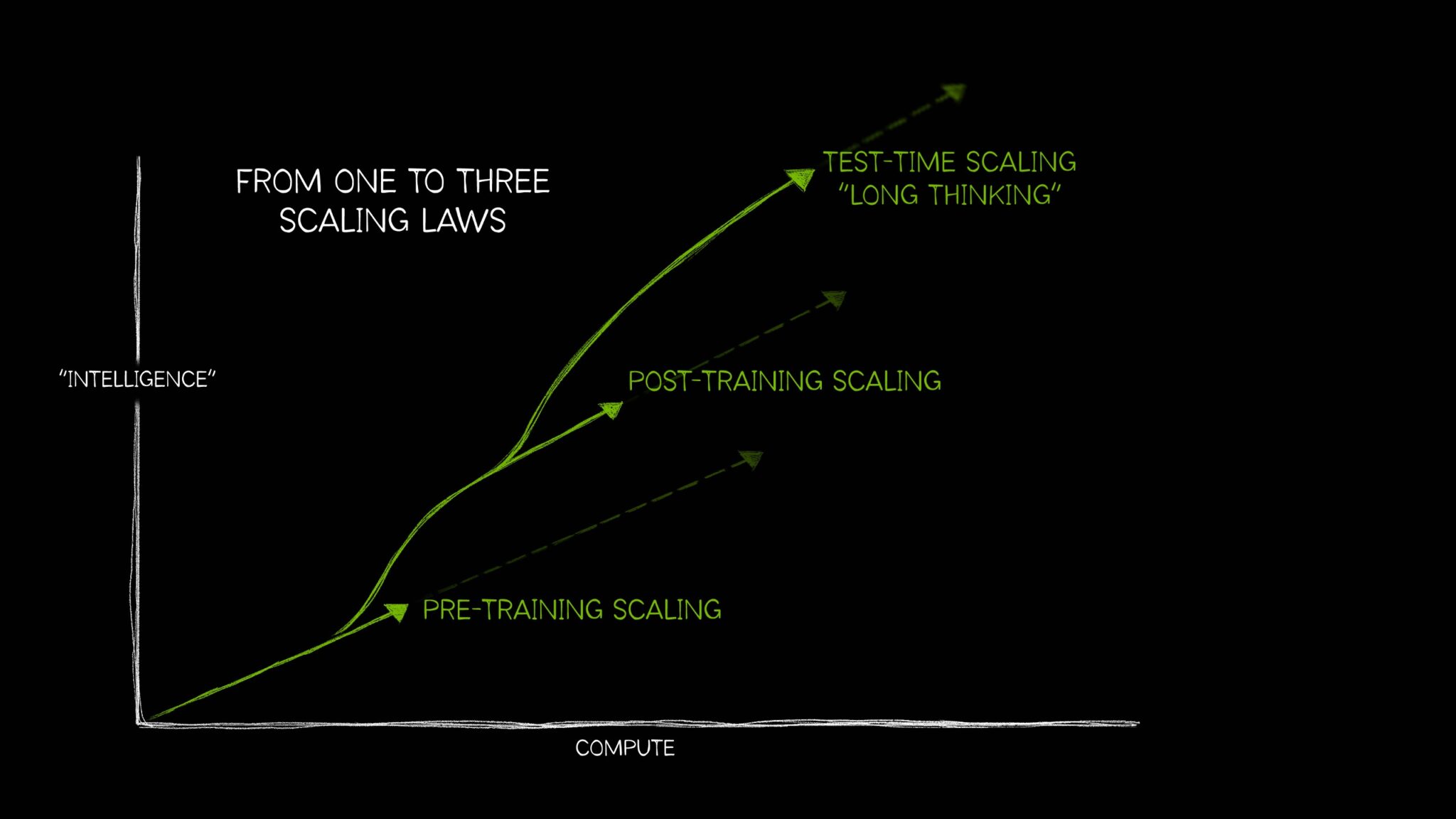
影響AI表現的3種擴展法則
隨著OpenAI o系列、DeepSeek R1和Google Gemini 2.0 Flash Thinking等推理模型興起,越來越多人關注推動這類推理模型的擴展法則。最近,Nvidia就發表一篇文章,來盤點3種影響AI表現的擴展法則:預訓練擴展(Pretraining scaling)、訓練後擴展(Post-training scaling),以及測試階段擴展(Test-time scaling)。
就預訓練擴展來說,它是AI發展的原始法則,透過增加訓練資料、模型參數和運算資源,來提高模型表現。這意味著,開發者需要擴大運算規模,用更多資料來訓練大量參數的模型。不過,這個法則也因此推動不少模型架構創新,比如具備數十億或上兆個參數的Transformer模型、混合專家(MoE)模型,也推進了分散式訓練等技術。
如果預訓練擴展像是送AI模型去學校學習基本技能,那麼訓練後擴展就是針對專業技能,進一步加強,比如用來優化大型語言模型處理情感分析或翻譯的能力。訓練後擴展有幾種常見的方法,如微調、蒸餾、強化學習(包括RLHF、基於AI回饋的RLAIF)、最佳解搜尋採樣(Best-of-n sampling)和搜尋方法。Nvidia認為,開發者也可用合成資料來增強微調用的資料集。
而最近興起的AI推理模型,如OpenAI o系列、DeepSeek R1和Google Gemini 2.0 Flash Thinking等,則受益於測試階段擴展。這個擴展法則又稱為長思考(Long thinking),與前兩種不同,測試階段擴展發生在模型推論階段,能讓模型回答複雜問題時,先推理問題、拆解成多個步驟,再給出最佳答案。也因此,這些模型在推理過程中需使用大量運算資源。常見的測試階段擴展方法有:思維鏈(CoT)提示、多數決抽樣、搜尋等。(詳全文)
幾何 DeepMind AlphaGeometry2
DeepMind模型幾何解題能力超越IMO金牌選手
DeepMind日前透露,自家的數學推理模型AlphaGeometry2在國際數學奧林匹亞(IMO)幾何的解題表現,已正式超越金牌選手的平均水準。研究團隊測試了2000至2024年間所有IMO幾何題,AlphaGeometry2以84%的解題成功率,大幅超越前代系統AlphaGeometry1的54%,且研究團隊挑出難度更高的IMO Shortlist幾何題子集IMO-AG-30,AlphaGeometry2成功解出全部題目,顯示AI在數學推理領域的突破。
這項技術結合了語言模型和符號推理系統,透過強化學習和增強搜尋演算法,讓AI能更有效地使用輔助線、拆解問題並建立完整的幾何證明。新版本擴展了AlphaGeometry的幾何領域語言,能更好地處理複雜幾何問題,包括軌跡定理(Locus Theorem)、線性方程式和非建構性命題,讀懂IMO幾何題的比例從66%提升至88%。這版本的模型運算效率也大幅提升,透過C++重新實作符號處理機制,並最佳化規則集,讓推理過程更精確、高效率。
不過,目前模型仍有限制,比如無法處理變數點數(Variable Number of Points)、不等式與非線性方程式的幾何問題,且部分涉及投影幾何(Projective Geometry)與幾何反轉(Inversion)的問題,仍然超出系統現有能力範圍。(詳全文)
OpenAI GPT-4.5 o3
OpenAI揭露未來藍圖,將推GPT-4.5、整合o3產品線
OpenAI執行長Sam Altman日前在X上揭露OpenAI新藍圖,包括要推出GPT-4.5、整併產品線。Altman說明,OpenAI接下來將推出工程代號Orion的GPT-4.5,也是最後一個非思維鏈的模型。之後,o系列和GPT系列模型將整併為一套系統,能使用OpenAI所有工具,知道何時要啟用長時間思考、何時不用,且能執行多種任務。
在下一階段,OpenAI將推出GPT-5,這個模型將提供語音、工作區(Canvas)、深度研究等新能力,並會整合包括o3在內的多項技術,未來不會再單獨推出o3服務。這個GPT-5也會部署到ChatGPT和API中,免費版本的ChatGPT用戶可在標準設定中無上限使用,但仍受到防範濫用的節流閥控管。Plus用戶將能在GPT-5中以高思維等級執行任務。Pro方案則可獲得更高等級思維能力。(詳全文)
DeepSeek R1 自由鋼普拉 開源
臺灣AI專家發起DeepSeek R1改造計畫
DeepSeek R1模型的推出,受到全球AI社群關注,因其論文揭露多項媲美甚至超越OpenAI o1的推理能力,也因為可部署到本地端,來避免企業自己的機敏資料上傳到網路,而引起AI圈重視。但R1模型簡體版用戶協議中提到,自己通過三項中國AI法規的備案,也讓外界擔心這款模型生成的內容偏重於對齊中國價值。
因此,臺灣有三位不同AI領域的專家,發起了「自由鋼普拉」計畫(FreedomGunpla R1),來重新改造DeepSeek R1、打造對齊多元價值的繁體中文版推理模型,預計3月底釋出第一版模型。這三位發起人,包括AI助理新創MeetAndy AI創辦人薛良斌、Taiwan LLM開發者林彥廷以及雲端遊戲軟體開發供應商Ubitus的執行長郭榮昌。
這項計畫將以DeepSeek R1為基礎來改造,透過重新訓練模型的方式,並以開源授權釋出模型權重,最後還會打造新的模型身份與品牌。發起人預計分三階段實現目標,第一階段先對齊西方價值觀,但可能導致模型推理能力下滑,第二階段再進一步讓變笨的模型變得聰明,需投入更多資源來驗證。這項計畫的終極目標是,不論使用者用繁體中文或英文,這款模型的表現可以比使用簡體中文更好。(詳全文)
微軟 漏洞懸賞 Copilot
微軟加碼AI機器人Copilot的漏洞懸賞專案
為強化AI安全,微軟宣布調整AI機器人Copilot的漏洞懸賞專案內容,擴大挖掘漏洞的範圍,並提高部分漏洞的獎金額度。原本,這項漏洞懸賞專案的抓漏範圍,是針對Windows作業系統和Edge整合的Copilot應用程式、與搜尋引擎Bing整合的生成式搜尋功能,以及行動裝置版Copilot應用程式,這次微軟擴大範圍,納入即時通訊軟體Telegram、WhatsApp上的Copilot機器人,以及Copilot網頁版copilot.microsoft.com、copilot.ai。
微軟擴大範圍的原因是,中度風險的弱點也可能對Copilot的安全性和可靠性,產生嚴重影響,因此他們也將這類層級的漏洞獎金上限增加為5千美元,來鼓勵AI資安研究人員通報相關漏洞。(詳全文)
Hugging Face 智慧代理 Deep Research
挑戰OpenAI Deep Research,AI社群打造開源智慧代理系統
Hugging Face發起一項挑戰,在24小時內重現OpenAI最新發表的Deep Research系統,並開源其關鍵技術。OpenAI在2月初推出Deep Research,結合大型語言模型與代理框架,能透過網頁瀏覽、資訊整理和多步推理來回答複雜問題。它之所以備受矚目,在於其GAIA基準測試表現大幅超越純語言模型的AI系統,單次提示作答準確率達到67%。
為重現這個技術,Hugging Face在24小時內打造出第一個版本,以自家開發的smolagents框架為基礎,搭配大型語言模型來執行搜尋、資訊整理與多步推理。這個系統能夠自主規畫解題流程,決定何時查詢額外資訊,並以程式碼的方式表達執行步驟。相較於OpenAI未公開的技術,這項開源專案強調模組化設計,允許開發者選擇不同的語言模型,並且結合使用其他開源工具。
特別的是,Hugging Face的團隊選擇使用CodeAgent技術來提升代理系統的效率。相較於常用的JSON格式,改用程式碼來表達執行步驟,推理過程更精簡,並減少API呼叫次數。據團隊測試結果,改用CodeAgent後,代理系統在GAIA測試中的表現從46%提升至55.15%。此外,與JSON格式相比,使用Python來描述行動流程也能更直覺地表達邏輯關係,讓代理系統能夠有效處理多步推理問題。不過,這項開源計畫仍是初期階段,完整實作OpenAI Deep Research功能,仍有許多挑戰,特別是在瀏覽器操作方面。(詳全文)
圖片來源/Nvidia
AI近期新聞
1. Perplexity AI推出上網研究工具Deep Research免費版
2. 字節跳動發布影片生成模型Goku
資料來源:iThome整理,2025年2月
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10

2026-02-06


2026-02-10