聯發創新基地
聯發創新基地(MediaTek Research)日前一口氣釋出2款繁中多模態語言模型Llama-Breeze2-3B和Llama-Breeze2-8B,可分別在手機和電腦上執行AI助理任務,不只能處理文字工作,還懂看圖、調用外部工具。他們還開源以3B模型為基礎、可離線工作的Android聊天機器人App,鼓勵開發者延伸開發,甚至也釋出一款可合成臺灣口音的語音生成模型BreezyVoice。
要讓模型更懂繁中文字和圖片知識,還要讓AI生成臺灣口音的語音,需要哪些技術和資料?iThome專訪聯發創新基地開發團隊,來分享這些模型背後的關鍵技術。
關鍵1:採LLaVA架構
聯發創新基地團隊表示,大約去年4、5月,他們就著手打造Llama-Breeze2系列模型。也因為目標是多模態模型,除了懂文字,還要能看圖、知道呼叫函式(Function calling)來調用外部工具。因此,團隊採用熱門的多模態模型LLaVA架構,來開發Breeze2。
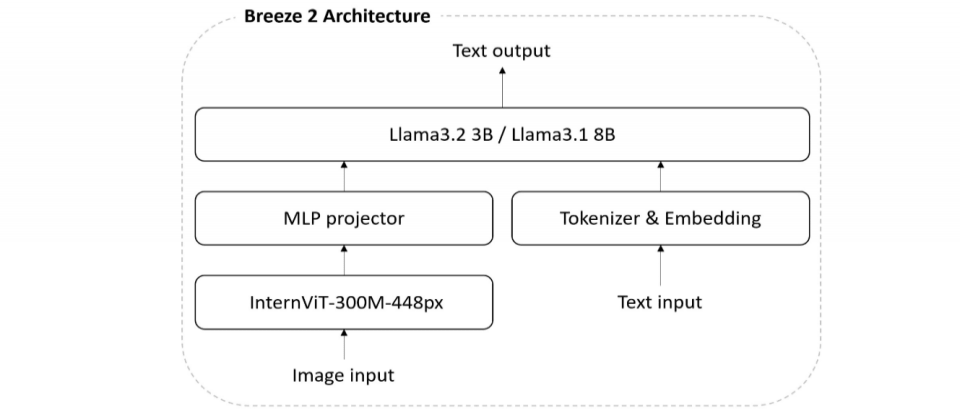
進一步來說,LLaVA架構由視覺編碼器(Vision Transformer,簡稱ViT)、多層感知器(MLP)和大型語言模型(LLM)組成。它們互相搭配,由ViT處理圖像,將圖像切分成一塊塊的圖像塊(Patch),再轉換為向量。接著由MLP擔任橋樑,將ViT產出的視覺特徵轉換為LLM可理解的格式,最後交由LLM產出回答。
在這個ViT-MLP-LLM架構下,Llama-Breeze2-3B就由InternViT-300M-448px、MLP、Llama 3.2-3B組成,Llama-Breeze2-8B一樣有InternViT-300M-448px、MLP,只是最後的LLM為Llama 3.1 8B模型。(如下圖)

關鍵2:繁中優化
要讓模型理解繁中知識,就得靠繁中資料加強模型的理解力。
這個加強之處,在於模型的預訓練(Pretraining)和後訓練(Post-training)兩階段。
其中,預訓練又可分為延伸文字預訓練、視覺對齊預訓練,前者主要用收集到的繁中資料,來加強Llama 3.2 3B和Llama 3.1 8B基礎模型的繁中知識理解力,後者則加強ViT模型和MLP對繁中圖文內容的理解力。
再來,後訓練則靠3件事來優化模型繁中能力,包括文字指令調校、視覺指令調校和函式呼叫微調。文字指令調校是要讓模型更理解繁中環境下的文字指令,視覺指令調校則是要模型更理解臺灣相關的圖文任務,比如解讀臺灣街景、招牌或繁體字排版。至於函式呼叫微調,則是要模型學會何時需要呼叫函式、要調用哪些功能,而且要能理解繁中語境。
關鍵3:大量在地化資料
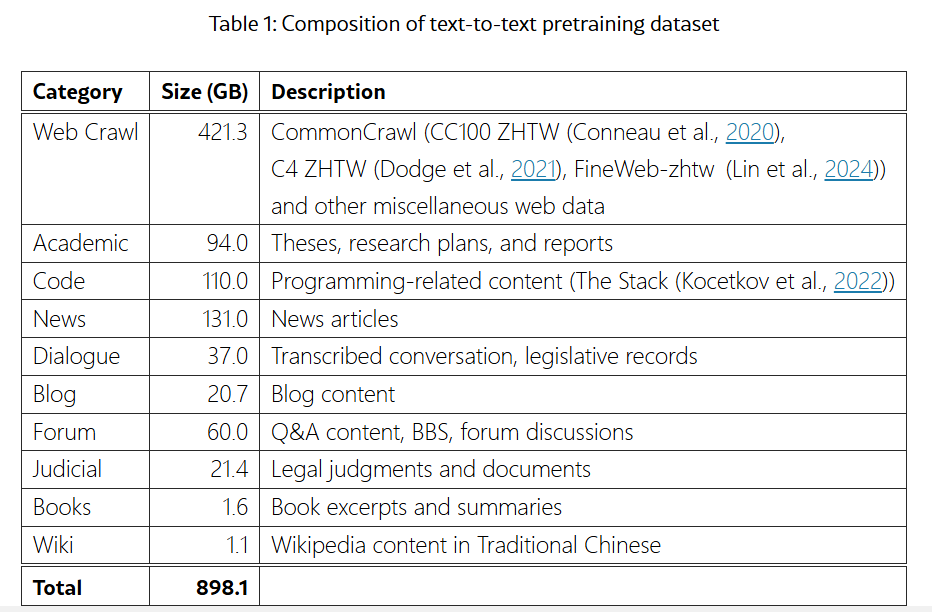
接著是影響模型學習的繁中資料集建置,首先,團隊收集了近1TB的繁中文字資料、共超過9,000億個Token(如下圖)。為確保這些資料可用,他們以開源過濾器加上自建的規則,來清理資料,尤其是身份證字號、電話等個資部分,都準確清除。這是文字資料的準備。
圖片訓練資料部分,團隊以英文的開源資料為主要訓練資料,但為了讓模型看到圖片後、能給出符合臺灣語境的回答,他們自己也翻譯了部分問答資料,並加入臺灣的習慣用語,讓模型回答能更貼近在地文化。
團隊強調,雖然訓練資料量大,但為保留原本Llama 3.1和Llama 3.2模型的優點,他們採取低學習率(Learning rate)方式來訓練模型。就好比要模型讀一本厚書,高學習率要求模型快速背完,低學習率則是按部就班進行。
關鍵4:函式呼叫判斷機制
至於函式呼叫,聯發創新基地團隊也有幾招來強化模型能力。
首先是導入模型的判斷機制,也就是在回答問題前,先判斷該不該呼叫函式,以及該呼叫什麼函式。這個判斷機制叫做Decision Token,是團隊先前提出的概念,它能在模型回答問題前,強迫模型先下決策,要使用工具(呼叫函式),還是不用工具、直接回答。
這個Decision Token機制,還能加強模型對工具使用的判斷力。因為,模型得靠函式呼叫資料和非函式呼叫資料訓練,才能學習使用工具的判斷邏輯,但傳統上,這種非函式呼叫的資料(又稱為反向資料)很難收集。於是,團隊透過Decision Token,在函式資料集中,將原本模型判斷需要呼叫的特定函式拿掉,這樣模型就會生成不呼叫函式的答案,就能快速產出非函式呼叫的訓練資料。
接著,團隊就能在模型訓練過程中加入這些資料,讓模型學習在哪些情境不需要呼叫函式,進一步避免不必要的函式呼叫,加強模型使用工具的判斷力。
不只Decision Token,團隊還特別打造一套翻譯流程,來將工具使用的資料,翻譯為繁體中文,加強模型呼叫函式的繁中能力。這是因為,他們採用開源的函式呼叫資料集來訓練模型,但這些資料9成都是英文,若只用英文資料,就會影響模型後續行為。比如,使用者詢問模型,臺北天氣如何,模型呼叫函式、調用外部工具取得的答案,可能會顯示Taipei,而非臺北。
因此,聯發創新基地團隊自建一套合成資料的翻譯處理流程,就像是一臺翻譯機,能翻譯任何語言(包括繁中),來解決語言在地化問題。
關鍵5:根據上下文準確分辨讀音
不只是文字、圖像,團隊也打造出符合臺灣口音的語音合成模型BreezyVoice,背後有個重要關鍵,也就是讓模型準確分辨破音字的G2PW套件。
簡單來說,BreezyVoice是以既有的CosyVoice語音合成模型改良而成。這套模型的運作原理是,輸入語音樣本,模型將聲音轉換為符元(Token),這些符元帶有能生成原本聲音的資訊,所以有了這些符元,就能根據文字,來將符元轉回音訊,達到文字生成語音的效果。
不過,這個CosyVoice的中文語音帶有中國大陸口音,為能貼近臺灣口音,團隊採用臺灣口音的語音資料來改善模型發音,也以G2PW來讓模型發音更正確。這個G2PW是一款團隊開發的開源套件,是BERT衍生模型,能很好地理解上下文、決定讀音,尤其是破音字。
時下熱門的推理模型也在研究中
開源多款輕量級語言模型之餘,聯發創新基地團隊表示,他們也一直在研究不同層面的AI技術,像是近期廣受討論的測試階段運算擴展(Test-time computing)方法。有別於傳統的擴展法則、在模型訓練階段加入大量運算資源和資料,測試階段運算擴展方法是在模型部署後的推論階段,加強算力,讓模型處理複雜問題時,能多思考幾步,著名的例子有OpenAI的o系列推理模型、DeepSeek R1和Google Gemini 2.0 Flash Thinking等。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-09

2026-02-06

2026-02-09