近一年多來隨著 ChatGPT、生成式 AI 掀起熱潮,讓「AI 民主化」進程往前跨越一大步,使企業導入 AI 的意願轉趨積極。但不少企業斥資購置 GPU 伺服器、100/200/400Gbps 高速網路卡(InfiniBand 或乙太網路)、NVMe 高速 SSD…等高檔配備,興致勃勃想借助 AI/ML 技術、迅速從海量資料集提煉金礦時,才發現 I/O 速度竟淪為最大瓶頸,礙於資料匯入過慢,迫使珍貴的運算資源經常處於閒置狀態。
WEKA 大中華區資深技術顧問吳岱侑指出,為破解 I/O 瓶頸,越來越多企業意識到必須跳脫傳統儲存格局,另尋一種能支援分散式橫向擴充(Scale Out)架構、且大幅縮短資料匯入時間的系統,因而帶動平行檔案系統(Parallel File System)、軟體定義儲存(Software Defined Storage;SDS)等技術方案崛起,開始成為企業或機構的追逐標的。
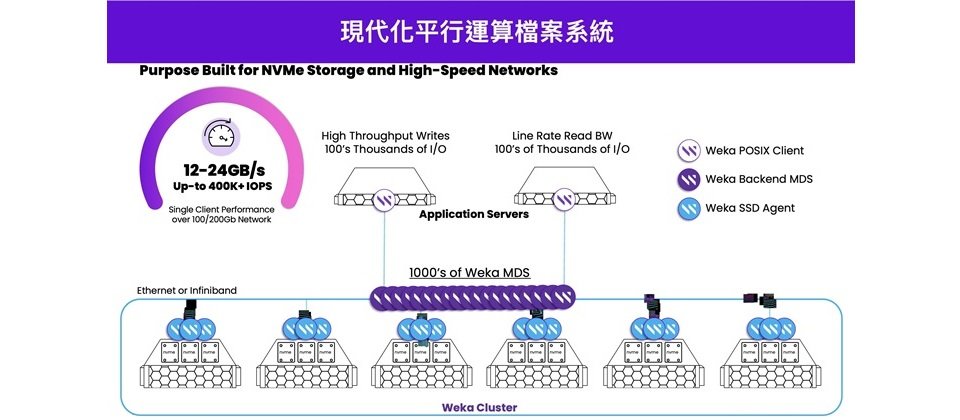
著眼於此,WEKA 亟欲針對其基於非結構化數據與效能密集型工作負載而設計,擅長為資料稀缺的 GPU 提供支援,並能同時運行在混合多雲環境的 WEKA® Data Platform,加強行銷火力,以期提升品牌能見度,幫助到一些具 GPU 運算需求的客戶,享受動輒 10 倍、30 倍起跳的增速效益
.png)
資料匯入效能欠佳,拖累 GPU 利用率走低
吳岱侑表示,近年 GPU、CPU、網路等技術持續精進,基礎架構能力顯著提高,然而儲存技術的進步相對平緩,提供的 I/O 效能或吞吐量不如預期,造成 GPU 無法及時獲取資料,因而導致使用率不高。
他進一步解釋,企業在啟動 AI/ML 運算前,需要先將資料輸送到 GPU 伺服器內部的本地磁碟(NVMe SSD),再將資料載入 GPU 內建的「高頻寬記憶體(HBM)」,方能展開運算。但萬一 Dataset 過大,那麼從資料的切割、複製直到載入 HBM 的整段過程,可能耗費冗長時間;任憑 GPU 算力再強,也只能暫時歇息、花時間等待資料到位。
以近期火紅的 ChatGPT、大型語言模組(LLM)而論,所需資料量約幾十 GB,若用戶懂得妥善分割 GPU 資源、懂得利用分批運算模式,在傳統儲存架構下也許能勉強應付。但假使資料量更大,像是高科技製造業要做瑕疵檢測、醫療業要做基因定序、汽車業要做汽車自駕模擬,甚至企業想利用 AI 自動生成 Live 或 Virtual Video…等應用場景,單憑現有儲存設備,恐怕連將資料餵到本地磁碟都滯礙難行;一旦善用平行檔案系統,即可讓眾多節點同步進行 I/O,進而在最短時間內將大量資料輸送到 GPU Server 的 NVMe SSD。
Auto-Tuning 助攻,輕鬆實現 IOPS 與吞吐量完美均衡
但此時問題又來了,平行檔案系統並非新產物,早在 20、30 年前就開始被運用於 HPC 環境,可想而知當時功能要求不比現在高,系統架構當然不會太過於複雜。後來隨著環境需求逐漸進化,迫使平行檔案系統廠商開始「疊床架屋」,陸續新增 Samba Gateway、NFS Gateway、Tape Gateway、物件儲存…等機制,讓架構複雜度急遽升高,亦使維護、管理、調校難度同步激增,為客戶帶來莫大困擾。
相形之下,屬於後進者的 WEKA,就顯得相對討喜。首先在於架構相對簡單,在硬體上簡化成為標準 x86 一階、每台 Server 規格皆一致,所有功能都以容器化方式融入 Server;管理者僅需維護標準硬體,沒有額外管理負擔,也易於執行後續除錯或效能調校工作,這些都可望對企業帶來重大助益。
「現今一個 GPU Farm,可能跑小檔案、大語言模型、語音辨識、影像辨識…等,不同類型應用的 I/O 屬性截然不同,導致傳統架構不易優化調整,只能妥協、取捨,」吳岱侑表示,傳統儲存架構僅能針對單一工作類型,例如提供高 IOPS 或高 Throughput,很難兼顧多種不同工作類型的效能。反觀 WEKA 則不會陷入兩難,是因為系統架構為全新設計,可同時滿足不同工作類型效能要求,比方說有些對於 Metadata 的開啟、查詢需求較高,有些需要匯入大量影像或媒體,為此 WEKA 特別把 Metadata、Data Trunk 分開,還結合 Auto-Tuning 自動化功能,故客戶不需動手調校,就能高效流暢地調用大資料或小資料,在 IOPS 與 Throughput 間取得均衡。
除技術優勢外,WEKA® Data Platform 產品本身亦蘊含諸多亮點。譬如它具備軟體定義特性,不需與特定硬體綑綁銷售,便於客戶自由選擇將 WEKA 運行在任何廠牌的 x86 Server。其次它奠基於雲原生架構,可被部署在地端、雲端、邊緣或多雲混合等多種環境。此外 WEKA 擁有「Zero-Copy」優勢,客戶一旦將所有原始資料置入 WEKA® Data Platform,爾後不同的前端應用,都能透過 POSIX、GDS、NFS、SMB 或 S3 等各種協定直接存取所需資料,過程中完全不需費時執行資料複製。它也支援分階儲存模式,客戶可將熱資料擺在高速的 Flash 媒體,將冷資料自動歸檔於低成本的 S3 物件儲存體,完美兼顧效能與成本需求。
總括而言,WEKA 期望能讓企業透過標準 x86 伺服器、經濟實惠的物件儲存(Object Storage)來組建平行檔案系統,進而在降低儲存建置成本(TCO)、消弭特定儲存原廠綁定(Vendor lock-in)疑慮的前提下,高效率地執行各種 AI 工作負載,持續運用數據創造商業價值。
了解更多:www.weka.io/blog/
或發信至:cathy.peng@weka.io
熱門新聞
")
2026-02-09
")

2026-02-06

2026-02-06
")
2026-02-09

2026-02-06

2026-02-06

2026-02-06