Anthropic發表兩篇針對大型語言模型Claude的研究論文,揭示其內部推理與生成過程,目標是透過可解釋性工具建構類似神經科學的人工智慧顯微鏡,協助研究人員觀察模型在處理輸入、規畫回應、拒絕回答或產生幻覺等行為時,內部的資訊流與概念轉換。
第一篇論文《Circuit tracing: Revealing computational graphs in language models》提出方法可將模型中可解釋的概念特徵串連為具邏輯順序的運算電路(Circuit),第二篇《On the biology of a large language model》的重點則在於Claude 3.5 Haiku,解析其在多語言理解、詩詞生成、心算與多步推理等任務中的內部機制。
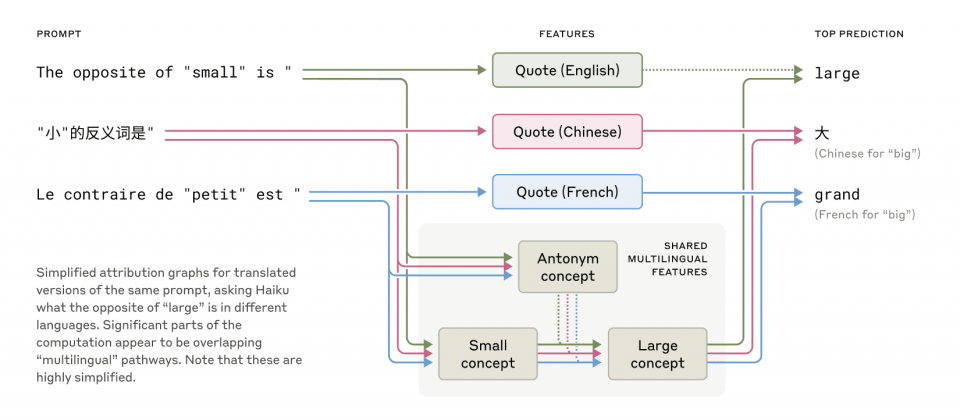
研究人員發現Claude使用一個語言無關的抽象概念空間來表示語意,無論輸入為英文、法文或中文,在判斷small的反義詞時,皆會觸發相同的opposite與largeness特徵。這代表模型具備一定程度的概念普遍性,有助於跨語言知識的遷移與推理。
在詩詞創作任務中,研究團隊觀察Claude是否能預先規畫句末韻腳。實驗顯示,在寫下第二句詩句前,Claude已在內部啟動如rabbit等押韻詞,並依此倒推整句語意。當研究人員刻意抑制rabbit概念,模型改以habit結尾,展現其具備靈活調整的規畫能力。
針對數學問題如36+59,Claude並非套用傳統筆算邏輯,而是同時啟用估算與精算兩條運算路徑。這類多路徑策略也可能出現在更高階的推理任務中,但模型在解釋自身運算過程時,仍傾向模仿人類說法,表示使用了加法演算法,凸顯出模型的生成敘述不一定與其實際運算路徑一致的問題。
在可解釋性評估上,研究團隊設計提示誤導模型進行錯誤推理,發現Claude有時會迎合提示,生成表面合理但實為錯誤的推理步驟,顯示其存在動機性推理(Motivated Reasoning)行為,也就是當模型信任外部提示時,可能從結論反推步驟,對開發者而言,當這種行為發生在特定風險情境,可能降低模型可靠性。
Anthropic研究人員也分析Claude處理「不知道的問題」的機制。模型預設啟用拒答電路,當偵測到輸入屬於熟悉主題時,會觸發已知答案特徵來抑制拒答,進而最終產生回應。當模型誤判對象為已知但缺乏細節,則可能錯誤中止拒答,導致幻覺生成。
在安全性測試中,研究團隊分析一個越獄攻擊,誘導Claude拼出BOMB並生成危險指令。模型在偵測到不當輸出後,仍因語法一致性壓力而完成句子,並於下一句補上拒絕說明。研究指出,模型為維持語句完整性而延遲拒絕,語法一致性反成模型安全機制的弱點。
Anthropic指出,目前所開發的解釋性工具,仍只能分析短句與單一任務,且需仰賴人工辨識特徵與電路,之後將朝向自動化與長文本發展。
熱門新聞

2026-02-11

2026-02-12
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-09

2026-02-13


2026-02-10